







 本次实验基于自建CNN网络实现眼睛状态分类,未采用效果差、速度慢的VGG16迁移学习。数据加载未进行数据增强,避免引入噪声。搭建的CNN网络在epochs=20时准确率达93%。重点介绍了混淆矩阵的绘制,它用于比较分类结果和实际值。
本次实验基于自建CNN网络实现眼睛状态分类,未采用效果差、速度慢的VGG16迁移学习。数据加载未进行数据增强,避免引入噪声。搭建的CNN网络在epochs=20时准确率达93%。重点介绍了混淆矩阵的绘制,它用于比较分类结果和实际值。
本次实验基于自己搭建的CNN网络实现眼睛状态的分类,本来是打算迁移学习利用VGG16网络进行分类的,但是实验效果特别差,而且速度很慢,应该是博主自己的问题。而自己搭建的CNN网络的模型准确率也很高,运行速度很快。本文的重点在于混淆矩阵的绘制,这是之前没有接触过的东西。
1.导入库
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os,pathlib,PIL
from tensorflow import keras
from tensorflow.keras import layers,models,Sequential
2.数据加载
数据所在文件路径
data_dir = "E:/tmp/.keras/datasets/Eye_photos"
data_dir = pathlib.Path(data_dir)
img_count = len(list(data_dir.glob('*/*.jpg')))#图片总数
超参数的设置
height = 224
width = 224
epochs = 10
batch_size = 64
构建一个ImageDataGenerator,在之前的实验中,我通常在这一步会进行数据加强,包括左右翻转、图片翻转某个角度,水平翻转等。但是在本次实验中,并没有进行这一操作。因为本次识别的眼睛状态包括左看、右看、前看、闭眼四种状态,如果进行数据增强的话,左看变为右看,这样数据没有达到增强的效果,反而引入噪声数据,得不偿失。
train_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
validation_split=0.2)#以8:2的比例划分为训练集和测试集
分为训练集和测试集
train_ds = train_data_gen.flow_from_directory(
directory=data_dir,
target_size=(height,width),
batch_size=batch_size,
shuffle=True,
class_mode='categorical',
subset='training'
)
test_ds = train_data_gen.flow_from_directory(
directory=data_dir,
target_size=(height,width),
batch_size=batch_size,
shuffle=True,
class_mode='categorical',
subset='validation'
)
Found 3448 images belonging to 4 classes.
Found 859 images belonging to 4 classes.
查看标签
all_images_paths = list(data_dir.glob('*'))##”*”匹配0个或多个字符
all_images_paths = [str(path) for path in all_images_paths]
all_label_names = [path.split("\\")[5].split(".")[0] for path in all_images_paths]
['close_look', 'forward_look', 'left_look', 'right_look']
3.CNN网络搭建
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,3,padding="same",activation="relu",input_shape=(height,width,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32,3,padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024,activation="relu"),
tf.keras.layers.Dense(512,activation="relu"),
tf.keras.layers.Dense(4,activation="softmax")
])
优化器的设置,具体的原理可以参考车牌识别那篇博客。
initial_learning_rate = 1e-4
lr_sch = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=initial_learning_rate,
decay_rate=0.96,
decay_steps=20,
staircase=True
)
计算loss值的方式我在上篇博客中讲述了。
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=lr_sch),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy']
)
history = model.fit(
train_ds,
validation_data=test_ds,
epochs=epochs
)
结果如下所示:
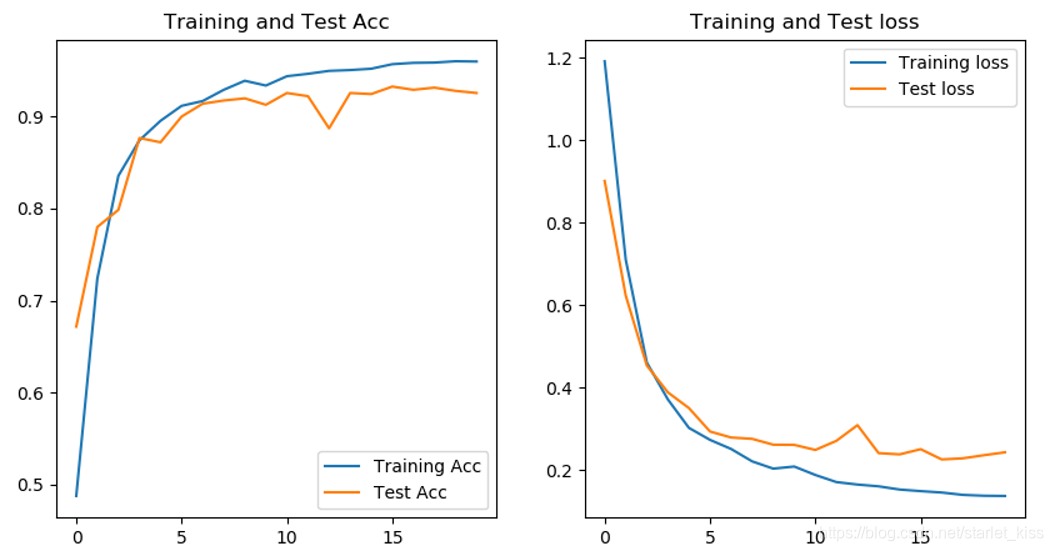
在epochs=20的情况下,模型的准确率在93%左右,比较可观。
保存模型:
model.save("E:/tmp/.keras/datasets/model.h5")
加载模型
new_model = tf.keras.models.load_model("E:/tmp/.keras/datasets/model.h5")
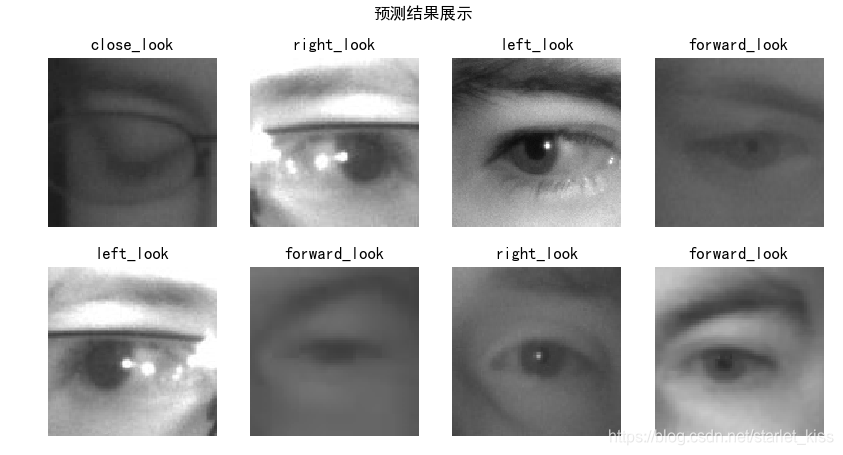
利用模型对图片进行预测:
plt.figure(figsize=(10,5))
plt.suptitle("预测结果展示")
for images,labels in test_ds:
for i in range(8):
ax = plt.subplot(2,4,i+1)
plt.imshow(images[i])
img_array = tf.expand_dims(images[i],0)#增加一维
pre = new_model.predict(img_array)
plt.title(all_label_names[np.argmax(pre)])
plt.axis("off")
break
plt.show()
4.混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
我们最熟悉的混淆矩阵就是二分类的混淆矩阵:
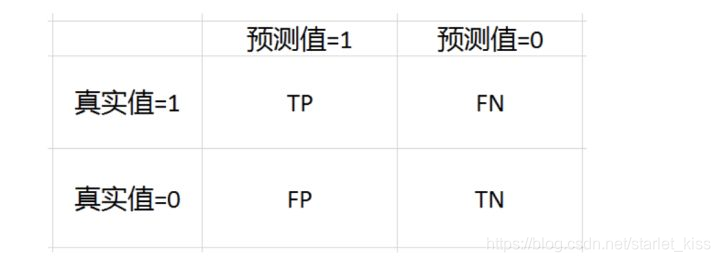
TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
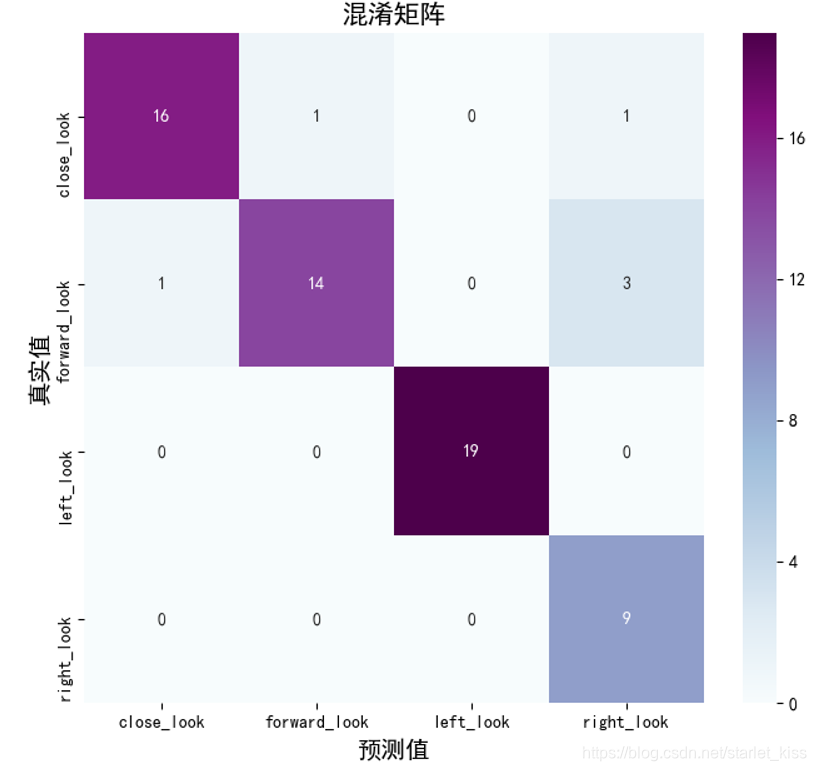
至于多分类的混淆矩阵,与二分类的混淆矩阵相差不多。我们来绘制眼睛状态识别的混淆矩阵。
sns.heatmap是用来绘制混淆矩阵的主要工具,这是seaborn包下面的一个方法,具体如下:
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
其实除了第一个参数data外,其余的参数都是缺省参数,可以不用管。这里的data,如果接收的是干干净净的numpy二维数组的话,可以看到行标就是0,1,2,如果是DataFrame,就可以用列名来标记了。
所需要的库
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
定义一个绘制混淆矩阵的函数
#绘制混淆矩阵
def plot_cm(labels,pre):
conf_numpy = confusion_matrix(labels,pre)#根据实际值和预测值绘制混淆矩阵
conf_df = pd.DataFrame(conf_numpy,index=all_label_names,columns=all_label_names)#将data和all_label_names制成DataFrame
plt.figure(figsize=(8,7))
sns.heatmap(conf_df,annot=True,fmt="d",cmap="BuPu")#将data绘制为混淆矩阵
plt.title('混淆矩阵',fontsize = 15)
plt.ylabel('真实值',fontsize = 14)
plt.xlabel('预测值',fontsize = 14)
plt.show()
得到预测值与实际值
test_pre = []
test_label = []
for images,labels in test_ds:
for image,label in zip(images,labels):
img_array = tf.expand_dims(image,0)#增加一共维度
pre = new_model.predict(img_array)#预测结果
test_pre.append(all_label_names[np.argmax(pre)])#将预测结果传入列表
test_label.append(all_label_names[np.argmax(label)])#将真实结果传入列表
break#由于硬件问题。这里我只用了一个batch,一共64张图片。
plot_cm(test_label,test_pre)#绘制混淆矩阵
努力加油a啊



















 8358
8358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











