







一点搜广推的小知识
搜广推,解决的核心问题是信息过载,在海量的数据中,信息中做大海捞针的事情。
我自己的真是感受,搜索要分为不同的领域。 电商、视频、内容搜索是完全不同的,它们的特征差异很大。知识搜索(或者说问答搜索)又是完全区别于电商和视频的。知识搜索更加关注的是对或者不对,又或者说有或者没有。
推荐和搜索的思路是相近的。都是召回,粗排,精排,重拍。通常从粗排就开始使用一些模型了。而模型通常更多的是需要特征的构建。
视频推荐的四方博弈
1.用户:找到优质的兴趣视频
2.创作者:内容有被点击,关注
3.平台方:用户+活跃程度、广告商
4.广告方:投放,获客,高转化比。
内容审核
违规内容(图片、文字、视频)
做法:NLP做文本分类,敏感词
链路:
1.内容做分类
2.标签抽取,提取关键词
3.内容的向量化
4.item的生命周期
5.初始流量预测
技术实现
召回:最核心的是快速召回(要从海量的内容池中筛选,速度慢,撑不住),可以漏但是要少漏。
排序:排序要准,可以慢(已经拿到了极少量的内容)。
策略排序:避免同质化的内容,将少量的内容打散
评价指标
CTR 点击率 和平均点击率
对于视频来说:完播率
评估一件事的特征
用户使用日志
召回
关键词召回
Bm25相关性召回
CF协同过滤
使用用户海量的用户行为,找到相同的特征。还有数据的共同特征,去做策略
数据的协同过滤:找到数据的共同特征。例如数据3和数据1、2相似。那么用户在看了1和2,且喜欢1和2,则可以把3也推给用户。
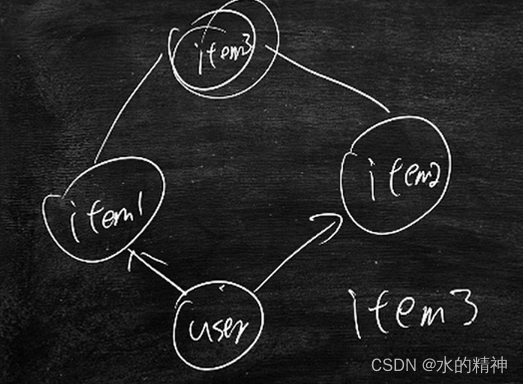
例如:用户的协同过滤,如果用户1和用户2的行为相似。那么可以把用户1喜欢看的,推给用户2
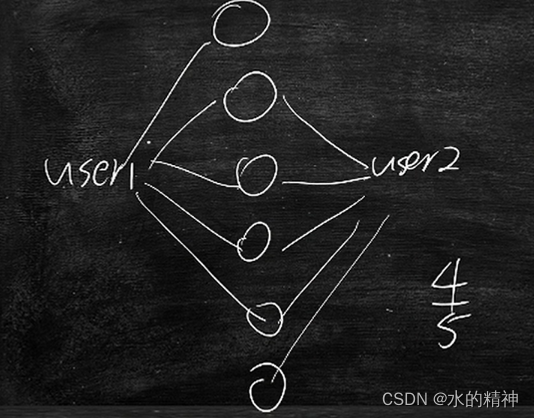
DSSM召回模型
双塔模型,针对的用户偏好,训练一个模型。针对内容池训练一个模型。分别用来获得用户的embedding和内容的embedding
其中数据就来自于用户的行为数据。从用户的点击日志中,很容易得到用户的喜欢哪些和不喜欢哪些。
多路召回的融合
例如有5路召回(BM25 向量 等等)。每路召回10条数据。有的数据可能在多路都召回了,那其实就对该文档的排序进行加分。
定义一个综合积分规则。
排序
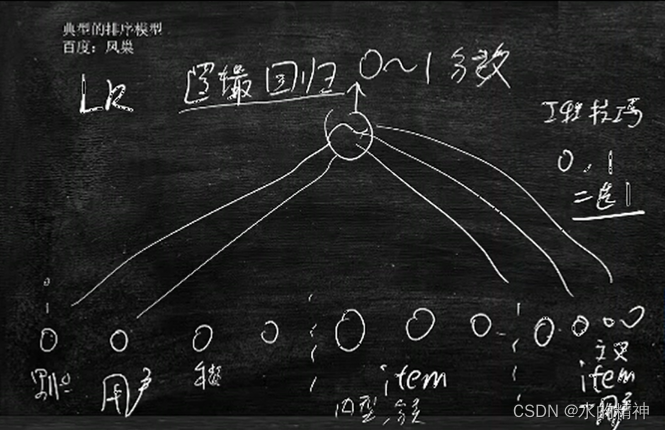
最典型的排序模型——LR
主要做的就是,整理用户的特征,和商品的特征。最后用来做排序
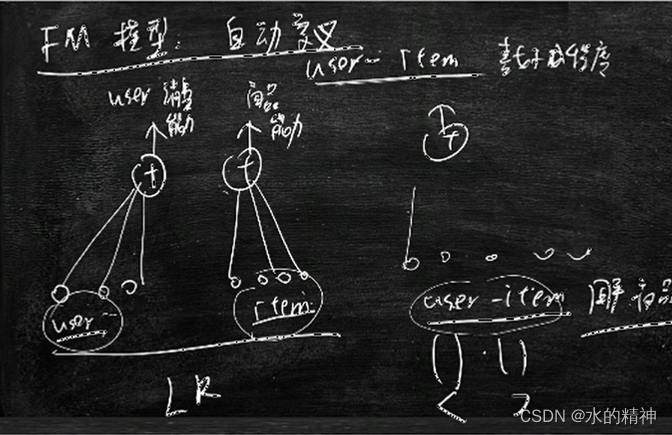
FM模型
自动交叉特征,只能做2维特征的组合。
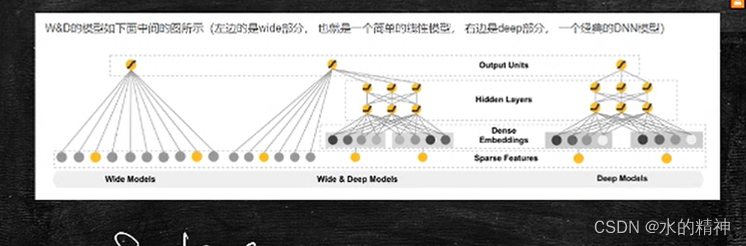
wide && deep
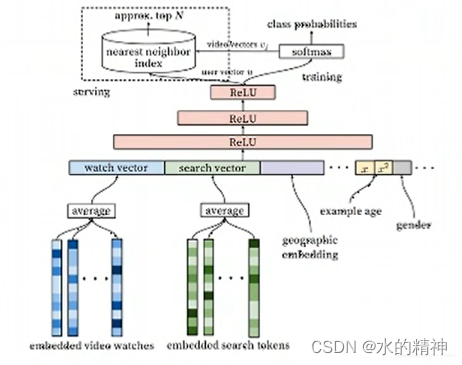
youtubeDNN
可以用来做排序,可以用来做召回。如下图所示,简单来说,是把多个维度的特征,做融合,最后得到一个向量、

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









