









DQN(进阶技巧)
Double DQN
**原因:**DQN中,Q值往往被高估了。

设计了两个Q-network:
- 假设第一个 Q-function 高估了它现在选出来的动作 a,只要第二个 Q-function Q’没有高估这个动作 a 的值,那你算出来的就还是正常的值。
- 假设 Q’高估了某一个动作的值,那也没事,因为只要前面这个 Q 不要选那个动作出来就没事了,这个就是 Double DQN 神奇的地方。
实现上:
原本DQN就有两个network,目标网络(固定不动)和行为网络(不断更新)。在Double DQN中,使用行为网络选动作,目标网络(即固定不动的网络)去计算值。
Double DQN 对DQN的改动很少,几乎没有增加运算量,也不需要增加新的网络。
Dueling DQN
改变了网络的架构。不直接输出Q值,而是分成两条路径:
- 第一条路径输出 scalar, V ( s ) V(s) V(s)。(不同状态有一个值)
- 第二条路径输出一个 vector
A
(
s
,
a
)
A(s,a)
A(s,a)。(不同状态-动作 对,都有一个值)
把两个加起来就得到Q值
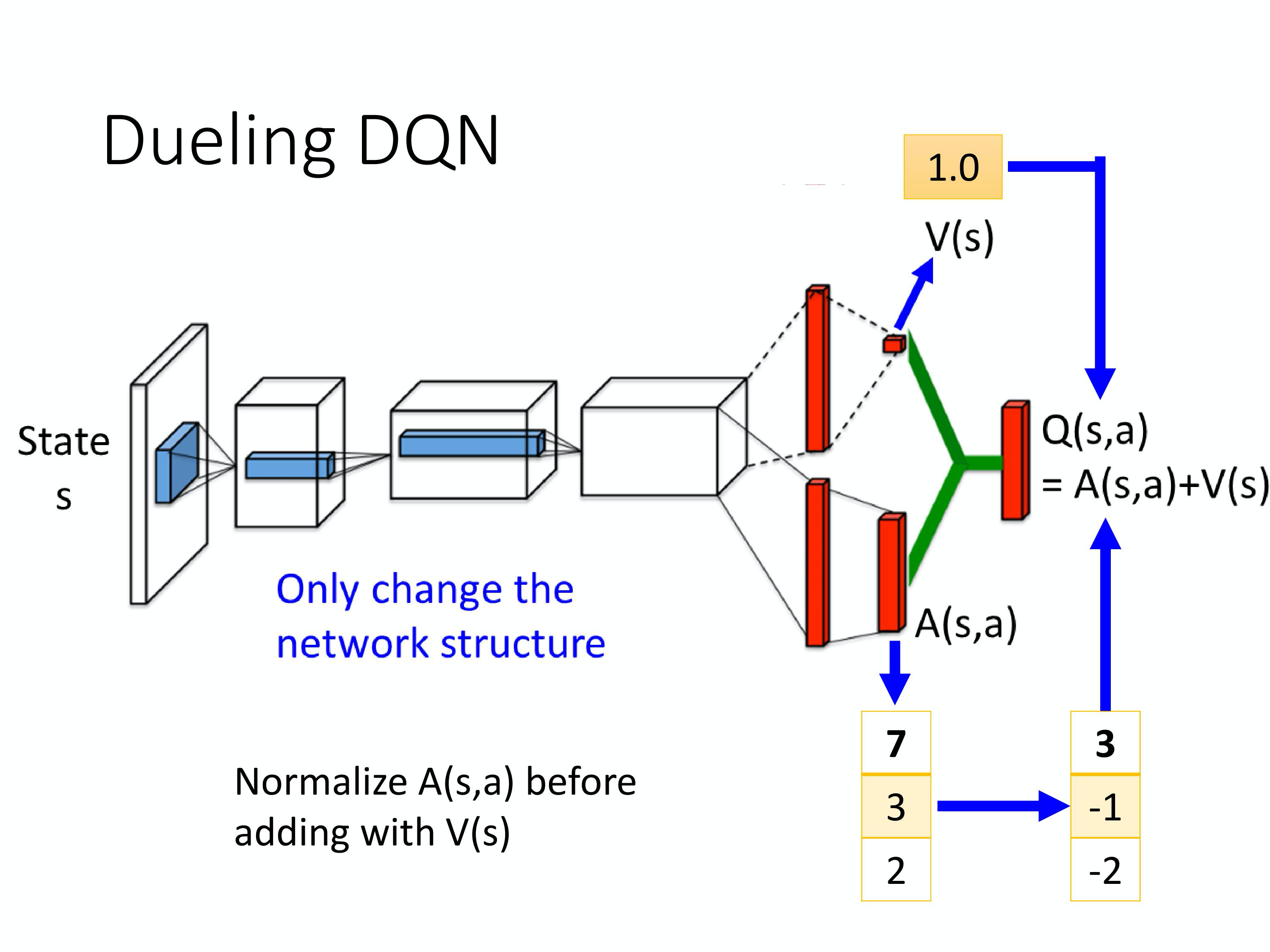
优点:不需要把所有的 state-action pair 都 sample ,就可以高效地估计 Q 值。
实现时,需要给A加约束。大概是归一化吧,这个地方我没有细看
Prioritized Experience Replay
- 从reply buffer中采样数据时,不再均匀采样,而是赋予那些训练不好的数据
priority,提高他们被采样的概率。 - prioritized experience replay 的时候,不仅会更改采样流程,也会间接更改参数更新过程。所以 prioritized experience replay 不仅改变了 sample 数据的分布,还改变了训练过程。
Balance between MC and TD
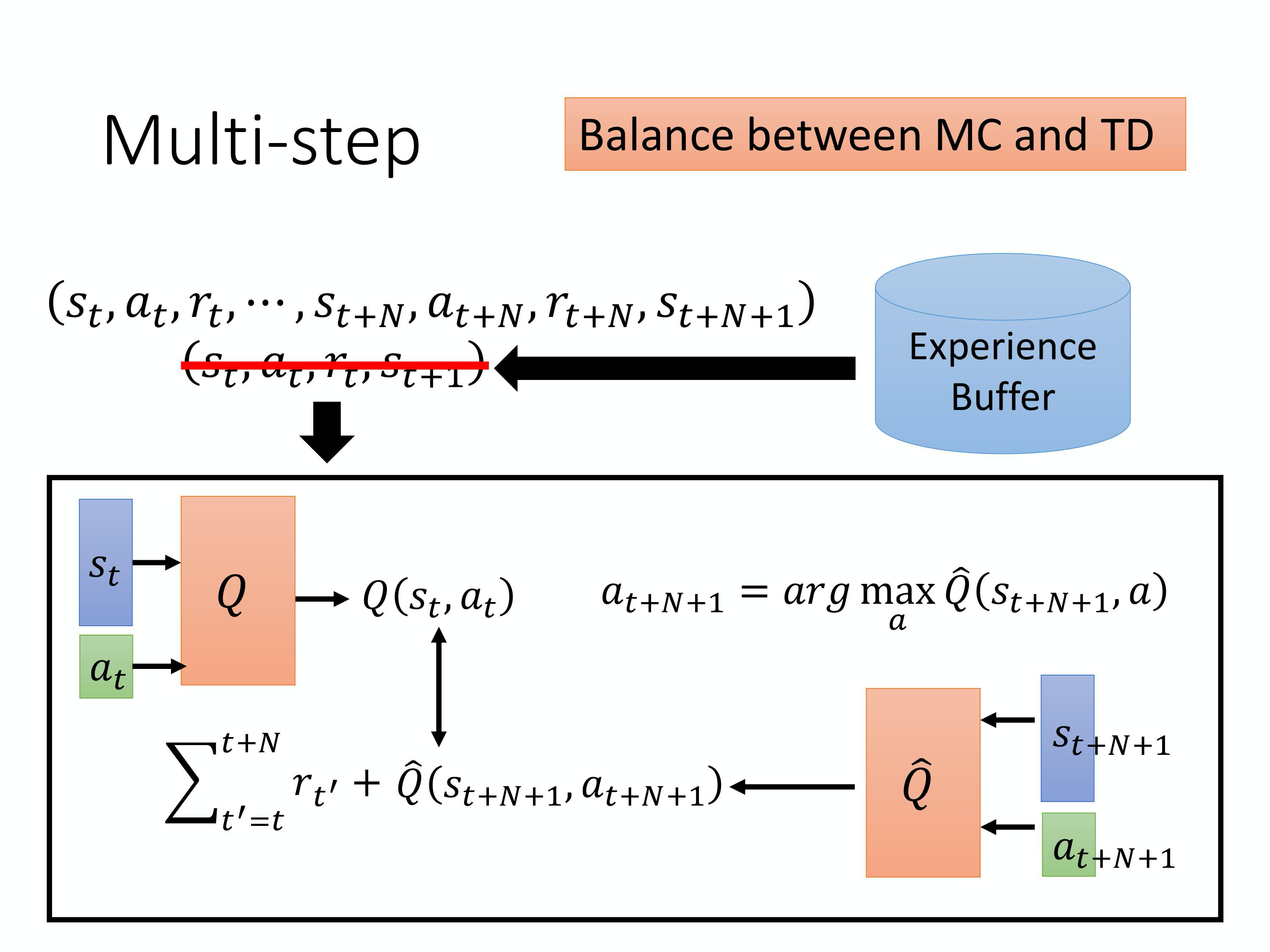
sample N个步骤再估值
(这部分没有认真看)
Noise Net

针对exploration进行改进
Epsilon Greedy这样的探索是在动作的空间上面加噪声,但是有一个更好的方法叫做Noisy Net,它是在参数的空间上面加噪声。- 在模型要跟环境互动时,在Q-function中加一个高斯噪声,变成 Q ~ \tilde{Q} Q~。游戏结束之后,再去采样新的噪音。
Distributional Q-function
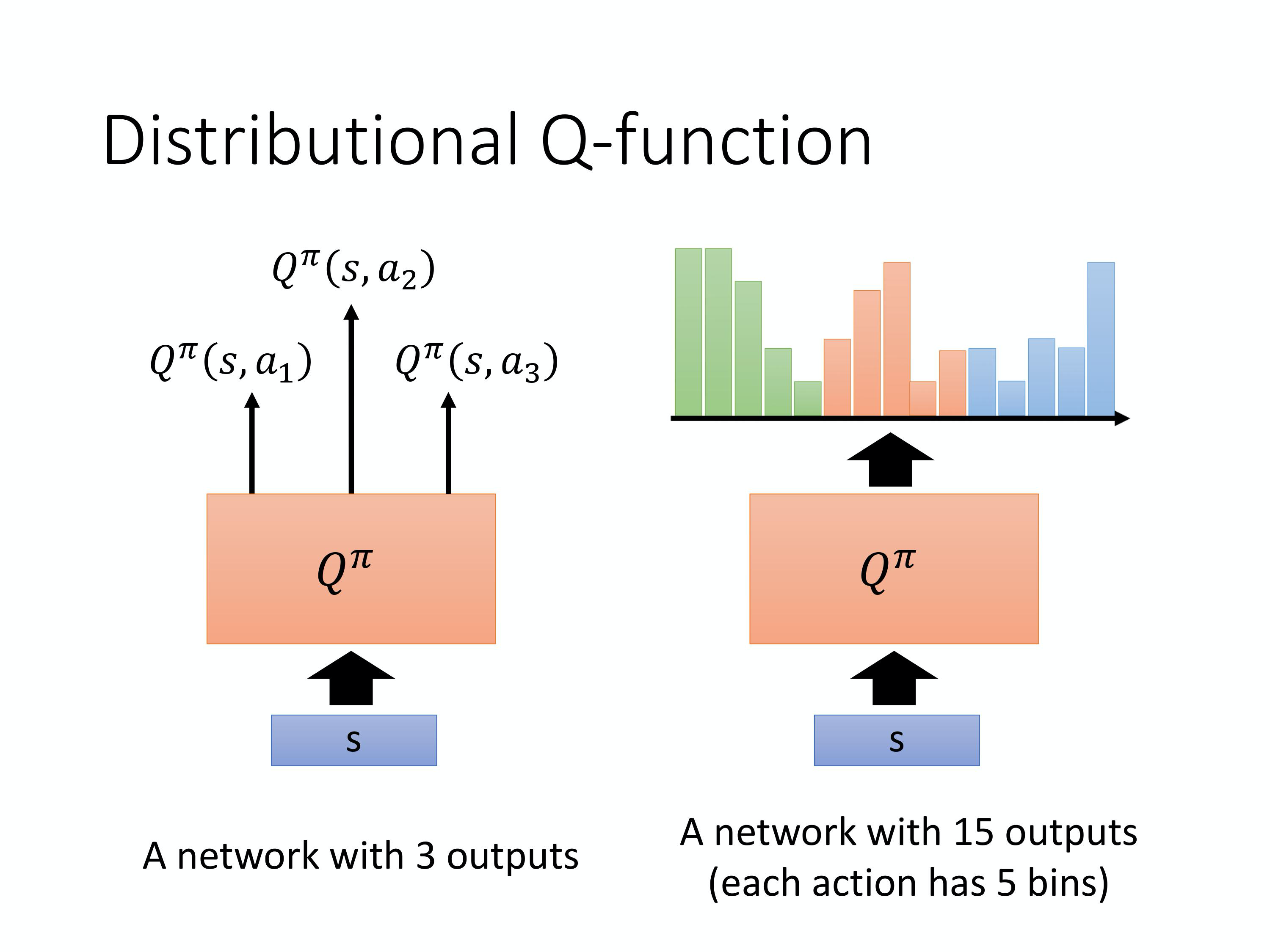
- 我们使用Q值的期望来代表整个reward,可能会丢失一些信息。
- 对于DQN进行model distribution。将最终的网络的output的每一类别的action再进行distribution。
Rainbow
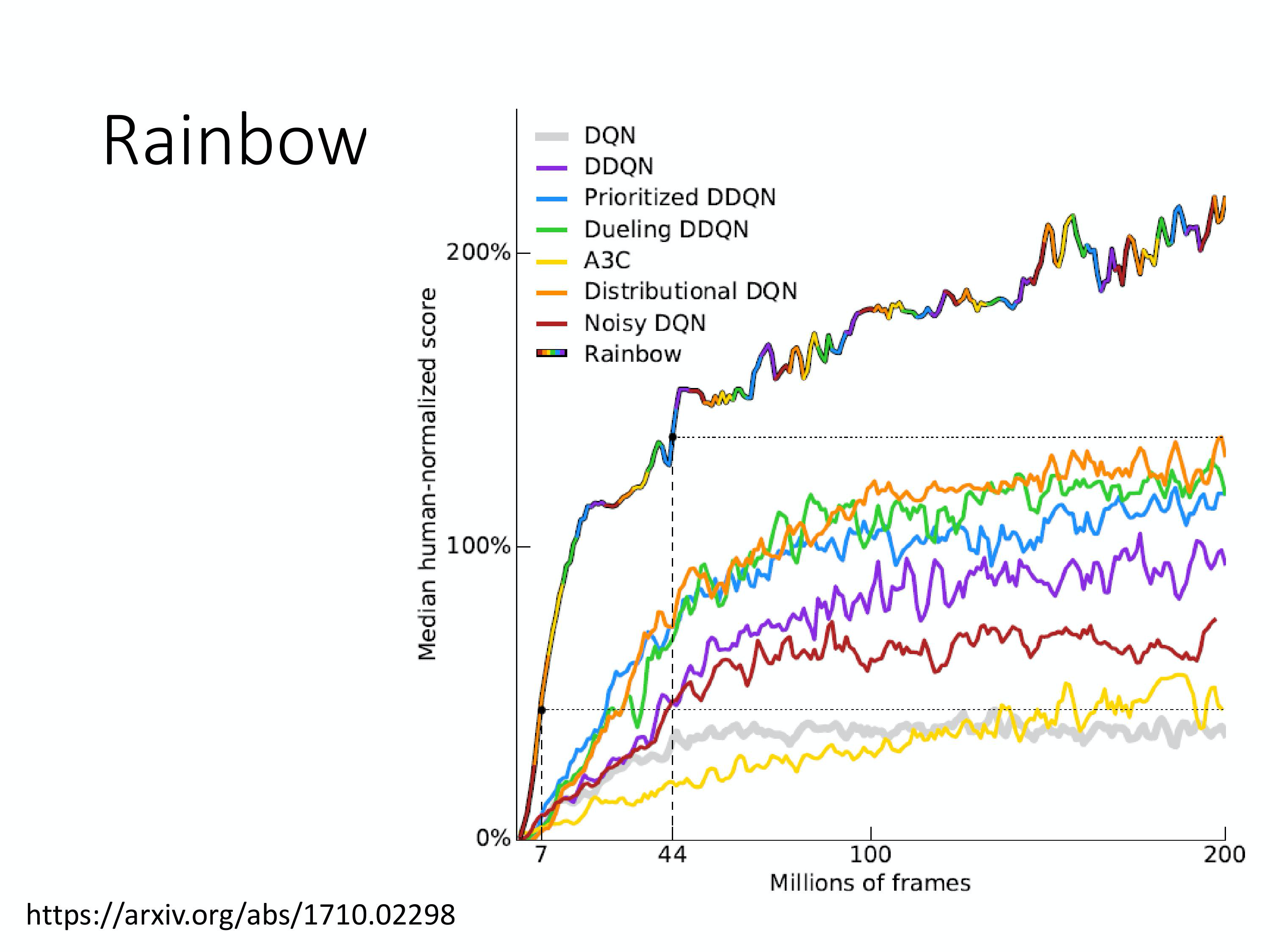
把前面所有的方法都综合起来
总结总结总结
- 高冷的面试官:DQN都有哪些变种?引入状态奖励的是哪种?
答:DQN三个经典的变种:Double DQN、Dueling DQN、Prioritized Replay Buffer。
- Double-DQN:将动作选择和价值估计分开,避免价值过高估计。
- Dueling-DQN:将Q值分解为状态价值和优势函数,得到更多有用信息。
- Prioritized Replay Buffer:将经验池中的经验按照优先级进行采样。
第八章 DQN(连续动作)
原文链接
DQN要维护一个Q函数,不好处理连续动作。
这个地方,引出了actor-critic = 基于策略的PPO 和 基于价值的DQN。
总结
- Q-learning相比于policy gradient based方法为什么训练起来效果更好,更平稳?
在 Q-learning 中,只要能够 estimate 出Q-function,就可以保证找到一个比较好的 policy,提升对应的 policy。在这个回归问题中, 我们可以时刻观察我们的模型训练的效果是不是越来越好,一般情况下我们只需要关注 regression 的 loss 有没有下降,你就知道你的 model learn 的好不好。















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









