








梯度下降法
- 假设有 m m m组样本 ( ( x 1 , x 2 ) , y ) ((x^{1},x^{2}),y) ((x1,x2),y)
- 线性回归方程为:
Y = w 0 ⋅ 1 + w 1 x 1 + w 2 x 2 Y=w_{0}\cdot1+w_{1}x^{1}+w_{2}x^{2} Y=w0⋅1+w1x1+w2x2 - 目标为最小化损失函数
f
m
f_{m}
fm
f m = ∑ i = 1 m ( Y i − y i ) 2 = ∑ i = 1 m Y i 2 − 2 Y i y i + y i 2 f_{m}=\sum_{i=1}^{m}(Y_{i}-y_{i})^{2}\\ =\sum_{i=1}^{m}Y_{i}^{2}-2Y_{i}y_{i}+y_{i}^{2} fm=i=1∑m(Yi−yi)2=i=1∑mYi2−2Yiyi+yi2 - 每次迭代下降的方向为:
Δ w j = δ f m δ w j = 2 ∑ i = 1 m ( Y i − y i ) x i j \Delta w_{j}=\frac{\delta f_{m}}{\delta w_{j}}=2\sum_{i=1}^{m}(Y_{i}-y_{i})x_{i}^{j} Δwj=δwjδfm=2i=1∑m(Yi−yi)xij
当 j = 0 j=0 j=0时:
Δ w 0 = 2 ∑ i = 1 m ( Y i − y i ) ⋅ 1 \Delta w_{0}=2\sum_{i=1}^{m}(Y_{i}-y_{i})\cdot1 Δw0=2i=1∑m(Yi−yi)⋅1
梯度上升 w : = w + α Δ w 梯度下降 w : = w − α Δ w \text{梯度上升 }w : =w+\alpha\Delta w\\ \text{梯度下降 }w : =w-\alpha\Delta w 梯度上升 w:=w+αΔw梯度下降 w:=w−αΔw - 对于本例
x
x
x是三维向量的情况:
w = w − ( 1 1 1 ⋯ 1 x 1 1 x 2 1 x 3 1 ⋯ x m 1 x 1 2 x 2 2 x 3 2 ⋯ x m 2 ) ⋅ ( Y 1 − y 1 Y 2 − y 2 ⋮ Y m − y m ) w=w- \begin{pmatrix} 1&1&1&\cdots&1\\ x_{1}^{1}&x_{2}^{1}&x_{3}^{1}&\cdots&x_{m}^{1}\\ x_{1}^{2}&x_{2}^{2}&x_{3}^{2}&\cdots&x_{m}^{2}\\ \end{pmatrix}\cdot \begin{pmatrix} Y_{1}-y_{1}\\ Y_{2}-y_{2}\\ \vdots\\ Y_{m}-y_{m}\\ \end{pmatrix} w=w−⎝⎛1x11x121x21x221x31x32⋯⋯⋯1xm1xm2⎠⎞⋅⎝⎜⎜⎜⎛Y1−y1Y2−y2⋮Ym−ym⎠⎟⎟⎟⎞
Logistic回归
- Sigmoid函数
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
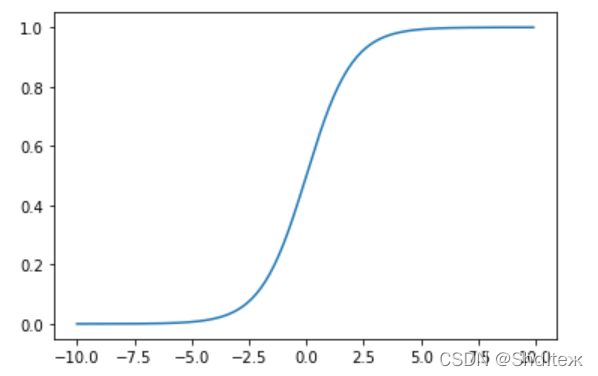
- 对于二分类问题,上文提到的损失函数并非凸函数,所以需要重新定义损失函数,该函数是凸函数
J ( θ ) = 1 m ∑ i = 1 m C o s t ( h θ ( x i ) , y i ) J(\theta)=\frac{1}{m}\sum_{i=1}^{m}Cost(h_{\theta}(x^{i}),y^{i}) J(θ)=m1i=1∑mCost(hθ(xi),yi)
C o s t ( h θ ( x i ) , y i ) = { − l o g ( h θ ( x ) ) y = 1 − l o g ( 1 − h θ ( x ) ) y = 0 Cost(h_{\theta}(x^{i}),y^{i})= \left\{ \begin{array}{rcl} -log(h_{\theta}(x)) & {y=1}\\ -log(1-h_{\theta}(x)) & {y=0} \end{array} \right. Cost(hθ(xi),yi)={−log(hθ(x))−log(1−hθ(x))y=1y=0
J ( θ ) = − 1 m [ ∑ i = 1 m y i l o g ( h θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] J(\theta)=-\frac{1}{m}[\sum_{i=1}^{m}y^{i}log(h_{\theta}(x^{i}))+(1-y^{i})log(1-h_{\theta}(x^{i}))] J(θ)=−m1[i=1∑myilog(hθ(xi))+(1−yi)log(1−hθ(xi))]
训练算法:使用梯度下降找到最佳参数
#Logistic回归梯度上升优化算法
import numpy as np
def loadDataSet():
dataMat=[]; labelMat=[]
fr=open('testSet.txt')
for line in fr.readlines():
lineArr=line.strip().split()
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+np.exp(-inX))
def gradAscent(dataMatIn,classLabels):
dataMatrix=np.mat(dataMatIn)
labelMat=np.mat(classLabels).transpose()
m,n=np.shape(dataMatrix)
alpha=0.001
maxCycles=500
weights=np.ones((n,1))
for k in range(maxCycles):
h=sigmoid(dataMatrix*weights)
error=(labelMat-h)
weights=weights+alpha*dataMatrix.transpose()*error
return weights
分析数据:画出决策边界
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr=np.array(dataMat)
n=np.shape(dataArr)[0]
xcord1=[]; ycord1=[]
xcord2=[]; ycord2=[]
for i in range(n):
if(int(labelMat[i])==1):
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
x=np.arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]
ax.plot(x,y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()

随机梯度下降算法
梯度上升算法每次更新回归系数时,要遍历整个数据集,时间复杂度较高。一种改进方法是一次只用一个样本点来更新回归系数,该方法称为随机梯度上升算法。
所有回归系数初始化为1
对数据集中每个样本:
计算该样本的梯度
使用alpha*gradient更新回归系数值
返回回归系数值
def stocGradAscent0(dataMatrix,classLabels):
m,n=np.shape(dataMatrix)
alpha=0.1
weights=np.ones(n)
for i in range(m):
h=sigmoid(np.sum(dataMatrix[i]*weights))
error=classLabels[i]-h
weights=weights+alpha*error*dataMatrix[i]
return weights

该拟合直线并非最佳分类线
改进的随机梯度下降算法
def stocGradAscent1(dataMatrix,classLabels,numIter=150):
m,n=np.shape(dataMatrix)
weights=np.ones(n)
for j in range(numIter):
dataIndex=np.array(range(m))
for i in range(m):
alpha=4/(1.0+i+j)+0.01
randIndex=int(np.random.uniform(0,m))
h=sigmoid(sum(dataMatrix[randIndex]*weights))
error=classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
np.delete(dataIndex,randIndex)
return weights
















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









