









这是一篇智慧交通领域的综述,侧重于讲解用强化学习解决交通信号灯管控 RL+TSC ;Traffic Signal Control :交通信号灯管控,
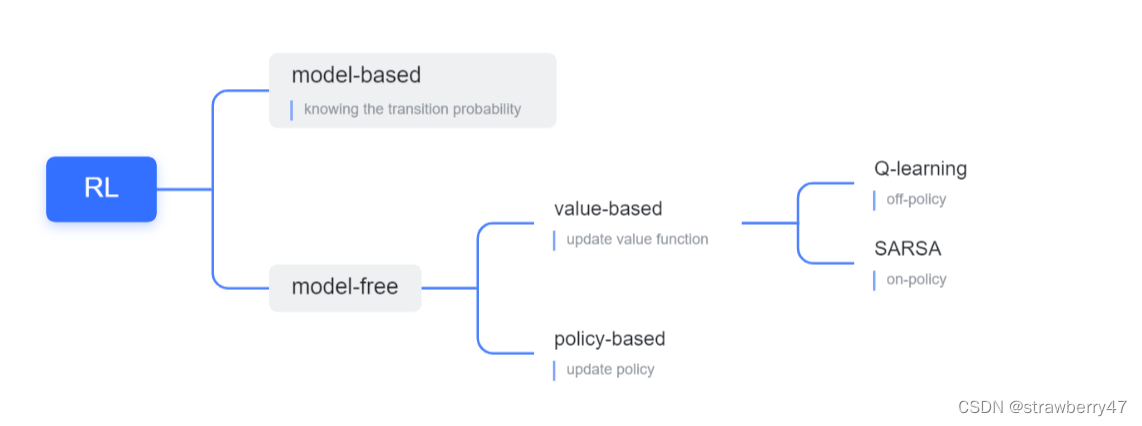
一. Overview
- 分类:
AI based transportation applications:
① management applications,
② public transportation,
③ autonomous vehicles
这部分还介绍了很多RL的基本概念,目标网络、经验回放等等,都是强化学习领域的常见知识点,可以看我其他笔记~
交通信号灯管控:
state:队伍长度、车辆位置、车辆速度
目标:最小化十字路口的堵塞
二. 交通信号灯控制表示为 Deep RL 问题
2.1 state:
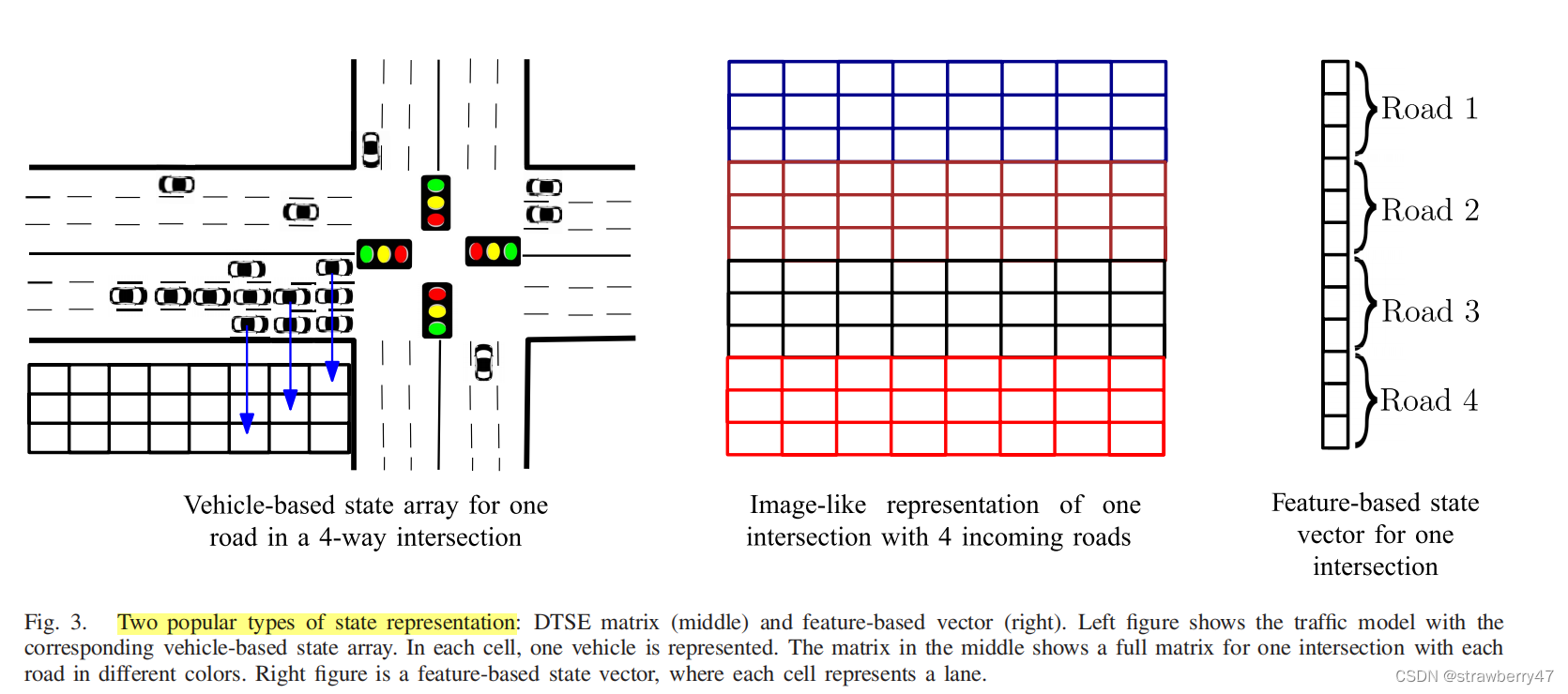
- RGB图像,结合DQN;交叉口的快照(速度和位置)
- Image-like representation/discrete traffic state encoding (DTSE); 优点:包含了丰富的信息,速度、位置、信号灯、加速度
- feature-based value vector,向量表示;如:队伍长度、累计等待时间、一条车道的平均等待时间、信号灯持续时间、一条车道的车辆数
- 考虑更完整的道路信息
2.2 action:
一般是十字路口,需要考虑不同方向和持续时长;
四种绿灯阶段: North-South Green (NSG)南北方向通行, East-West Green (EWG)东西方向通行, North-South Advance Left Green (NSLG)南北方向可左转, East-West Advance Left Green (EWLG)东西方向可左转.
- 选择绿灯(四个方向中选一个绿灯)
- binary action:保持当前or换方向
- 更新每个阶段持续时长
Q:只关心绿灯吗?
A:有的论文简化成两个绿色阶段:南北绿色和东西绿色,忽略了左转
2.3 reward:
- 等待时间
- 累计延迟
- 队伍长度
- absolute value of the traffic data (流量数据)
2.4 Neural Network Structure:
- MLP
- CNN:和DQN结合
- RNN:序列数据
- AutoEncoder
2.5 仿真环境:
- 早期:Java-based Green Light District (GLD)
- 流行:Simulation Urban Mobility (SUMO)
- 成熟:VISSIM,AIMSUN(与MATLAB交互好)
三. Deep RL在交通信号灯控制中的应用
3.1 Standard RL Applications:
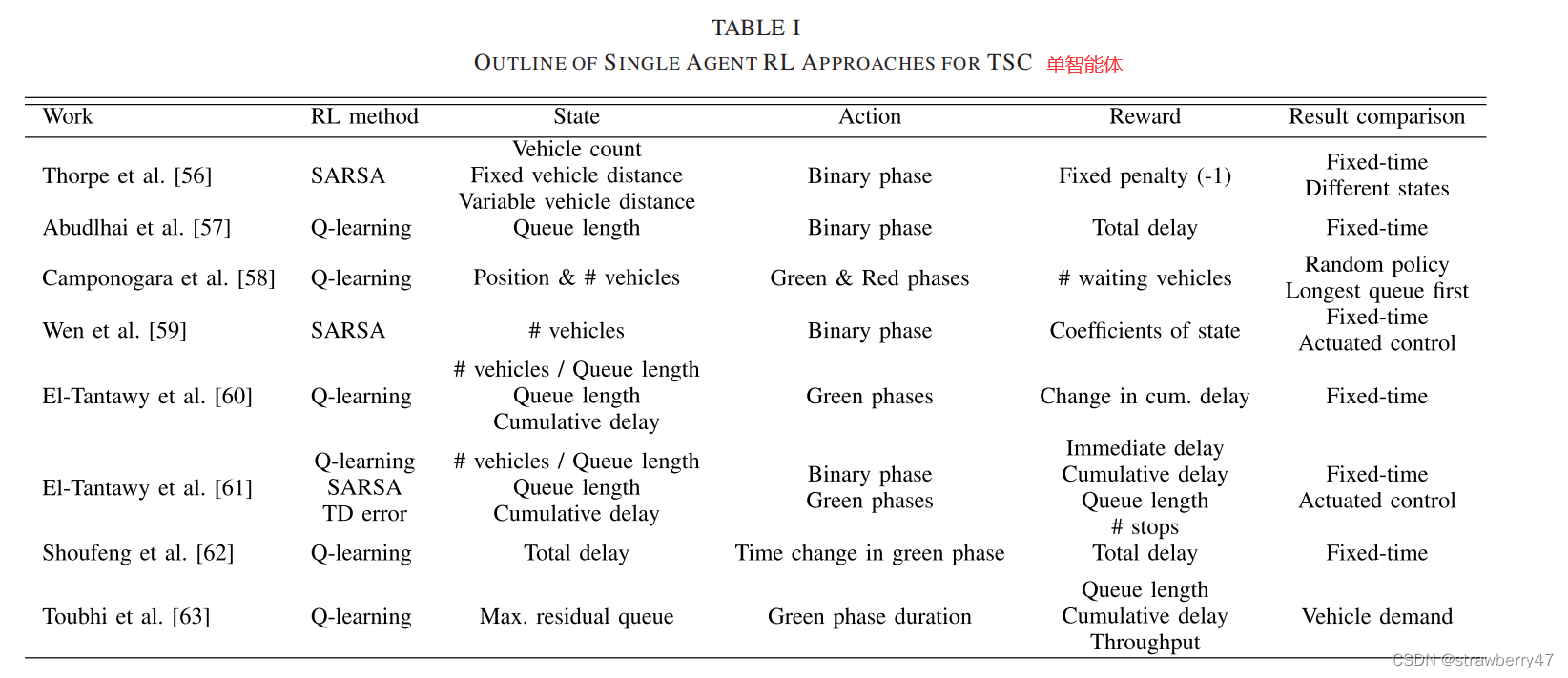
3.1.1 Single Agent Applications:
RL-based single intersection
会分成单交叉口和多交叉口交通
参考文献[57]将队伍长度作为state,总延迟时间作为reward;是第一篇binary action model;与固定时间的信号灯的场景对比
文献[60]首次提出真实交叉路口场景,提出了三种state定义。。。 四个reward function。
(这部分相当于related work)
3.1.2 Multi-Agent Applications
协同控制多个十字路口
- 四种标准TSC算法(应该是常用baseline):固定时间控制、随机控制、最长队伍优先、车辆最多优先
- 比较经典的算法(Wiering提出):TC-1,TC-2,TC-3
- state由红绿灯配置、车辆位置、车辆目的地构成,考虑到了局部和全局的特征(实际并不可行,因为车辆信息是未知的)
- 目的是减小等待时间
-
后续工作对Wiering工作的改进:
① 增加其他路口的堵塞信息
② 增加state size(通过增加堵塞信息)
③ 增加堵塞系数(instead of increasing the state space)
④ 加入堵塞和意外信息
⑤ 考虑协同信息
⑥ 多目标:vehicle stops, average waiting time, and maximum queue length are targeted as objectives for low, medium, and high traffic volume 根据不同场景进行不同设计reward function -
Khamis的工作:
① 贝叶斯转移概率->reward function
② more specific objectives
③ seven objectives,加上了cooperative exploration function -
related work:
① 分层强化学习
② R-Markov Average Reward
③ 考虑各个区域间的协同信息















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









