






一、目的
对输入图像进行图像特征提取,并感受各种不同的特征对最终图像识别的影响。
二、原理
水果有位置、方向、周长、面积、矩形度、宽长比、球状性、圆形度、不变矩、偏心率等各种特征。对图像进行灰度化再经过二值化等处理可以得到图像中水果的轮廓,利用该轮廓可以求得各种特征,利用一些特征构造模型可以实现对水果种类的检测识别。
以下介绍python中使用opencv库进行图像处理的一些主要函数:
读入图像:cv2.imread(filepath,flags),显示图像:cv2.imshow(wname,img)
颜色空间转换:cv2.cvtColor(img,cv2.COLOR_X2Y)
二值化:cv2.threshold(src, thresh, maxval, type[, dst])
轮廓提取:cv2.findContours(contour,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
绘制轮廓:cv2.drawContours()
求取面积:cv2.contourArea(),求取周长:cv2.arcLength()
一些特征的计算过程如下:
矩形度:
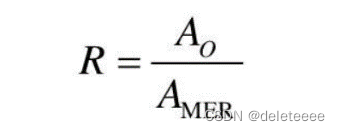 ,AO是该物体的面积,而AMER是其外接矩形的面积
,AO是该物体的面积,而AMER是其外接矩形的面积
球状性:
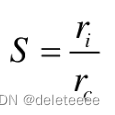 ,ri为最大内接圆半径,rc为最小外接圆半径
,ri为最大内接圆半径,rc为最小外接圆半径
圆形度:e=(4π 面积)/(周长 * 周长);
三、实现过程
1.数据集说明
数据集中包含苹果和香蕉两种水果,分别存放于对应的文件夹中


图1 部分数据集
2.提取特征
读入所有的水果图像,首先对它们做如下处理:转为灰度图像、二值化

处理前后图像如下:

图2 原图

图3 二值化图像
接下来提取二值图像的轮廓信息并进行绘制:

轮廓信息如下(部分):

图4 轮廓信息
处理后图片如下:

图5 边缘轮廓绘制
利用轮廓信息可以求得外接矩形,长宽,面积周长等信息
先利用库函数求得图像的外接矩形以及中心点位置:

结果如下:

图6 外接矩形及中心点
计算图像的各种特征:

结果如下:

图7 特征提取结果
得到上述特征后我选择宽长比、圆形度、矩形度以及矩形度作为训练的特征值。对所有的图片做如上所示相同的操作,将选取的三个特征存放在数组中,结果如下:
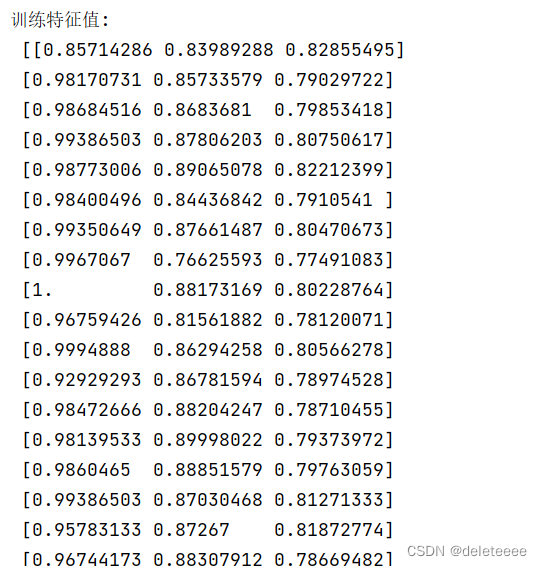
图8 训练集特征
设定训练集标签,0代表苹果,1代表香蕉:
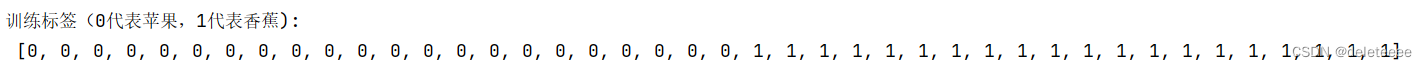
图9 训练集标签
通过python sklearn库可以构造svm分类器进行训练:
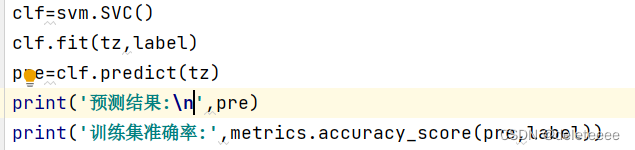
训练结果如下:

图10 训练结果
可以看出此时训练集准确率已经达到了100%
3.水果预测
选择训练集之外的苹果或者香蕉图像进行预测
载入测试图片与训练集做相同的操作,得到三种特征值,预测函数如下:

预测:

图11 测试1 苹果原图
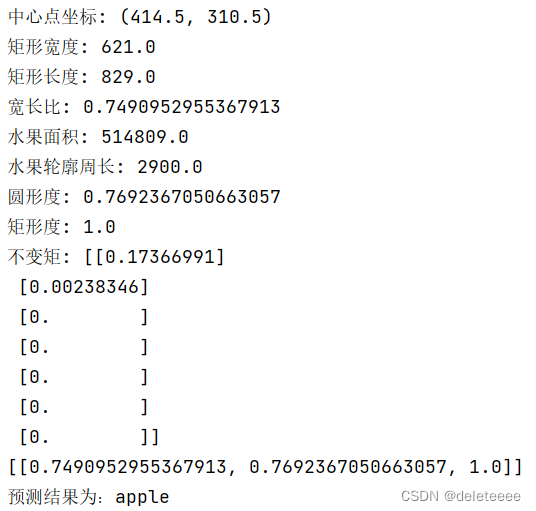
图12 测试结果1
此时观察到其宽长比似乎异常,查看其二值化及结果图片如下:

图13 异常结果1
可以看出结果错误的,发现是由于其阴影部分及背景部分的影响,训练集由于照片都是黑色背景所以处理方便,而对于额外随意的水果照片需要进行不同的处理才能准确分割出水果。

图14 测试2 苹果原图
修改二值化阈值,使其能够准确分割出水果图像:

图15 正确处理图像
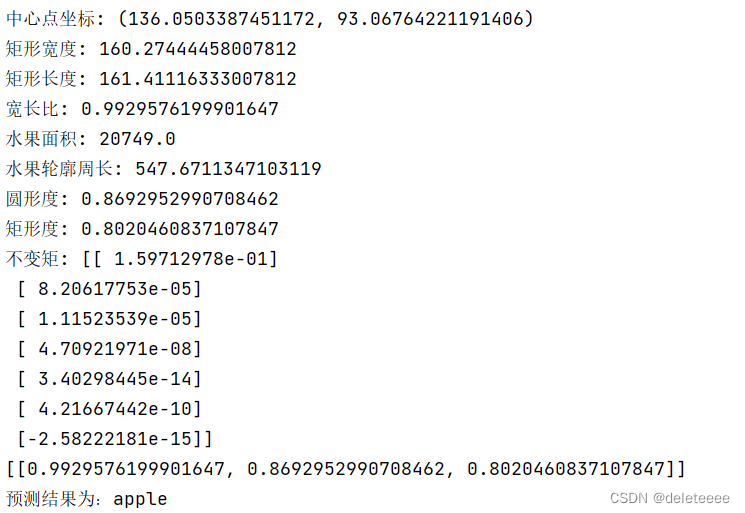
图16 测试结果2

图17 测试3 香蕉原图

图18 正确处理后

图19 测试结果3
四、完整代码
import numpy as np
import cv2
import matplotlib.pyplot as plt
import os
from sklearn import svm,metrics
file_path = 'img'
fru = [cla for cla in os.listdir(file_path) if '.txt' not in cla]
tz=[]
for cla in fru:
cla_path = file_path + '/' + cla + '/' # 某一类别动作的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
print(images)
for pic in images:
pic=cla_path+pic
img = cv2.imread(pic)
imgray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imgray, 8, 255, cv2.THRESH_BINARY)
kernel = np.ones((3, 3), dtype=np.uint8)
closing = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
image, contours, hierarchy = cv2.findContours(closing, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
area = []
for i in contours:
area.append(cv2.contourArea(i))
for i in contours:
if cv2.contourArea(i) == max(area):
rect = cv2.minAreaRect(i)
box = cv2.boxPoints(rect)
box = np.int0(box)
#cv2.drawContours(img, [box], 0, (0, 0, 255), 2) # 画矩形框
(x, y), radius = cv2.minEnclosingCircle(i)
center = (int(x), int(y))
radius = int(radius)
#cv2.circle(img, center, radius, (0, 255, 0), 2)
w = min(rect[1][0], rect[1][1]) # 宽度
h = max(rect[1][0], rect[1][1]) # 长度
wh=w/h
s = cv2.contourArea(i)#面积
l= cv2.arcLength(i, True)#周长
roundness = (4 * np.pi * s) / (l * l) # 圆形度
r=s/(w*h)#矩形度
tz.append([wh,roundness,r])
apple=[0 for i in range(22)]
banana=[1 for i in range(20)]
label=apple+banana
tz=np.array(tz)
print('训练特征值:\n',tz)
print('训练标签(0代表苹果,1代表香蕉):\n',label)
clf=svm.SVC()
clf.fit(tz,label)
pre=clf.predict(tz)
print('预测结果:\n',pre)
print('训练集准确率:',metrics.accuracy_score(pre,label))
#测试
img = cv2.imread('1.jpg')
imgray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imgray, 8, 255, cv2.THRESH_BINARY)
kernel = np.ones((3, 3), dtype=np.uint8)
closing = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
image, contours, hierarchy = cv2.findContours(closing, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
area=[]
test=[]
for i in contours:
area.append(cv2.contourArea(i))
for i in contours:
if cv2.contourArea(i)==max(area):
rect = cv2.minAreaRect(i)
box = cv2.boxPoints(rect)
box = np.int0(box)
cv2.drawContours(img,[box],0,(0,0,255),2) #画矩形框
print('中心点坐标:',rect[0])
cv2.circle(img,(int(rect[0][0]),int(rect[0][1])),7,128,-1)#绘制中心点
M=cv2.moments(i)
M = cv2.HuMoments(M) # 计算轮廓的Hu矩
w = min(rect[1][0],rect[1][1]) # 宽度
h = max(rect[1][0],rect[1][1]) # 长度
wh = w / h #宽长比
s = cv2.contourArea(i) # 面积
l = cv2.arcLength(i, True) # 周长
roundness = (4 * np.pi * s) / (l * l) # 圆形度
r = s / (w * h) # 矩形度
print('矩形宽度:',w)
print('矩形长度:',h)
print('宽长比:', wh)
print('水果面积:', s)
print('水果轮廓周长:', l)
print('圆形度:', roundness)
print('矩形度:', r)
print('不变矩:', M)
test.append([wh, roundness, r])
print(test)
str1 = '(' + str(int(rect[0][0]))+ ',' +str(int(rect[0][1])) +')' #把坐标转化为字符串
cv2.putText(img,str1,(int(rect[0][0])-80,int(rect[0][1])-30),cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),1,cv2.LINE_AA)
''' 绘图,如果想查看图片就取消注释
cv2.namedWindow("img", 0)
cv2.resizeWindow("img", 680, 480)
cv2.imshow("img",img)
cv2.waitKey()
cv2.destroyAllWindows()'''
def predict(x):
a=clf.predict(x)
if a[0]==0:
print('预测结果为:apple')
if a[0]==1:
print('预测结果为:banana')
predict(test)
五、讨论
在实验的过程中,选择合适的阈值可以成功将训练集中的水果图像切分出来,得到轮廓,利用轮廓可以得到一系列相应的特征,实验中选取其中的宽长比、圆形度和矩形度就已经足以区分出苹果和香蕉,苹果的这三个特征都明显远远大于香蕉。而在使用其余照片进行测试时需要注意在图像二值化时不能一概而论,因为不同的图片中背景、光影等信息可能也会差别很大,如果处理不当可能会导致错误的分割,这将会很大程度上影响结果。


















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











