






一、背景
随着我国法制建设不断健全,法规日趋完善,人们的法律意识也越来越强。当前,随着越来越多的法律文本公开,为犯罪案件审理这个方面的挖掘积累了大量的文本内容。因此,通过收集法律与犯罪领域文本,构建起司法领域语料库,使用自然语言处理技术进行挖掘,实现文本分类,并利用机器学习等技术实现对法律案件的预测具有重要意义。
文本分类算法,是计算机对文本集合按照事先定义好的类别体系进行自动分类标记的技术,它根据一个已经被标注的训练文档集合, 找到文档特征和文档类别之间的关系模型, 然后利用这种学习得到的关系模型对新的文档进行类别判断。文本分类是自然语言处理的核心问题之一,相关研究成果已广泛应用于各行各业的文本处理中。在司法领域主要用于罪名分类,特定犯罪情节识别等。文本分类算法的核心在于类别之间定义的区分度以及数据集内容对类别的敏感度。对于文本算法来说,提取足以区分类别间的特征相较于构建模型结构本身来说更为重要。
目前,文本分类的主流方式是采用机器学习方法(包括深度学习方法)。对于中文文本来说,其主要思想,先对文本进行分词,去停用词,在形成词典的基础上,对文本进行向量化,从而生成文本向量。然后,采用机器学习方法进行文本分类。
本项目旨在使用python语言,采用机器学习方法对大量刑事案件判决书进行学习的基础上,实现给定案情的案件可能的判决进行预测。
二、数据集介绍
给定的数据集有4098份刑事案件判决书,涵盖了刑法中规定的大多数罪名。对于数据集进行切分,以训练集:测试集等于9:1的方式进行随机切分,分别在data文件夹下建立train与test文件夹进行储存。

三、贝叶斯原理
对于最终选择的多项式朴素贝叶斯算法推导如下:
多项式分布应用到朴素贝叶斯上,对于文档分类问题来说,假设给定文档类型的基础上文档生成模型![]() 是一个多项式分布.这样对应关系就是:
是一个多项式分布.这样对应关系就是:
- 文档分类中的d维字典(d个特征)对应于多项式分布中的向量的d个维度;
- 文档分类中,词
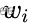 出现与否,对应于d维向量中
出现与否,对应于d维向量中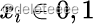 ,两种取值情况,且
,两种取值情况,且
- 文档分类中,词
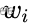 出现的概率,对应于离散分布中
出现的概率,对应于离散分布中 的概率是
的概率是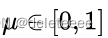 ,并且
,并且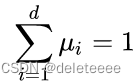 ;
; - 文档分类中,给定类别下,对应一次抽样结果x(d维向量)的概率为:
 ,因为如果一个词不出现,即
,因为如果一个词不出现,即 ,那么对应
,那么对应 ,所以
,所以 可以简写为
可以简写为 ;
; - n次独立实验中有ni词
 的概率,对应到文档模型中特征i(第i个词)出现了ni次,n次实验对应到文档模型中表示这篇文档的长度为n(一共有n个词),对应概率密度函数为:
的概率,对应到文档模型中特征i(第i个词)出现了ni次,n次实验对应到文档模型中表示这篇文档的长度为n(一共有n个词),对应概率密度函数为: 
我们知道一般的多项式条件概率如下:
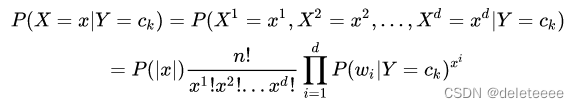
利用贝叶斯公式,用于文档分类中的多项式朴素贝叶斯模型为:
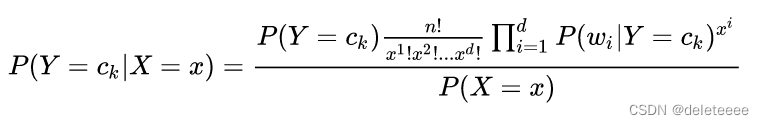
四、样本处理
4.1 文本处理
对数据集中的判决书文档进行格式转换,统一转换为TXT文本格式便于处理。通过对判决书中的内容分析可以发现,绝大多数判决书中在类似于“经审理查明”这样的字段后面是对于案情经过的具体描述,而在这之前的文本有的是一些对于判决结果无意义的描述,有的是对于法院进行多次审理的描述,还有一些是对于被告人态度的描述,但是这样一些描述对于大多数案件中最终罪名的预测并无太大影响,因此在本项目的处理中被忽略。同样通过分析可以发现,判决书中关于最终罪名的给定主要都是在类似于“判决如下”这样的字段之后。由此,可以选择将类似与“审理查明”字段与“判决如下”字段之间的文本作为判决的特征语句,而从“判决如下”字段之后通过寻找“犯”、“罪”等相关词语从而提取出罪名。
基于上述思想,具体用代码实现首先需要进行文本分词,本项目采用的是python语言中jieba库对文本进行分词操作,若是使用jieba库的默认词典进行分词将会得到类似于下图的结果:

我们期望是通过分词直接能够将罪名等专业法律名词进行完整提取的,但默认将会使得分成多个词语,于是还需要对jieba库词典进行扩充,我从网上搜集到了一些法律的专业文本,提取专业名词并扩充后的词典部分如下:

给出专业名词并且在后面增加较大数字使得分词更倾向于将其分出,构造的词典加入jieba库后进行测试所得结果如下:

成功分成完整的词语。
由于分词后还会有很多的词语是无意义的词语,因此还需要设定停用词将这类词语进行剔除以增加特征词的频率。最终处理所提取到的每一个判决书中的罪名以及特征如下(部分):


由于对于所有文本进行上述操作是需要一定时间的,为了使后续的实验更加方便,我将罪名与特征语句进行一一对应构造成字典形式并保存在json文件中,文件中部分内容及格式如下:
至此成功实现了样本的处理,并构造了一个更便于后续操作的数据集。
4.2 建立输入矩阵和输出矩阵
文本数据属于非结构化数据,一般要转换成结构化的数据,一般是将文本转换成“文档-词频矩阵”,矩阵中的元素使用词频或者TF-IDF。其中词频(Term Frequency,TF)是指词语在整个文本中出现的频率,计算方法是用该词语在文本中总共出现的次数除以文本中的单词总数;逆文档频率是用来衡量词语是否具有文章代表性的评价方法,计算方法为用语料库中文档的总数除以出现词语的文档数目并取对数[2]。TF-IDF的思想为:如果某一个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,它可以过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要词语,用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度,例如在一份判决书中,可能“过程”这种词是一个通用词,而“逃逸”这种词是专业词,我们的目的是提高专业词的重要性,因此不能仅靠频率去判断,而需要加入权重即逆文本频率指数,一个词预测主题的能力越强,权重就会越大,反之,权重越小,适合用于文本分类。因此本项目采用TF-IDF技术对输入的特征词进行处理,处理后的部分输入词频矩阵如下:

本项目对于用于训练的输出矩阵不进行向量化处理,训练完毕后预测可以直接给出具体罪名
五、模型设计
本项目分类器模型选择的是多项式朴素贝叶斯MultinomialNB,实际在此之前也尝试过使用支持向量机svm等分类器进行分类预测但效果均不佳。
多项式贝叶斯原理比较简单,适用于离散特征并假设特征在类别条件下符合多项式分布,这也意味着许多特征能出现多次,多项式分布擅长的是分类型变量,在其原理假设中,P(xi|Y)的概率是离散的,并且不同xi下的P(xi|Y)相互独立,互不影响。除此之外,多项式实验中的实验结果都很具体,它所涉及的特征往往是次数,频率,计数,出现与否这样的概念,这些概念都是离散的正整数,因此,sklearn中的多项式朴素贝叶斯不接受负值的输入。根据以上特性,多项式朴素贝叶斯的特征矩阵经常是稀疏矩阵,并且它经常被用于文本分类,它可以计算出一篇文档为某些类别的概率,最大概率的类型就是该文档的类别。举个例子,比如判断一个判决书中的罪名属于抢劫罪还是绑架罪,那么只需要判断P(抢劫罪|判决书)和P(绑架罪|文档)的大小。而文档中其实就是一个个关键词(提取出的文档关键词),所以我们需要计算的P(抢劫罪|词1,词2,词3......)和P(绑架罪|词1,词2,词3.....)。
该算法与上述TF-IDF向量技术配合使用可以达到较好的效果且可以很简单地通过sklearn来实现。在sklearn中,用来执行多项式朴素贝叶斯的类MultinomialNB包含如下的参数和属性:
class sklearn.naive_bayes.MultinomialNB (alpha=1.0,fit_prior=True, class_prior=None),其中参数相关解释如下:
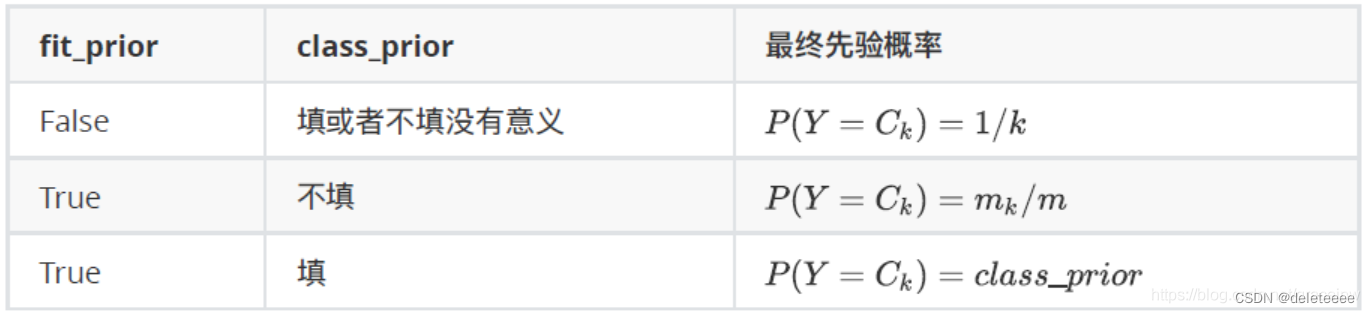
综上,本项目大致流程设计如下:
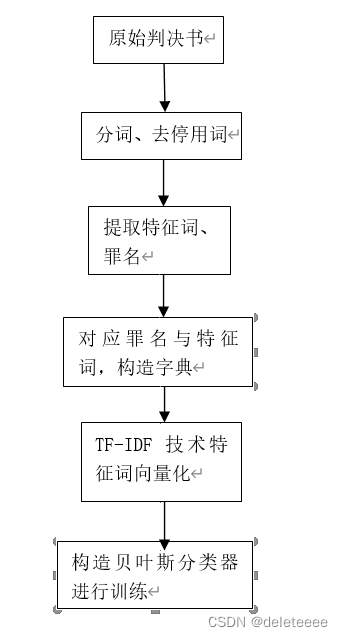
六、验证结果
经过如上处理后,可以构造出文本分类器并进行预测,首先查看利用多项式贝叶斯分类器训练集的部分情况如下:
可以看出对于训练集几乎都能准确预测精度也高达99%
接下来再对测试集进行分类预测,截取的部分结果如下:

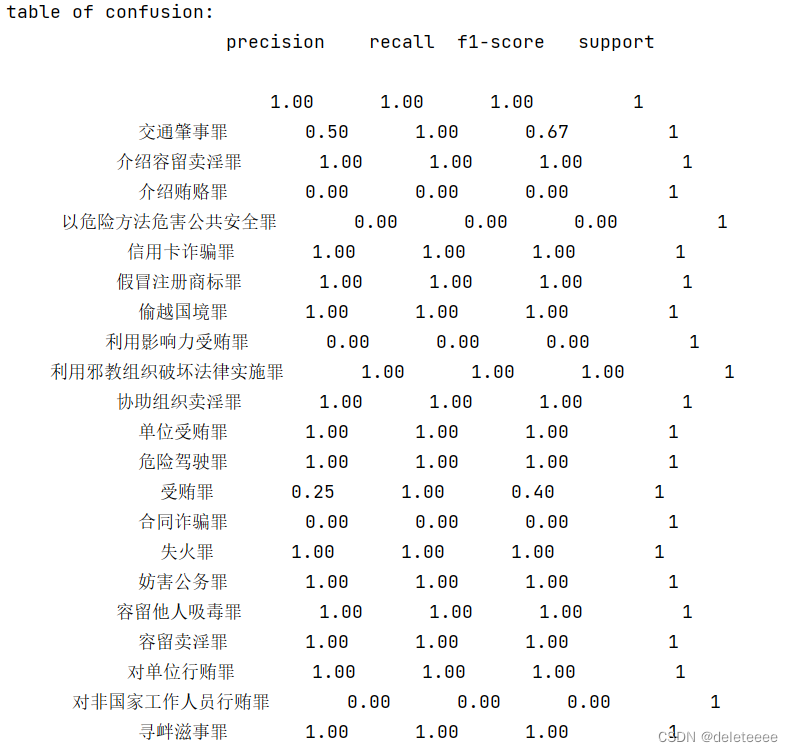

对测试集的预测结果为:

从上述结果中来看,该多项式贝叶斯分类器对测试集的预测精度在70%左右。
而如果采用svm分类则部分结果如下:


虽然训练集精度为1 但测试集的精度等指标都较差。
除此之外,我还尝试过logistic回归模型,结果如下:


本想继续构建textcnn模型来进行实验,但我构造的都不够理想只能放弃。综上分析可知,多项式朴素贝叶斯训练时间最短,对测试集的精度等指标都远远优于我所构造的svm和logistic回归模型。所以最终采用的仍是贝叶斯模型。
七、分析
基本的实验结果已经在算法验证中给出了,通过分析结果可以发现在结果中出现了很多的0值,同时在运行程序时,也可以看到以下警告:

警告的意思表面的时在模型预测中还有一些值并没有被预测到,于是在计算相应指标的时候可能会有除以0的操作导致错误,回顾样本处理的过程也可以发现在训练集和测试集切分的时候会有一些罪名存在于训练集而测试集中没有,也可能存在测试集而训练集中没有,这种类标的缺失在本项目中还没有得到进一步的改善,这也会影响结果的优劣。而通过观察混淆矩阵也可以发现,在预测过程中,每一类罪名都最多只有一种特征与其对应,这是由于在对文本的处理中我是将所有属于一类罪名的判决书中的特征值都整合到了一起进行训练和预测,而并非对于每一个判决书依次进行预测。
接下来对于单个样本进行预测,观察其结果:
输入以下案情:2012年7月4日20时50分,被告人李建酒后无证驾驶一辆桂CR2570小轿车由平乐往二塘方向行驶,当车行至平乐县平乐镇金山村委水冲村路段时,与黄xx驾驶的无号牌两轮摩托车发生碰撞。造成桂CR2570小轿车当场起火,两轮摩托车严重损坏,小轿车驾驶员李建受伤,两轮摩托车驾驶员黄xx及搭乘人员王甲当场死亡的重大交通事故。经交警部门认定,被告人李建负事故的全部责任。案发后,被告人李建赔偿了二位死者家属丧葬费各人民币22,000.00元;中国人寿财产保险股份有限公司桂林市中心支公司在机动车第三者责任强制保险责任限额范围内赔偿二位死者家属各人民币55,000.00元。
上述文本只包含对于案件经过的描述,而目前已知该案最终定罪为交通肇事罪,通过项目所构造的分类器进行预测结果如下:

结果正确。
再进行一次测试(赌博罪):
输入:2015年2月至9月期间,每逢土博街圩日子,被告人周某、胡某、韦某甲、韦某乙、覃某甲、廖某伙同他人在广西柳江县土博镇土博街罗家棚子内,以合股做庄的方式,抓"玉米籽"聚众赌博,每场有10至30不等人员参赌。庄家从赌客每注赢的赌资中抽取10%的水钱,在每场赌博结束后,按入股的比例获取利益或赔钱。2015年6月开始,被告人李南清受雇从事"合利"(负责帮庄家收钱、赔钱),每场获得50-100元报酬。2015年9月16日13时许,公安人员依法对该赌场进行查处,现场抓获周某、胡某、韦某甲李南清及部分赌徒,缴获赌博工具"玉米籽"1包、赌资2290元。2015年11月12日,覃某甲、廖某主动到柳江县公安局投案自首;2015年11月5日,韦某乙主动到柳江县公安局投案自首。
结果:

同样正确
而后续测试中发现如果涉及到抢劫、绑架、敲诈勒索等罪行的时候可能就会错误,这是由于这种类型案件中特征词有很多都类似,有时容易混淆而导致判断错误。
八、代码
完整项目代码及数据集等见本人已发布的资源
















 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











