







将专家混合推向极限:参数效率极高的 MoE 指令调节
name=Ted Zadouriaffiliation=Cohere for AI email=ted@cohere.com name=Ahmet Üstün affiliation=Cohere for AI email=ahmet@cohere.comname=Arash Ahmadian†affiliation=Cohere for AI email=arash@cohere.com name=Beyza Ermiş affiliation=Cohere For AI email=beyza@cohere.com name=Acyr Locatelli affiliation=Cohere email=acyr@cohere.com name=Sara Hooker affiliation=Cohere for AI email=sarahooker@cohere.com
摘要
专家混合 (MoE) 是一种众所周知的神经架构,其中一组专门的子模型以恒定的计算成本优化整体性能。 然而,由于需要将所有专家存储在内存中,传统的 MoE 带来了大规模的挑战。 在本文中,我们将 MoE 推向了极限。 我们通过独特地将 MoE 架构与轻量级专家相结合,提出了参数效率极高的 MoE。我们的 MoE 架构优于标准参数高效微调 (PEFT) 方法,并且仅通过更新轻量级专家即可与完全微调相媲美 - 少于 1% 11B 参数模型的百分比。 此外,我们的方法可以推广到看不见的任务,因为它不依赖于任何先前的任务知识。 我们的研究强调了专家混合架构的多功能性,展示了即使受到严格的参数约束也能提供稳健性能的能力。 我们在所有实验中使用的代码均可在此处公开获取:GitHub - for-ai/parameter-efficient-moe。
0
1简介
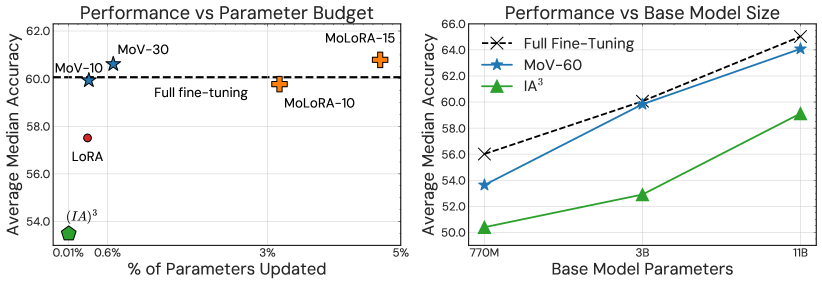
图1:左边:使用 T5-XL (3B) 演示的相当数量的参数,我们的 PEFT 专家组合优于 SOTA 单一 PEFT 方法。 右:PEFT方法的混合可扩展到11B;通过微小的参数更新,它接近或匹配完整的微调性能。
传统的训练范例是将模型的权重应用于每个输入。 可以说,这效率不高,因为给定的输入可能不需要模型的全部容量。 相比之下,MoE 的前提是子模块化组件(所谓的专家)可以专门处理不同类型的输入。 这种对条件计算的强调具有重要的效率副作用,例如恒定的推理成本。 这使得 MoE 在大规模 Transformers 时代成为重要研究和广泛采用的领域,在大规模 Transformer 时代,扩展增加了部署和延迟成本(Shazeer 等人,2018;Riquelme 等人,2021;Du 等人,2022; Fedus 等人,2022)。
虽然迄今为止的大多数工作都将 MoE 作为预训练策略,但 MoE 的内在动机并不仅仅局限于预训练。 事实上,MoE 的优点可以说非常适合指令微调设置,其中数据通常被故意结构化以表示不同的任务集,通常称为多任务微调(Chung 等人, 2022; Wei 等人, 2022; Sanh 等人, 2022; Longpre 等人, 2023; Muennighoff 等人, 2023)。
在这项工作中,我们提出了这个问题 我们可以利用 MoE 进行指令微调吗? MoE 范式的主要缺点之一是它引入了大量的总参数(Fedus 等人,2022)。 尽管有条件计算,但考虑到需要更新所有参数,完全微调 MoE 架构的计算要求极高。 对于大多数从业者来说,考虑到现代大语言模型 (Brown 等人, 2020; Touvron 等人, 2023; Kaplan 等人, 2020; Anil 等人, 2023) 的规模,这是一个不可行的计算成本。
因此,我们专注于为日常实践者提供更现实的环境 - 我们能否成功地将 MoE 应用于参数高效微调(PEFT)方法,例如(IA)3 (Liu等人, 2022) 或 LORA (Hu 等人, 2021) 只调整了少得多的参数。 这是一个重大挑战,不仅因为我们的目标是仅更新所有参数的一小部分,而且因为我们还要应对先前工作中已经注意到的 MoE 固有的优化挑战(Chen 等人,2022)在更加受限的环境中。
在这项工作中,我们提出了一个新框架,在严重受限的计算环境中利用 MoE 的优势。 我们引入了Mixture of Vectors (MoV)和Mixture of LORA (MoLORA),这是专家混合方法的参数高效适应。 与标准 MoE 不同,我们的框架由于其轻量级性质,可以在参数有限的设置中使用。 值得注意的是,我们的方法通过更新不到 1% 的参数,对未见过的任务进行全面微调,从而实现了性能平价。 它还可以轻松胜过 (IA)3 或 LORA 等基本参数高效技术。
我们在 55 个数据集 P3 (Sanh 等人,2022)的 12 不同任务中,在 T5 模型 (Raffel 等人,2020) 上取得了一致的结果,范围从 770M 到 11B 。 总之,我们的贡献如下:
- (我)
我们提供参数极其高效的 MoE。 该架构利用模块化和轻量级专家在更现实的环境中利用 MoE。 我们的 MoE 可以通过更新不到 1% 的参数来调节密集模型。
- (二)
使用我们提出的方法进行指令微调在未见过的任务上始终优于传统的参数有效方法,同时在不同尺度上保持高参数效率。 在 3B 和 11B 模型尺寸下,(IA)3 向量 (MoV) 的混合比标准 (IA)3 分别实现了高达 14.57% 和 8.39% 的改进。 这种优势适用于不同的模型大小、专家类型和可训练参数预算。
- (三)
我们证明,我们的配方可以在大范围内匹配完全微调的性能,同时更新一小部分模型参数。 我们在 8 个未见过的任务中的结果表明,我们的 MoV 仅更新了 3B 和 11B 模型中 0.32% 和 0.86% 的参数,在完全微调方面实现了极具竞争力的性能,同时显着降低了计算成本。
- (四)
最后,我们提出了一系列广泛的消融研究,系统地评估了各种 MoE 架构和 PEFT 策略在不同模型大小、不同适配器类型、专家数量、路由机制以及优化超参数的重要性下的功效,特别是考虑到教育部的敏感性。
2方法论
指令调整设置是这样制定的,其中有一组任务分为训练任务和保留评估任务𝑇=𝑇train∪𝑇eval。 基本预训练模型首先在 𝑇𝑡𝑟𝑎𝑖𝑛 上进行微调,然后以零样本的方式对 𝑇𝑒𝑣𝑎𝑙 中每个未见过的任务进行评估。 标准方法是微调所有导致高计算和内存成本的模型参数。 我们的方法提供了一种使用参数有效的专家组合的有效替代方案。 在本节中,我们详细描述我们的框架。
2.1使用(IA)3和LORA适配器进行参数高效的微调
在这项工作中,我们使用参数高效微调 (PEFT) 方法将专家混合 (MoE) 架构推向参数效率的极限。 PEFT 方法通过将权重更新限制为有限数量的参数,解决了与更新大量参数相关的挑战,尤其是在完全微调大语言模型时大规模出现的挑战。 为了展示我们的方法如何使用不同的 PEFT 技术进行扩展,我们对 (IA)3 和 LORA 进行了实验。 这些方法向现有的预训练模型添加少量参数。 下面我们简单介绍一下每种PEFT方法:
(IA)3 引入了三个新向量,𝑙k∈ℝ𝑑k、𝑙v∈ℝ𝑑v、𝑙ff∈ℝ𝑑ff,它们重新缩放自注意力和中间值中的键和值激活位置前馈层中的激活:
| softmax(𝑄(𝑙k⊙𝐾𝑇)𝑑k)(𝑙v⊙𝑉);(𝑙ff⊙𝛾(𝑊1𝑥))𝑊2 | ((IA)3) |
其中 𝑄、𝐾、𝑉 是用于自注意力的查询、键和值投影矩阵,𝑊1、𝑊2 是预训练模型中前馈层的冻结权重。 由于 (IA)3 仅更新每个 Transformer 层的 𝑙k、𝑙v、𝑙ff 重新缩放向量1,它的参数效率极高。 对于30亿参数的T5模型(Raffel等人,2020),它只更新总参数中的0.018%。
请注意,与适配器 (Houlsby 等人, 2019) 或提示调整 (Lester 等人, 2021) 不同,(IA)3
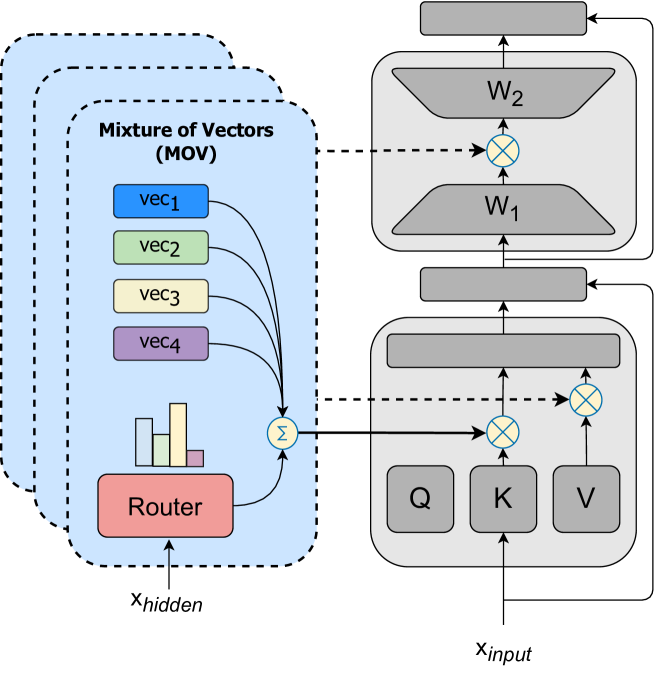
1class MOV_Layer(nn.module):2 n_experts: int # number of experts34 def call(self, inputs):5 # inputs shape: [batch, seq, h_dim]6 batch, seq, h_dim = inputs.shape78 # MOV scaling vectors: [n_experts, h_dim]9 mov_vectors = self.param(’mov_scalers’,10 nn.init.ones(), (self.n_experts, h_dim))1112 # router probs: [batch, seq, n_experts]13 router_probs = self.router(inputs,14 self.n_experts, dtype=’float32’)1516 # combined vector: [batch, seq, h_dim]17 mov_combined = jnp.einsum(’...e,ed->...d’,18 router_probs,19 mov_vectors)2021 return inputs * mov_combined
图2:左边:MoV 架构概述,强调软合并,其中每个多头注意力块仅更新向量和路由器,如颜色所示。 右:类似于 JAX 的伪代码,说明了 MoV 层的核心实现。
低秩自适应 (LORA; Hu 等人, 2021)优化大语言模型中密集层的低秩分解。 对于预训练的权重矩阵 𝑊0∈ℝ𝑑m×𝑑p 和输入激活 𝑥∈ℝ𝑑m,LORA 将 𝑊0 分解为两个低秩矩阵:
| ℎ=𝑊0+Δ𝑊𝑥=𝑊0+𝐵𝐴𝑥 | (LORA) |
其中 𝐵∈ℝ𝑑p×𝑟 𝐴∈ℝ𝑟×𝑑m 和排名 𝑟=min(𝑑m,𝑑p)。 在微调期间,所有预训练权重都被冻结,并且仅更新 𝐴 和 𝐵 矩阵。
LORA 适配可用于每个 Transformer 块中的所有线性层,包括查询 𝑄、键 𝐾、值 𝑉 和输出 𝑂 自注意力和前馈层 𝑊1 和 𝑊2。 与(IA)3不同,LORA自适应在使用的参数方面提供了更大的灵活性。 我们可以通过增加矩阵分解的等级 𝑟 来调整容量,直到达到由 𝑟=min(𝑑m,𝑑p) 确定的最大值。 为了说明其参数效率,对于T5 3B模型,等级为4的LORA更新模型参数的0.3%。
2.2极其参数高效的专家组合
我们提出了一种参数效率极高的专家混合(MoE)框架,该框架利用轻量级“适配器”作为预训练密集模型之上的专家。 具体来说,MoE 是一个神经网络架构家族,它可以通过基于门控机制(路由器)激活的多个专家来进行条件计算。 MoE 层由路由器网络 𝑅 和一组 𝑛 专家 𝐸1,…,𝐸𝑛 组成,其中每个专家 𝐸𝑖 都是参数化函数。 遵循 Fedus 等人 (2022),我们的路由器网络通常由具有可训练权重 𝑊𝑔∈ℝ𝑑m×𝑛 的密集层组成,后跟一个 softmax 函数,该函数采用中间值词符表示 𝑥 作为输入,并根据门控分数 𝑠1,…,𝑠𝑛 组合每个专家的输出:
| 𝑠𝑖=𝑅(𝑥)𝑖=softmax(𝑊𝑔𝑇𝑥) | (Router) | ||
| 𝑦=∑𝑖=1𝑛𝑠𝑖⋅𝐸𝑖(𝑥) | (MoE) |
对于 Transformer 模型(Vaswani 等人,2023),密集前馈层被 MoE 层取代,其中每个专家 𝐸𝑖 对应一个独立的密集前馈网络。 随着每个专家规模和专家数量的增加,模型参数的总数会成倍增加。 然而,在我们的参数高效 MoE 架构中,我们用轻量级 PEFT 适配器(例如 (IA)3 向量或 LORA 适配器)替换每个专家。 在微调过程中,密集层的预训练权重保持固定,而专家层和路由器层则从头开始训练。 与标准 MoE 不同,我们的轻量级专家学习在微调时间内调整预训练的 Transformer 层。 这样,我们的 MoE 框架需要有限数量的参数更新,并且总共不会引入巨大的模型大小。
除了参数效率之外,我们选择的 PEFT 适配器还可以通过软合并进行路由计算。 具体来说,由于 (IA)3 向量和 LORA 适配器都是线性函数,因此我们首先计算专家的加权平均值,然后使用类似于 Muqeeth 的组合专家 𝐸𝑚𝑖𝑥 进行 PEFT 变换等人(2023):
| 𝐸𝑚𝑖𝑥=∑𝑖=1𝑛𝑠𝑖⋅𝐸𝑖;𝑦=𝐸𝑚𝑖𝑥(𝑥) | (Soft Merging) |
我们将方法的变体称为向量混合(MoV)和LORA混合(MoLORA)分别利用 (IA)3 向量或 LORA 适配器作为专家,两者都比相应的 PEFT 方法表现出一致的增益。 图2显示了MoV层的架构以及相应的伪代码。 仅通过 MoV 和 MoLORA 更新一小部分参数不仅对训练而且对推理时间都有多种实际好处,后者是 MoE 架构所独有的。 我们在下面简要概述了这些收益:
训练效率 我们极其参数高效的 MoE 公式可显着减少记忆力。 训练期间冻结大多数参数减少了计算模型参数梯度的计算开销,同时也减少了存储模型优化器状态的内存需求。 后者可能非常重要,具体取决于优化器的选择,例如 Adam (Kingma & Ba,2017) 的变体,包括 AdamW (Loshchilov & Hutter,2019) ,需要每个参数所需内存的两倍来存储优化器状态(第一和第二时刻的估计),而 Adafactor (Shazeer & Stern, 2018) 通过对二阶参数矩。
推理效率 我们的 MoV 和 MoLORA 方法固有的结构模块化可以在推理时显着提高内存。 对于传统的 MoE 模型,在推理时需要将成熟的前馈块的许多副本(甚至基于特定架构的模型的完整副本)存储在内存中,这是一项昂贵的工作。 使用我们的方法,无论具体类型如何,除了轻量级参数高效专家之外,只需要在内存中存储模型主干的单个副本。 这导致推理时的内存需求显着减少。
3实验
数据集我们使用公共提示池(P3)数据集Sanh等人(2022)中的一套全面的提示指令进行指令调优实验。 我们遵循与 Raffel 等人 (2020) 相同的过程,其中每个任务都转换为 (Sanh 等人, 2022) 中提供的模板格式。 P3 是 62 个数据集的集合,涵盖各种任务。
实验设置 对于基础预训练模型,我们使用 T5 v1.1+LM 适配(Lester 等人, 2021),其中包括从 770M 到 11B 不同大小的 T5 模型参数。 对于所有实验,我们使用 Adafactor 优化器 (Shazeer & Stern,2018) 进行学习,学习率为 3𝑒−4。 我们将输入的序列长度设置为 1024,将 Sanh 等人 (2022) 之后的目标序列长度设置为 256。 对于所有参数高效的 MoE 变体,我们使用超过 500K 步的批量大小 32 来构建 T5 模型。
基线我们将参数高效专家的组合与作为完全微调模型的T0基线以及标准参数高效微调方法(IA)3和LORA进行比较。 对于 T0 基线,根据我们使用不同超参数的实验,我们发现较大的批量大小和学习率会带来更好的性能,因此,我们通过微调 10k 步骤、批量大小为 256 和学习率来复制 T0的1𝑒−3,遵循Phang等人(2023)——这些超参数取得了明显更高的结果,如表4所示。 对于(IA)3和rank=4的LORA,我们使用相同的训练超参数,例如3𝑒−4的学习率和超过500k步的32个批次。
指标 按照 T0 Sanh 等人 (2022) 中提出的零样本评估,我们在 8 个保留的(训练期间未见的)数据集上测试我们的方法和基线 – ANLI (Nie 等人, 2020)、HellaSwag (Zellers 等人, 2019)、WinoGrande (Sakaguchi 等人, 2019) 和 5 Super Glue 数据集Wang 等人 (2020)。 这些数据集涵盖了不同的任务,包括共指消解、自然语言推理、多项选择题回答、故事完成和词义消歧。 我们计算不同提示模板中每个评估数据集的准确度中位数,然后报告每个数据集的结果以及所有数据集的平均值。 我们还在附录中列出了所有评估数据集的平均准确度。
基础设施 所有实验均在最多 256 个 pod 切片的 TPU v4 机器上进行。 对于所有实验模型的训练、评估和推理,我们使用了 SeqIO 和 T5X (Roberts 等人,2022) 框架,这些框架通过集成的顺序数据处理实现跨 TPU 内核的数据和模型并行化。
3.1消融
鉴于迄今为止还没有在参数效率极高的设置中研究 MoE 的工作,我们还试图通过运行严格的消融来了解我们提出的方法的关键特征。 我们简要详细介绍两者以及下面的实验设置:
路由输入:词符 vs 句子嵌入 以指令嵌入形式呈现的任务表示的明显归纳偏差如何影响路由和下游泛化? 在我们的主要 MoV 和 MoLORA 方法中,路由器层将输入 Token 的中间嵌入作为输入,类似于其他 MoE 架构(Shazeer 等人,2017;Fedus 等人,2022)。 然而,作为替代方案,可以为每条指令计算一个句子嵌入(提示相应的输入),并将其用作路由器(Ye等人,2022)的输入。 为了比较两者,每条指令的句子嵌入都是使用 Sentence-T5 编码器 (Ni 等人,2022) 导出的,并使用 T5-XL 检索模型 (Ni 等人,2021)进行训练。 该编码器是根据预训练的 T5 进行初始化的,并根据 Ni 等人 (2022) 中所述的不同数据源进行训练。 在没有额外微调的情况下,传递由提示模板和输入句子组成的每个指令序列来检索维度为768的嵌入。
路由策略:软路由与离散路由 参数高效 MoE 中的最佳路由策略是什么? 在我们的 MoE 框架中,我们使用专家的软合并作为路由策略。 软合并是指在指定路由块内计算的所有专家的加权平均值。 作为替代方案,标准 MoE 架构中使用的离散 top-k 路由策略引入了稀疏性并减少了计算量(Shazeer 等人,2018;Fedus 等人,2022)。 在 top-k 路由方法中,不是考虑所有专家进行决策,而是仅选择由路由器确定的前“k”个专家进行计算。 请注意,虽然计算取决于前 k 个专家,但所需的内存取决于专家的总数。
我们用𝑘={1,2}评估top-k选择,因为它们是由之前的工作(Shazeer等人,2017;Fedus等人,2022)提出的。 4.4 节详细阐述了这些策略的结果。 此外,我们按照Fedus等人(2022)使用负载平衡评估具有top-k的离散路由,通过辅助损失促进平衡的top-k选择,旨在专家之间公平的工作量分配。
4结果与讨论
Zero-shot Results at 3B Scale
| Model | % Params. | ANLI | CB | RTE | WSC | WIC | Copa | WNG | HS | Average | |
| Full-FT | T0-3B (Sanh et al., 2022) | 100% | 33.46 | 50.0 | 64.08 | 64.42 | 50.39 | 74.92 | 50.51 | 27.51 | 51.91 |
| T0-3B (our replication) | 100% | 41.08 | 80.36 | 76.17 | 53.37 | 53.92 | 88.94 | 57.46 | 29.19 | 60.06 | |
| PEFT | (IA)3 | 0.018% | 34.08 | 50.0 | 66.43 | 56.25 | 55.41 | 79.08 | 52.09 | 29.91 | 52.90 |
| LORA | 0.3% | 37.5 | 75.57 | 73.53 | 61.02 | 51.25 | 83.6 | 54.33 | 25.32 | 57.51 | |
| Our Method | MoV-10 | 0.32% | 38.92 | 75.0 | 78.88 | 62.5 | 52.19 | 85.77 | 55.96 | 30.24 | 59.93 |
| MoV-30 | 0.68% | 38.7 | 78.57 | 80.87 | 63.46 | 51.1 | 87.25 | 56.27 | 28.63 | 60.61 | |
| MoV-60 | 1.22% | 38.83 | 76.79 | 74.55 | 60.1 | 52.66 | 89.79 | 55.49 | 30.47 | 59.83 | |
| MoLORA-10 | 3.18% | 38.5 | 78.57 | 78.16 | 63.46 | 50.86 | 86.5 | 55.41 | 26.72 | 59.77 | |
| MoLORA-15 | 4.69% | 40.0 | 80.36 | 80.51 | 62.98 | 50.86 | 89.0 | 55.33 | 27.3 | 60.79 |
表1:使用 T5-3B,针对完整模型微调 (T0)、参数高效参数方法((IA)3 和 LORA)以及我们的参数高效专家组合(MoV 和 MoLORA)在未见任务上的平均中值结果基本模型(Raffel 等人,2020)。 请注意,我们复制的 T0 的性能明显高于原始 T0,这证实了之前的工作(Phang 等人,2023;Ivison 等人,2023)。
Parameter efficient MoEs vs PEFTs How does our MoE recipe compare to a single expert PEFT? Table 4 compares zero-shot performance of PEFTs methods ((IA)3 and LORA), and our variants of parameter-efficient MoE (MoV and MoLORA), using T5-3B as the base model. We observe that our MoE variants (MoV and MoLORA) present a significant performance boost over the standard (IA)3 vectors and LORA adapters.
MoV using 30 experts achieves a 14.57% performance improvement compared to its dense counterpart (IA)3. This improvement is consistent across all unseen tasks and is achieved at a marginal increase in the number of updated parameters – only an additional 0.018% parameters per expert. In the context of LORA, our MoLORA equipped with 15 experts, achieves an average median score increase of 5.70%. This improvement is notably less significant when compared to MoV. We attribute this disparity to the difference in updated parameter count in LORA adapters and (IA)3 vectors (0.3% vs 0.018%). Overall, learning a mixture for both MoV and MoLORA as opposed to a single dense model leads to notable gains in zero-shot performance.
MoV outperforms MoLORA given same parameter budget Between our methods, MoV achieves a better performance-parameter cost trade-off at 3B parameters base model. As shown in the left plot in figure 1 MoV with 30 experts, only updating 0.68% of all parameters, achieves nearly the same performance as MoLORA with 15 experts that updates 4.69% of parameters. This shows the effectiveness of our MoE approaches even with tiny experts at a large base model scale.
Parameter efficient MoEs vs full fine-tuning How does MoE compare to updating all parameters during finetuning? As shown in Table 4 when compared to fully fine-tuned T0-3B, our proposed methods, MoV and MoLORA both with 10 experts, are on par with full fine-tuning. This is impressive as MoV-10 only updates 0.32% of all model parameters. Furthermore, when increasing the number of experts from 10 to 15 and 30 for MoV and MoLORA respectively, our both methods outperform the full fine-tuning by a small margin.
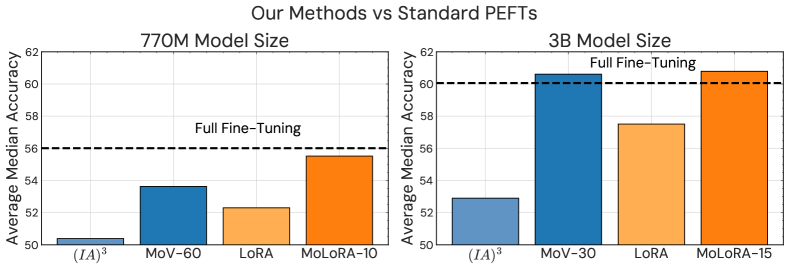
Figure 3:Comparison of the top-performing variants from our proposed mixture of PEFT experts versus their dense counterparts across T5-Large (Left) and T5-XL (Right).
4.1How do parameter-efficient MoEs scale with base model size?
Figure 1 (right) shows the scaling characteristic of MoV with 60 experts compared with (IA)3 and full fine-tuning for 770M, 3B and 11B parameters base models. We find that across all model sizes we evaluate, our parameter-efficient MoEs consistently maintain higher performance compared to standard PEFTs and achieve comparable results with full fine-tuning.
MoV benefits from scaling At all model sizes, MoV-60 significantly outperforms standard (IA)3. It is also far closer in performance to full fine-tuning than a single expert. For example, at 770M parameters, there is a 12.34% performance gap between (IA)3 and full fine-tuning vs 5.56% for MoV-60. As the base model scales up, MoV becomes more competitive with full fine-tuning. For 3B and 11B parameter models, MoV-60 achieves performance approximately on par with the full fine-tuning, despite updating less than 1.3% of the total parameters.
MoLORA outperforms MoV in smaller model size regimes As discussed in the main results, at larger model sizes MoV achieves a better performance-parameter efficiency trade-off compared to MoLORA. Conversely, at the 770M scale, MoLORA with 10 experts that updates 3.18% of total parameters, performs better compared to MoV-60 and nearly matches the performance of full fine-tuning (Figure 3). Finally, similar to MoV, MoLORA archives higher performance than LORA at both 770M and 3B scales.
4.2How does the number of experts impact the downstream performance?
The center plot of Figure 4 shows the performance of MoV with different numbers of experts at all model sizes. We find that increasing the number of experts generally improves unseen task performance. However, this improvement is contingent upon the specific number of experts and the base model size. For both 770M and 11B parameter base models, our MoV method achieves its best performance by using 60 experts. To illustrate, when number of experts is increased from 10 to 60, the average median accuracy improves from 52.47 to 53.63 for the 770M model and from 62.3 to 64.08 for the 11B model. However, for the 3B model, using just 30 experts, updating 0.68% of the parameters, reaches peak accuracy with a score of 60.61 at this scale, as performance stagnates when 60 experts are used.
This trend of performance improvement by scaling more experts is further corroborated in the context of MoLORA; when scaling experts from sets of (5, 10, 15), there was a corresponding elevation in the average median score, registering at 58.6, 59.77, and 60.79, respectively.
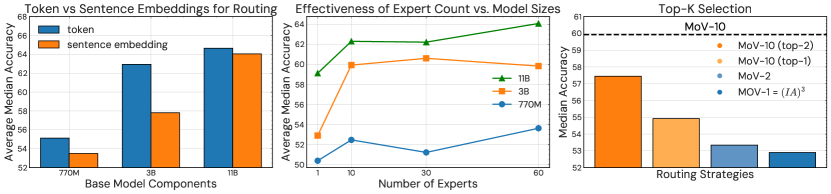
Figure 4:Left: Zero-shot performance of passing embedding of the token sequence to the router vs. passing tokens to the router. Middle: Zero-shot performance across T5 model sizes (Large, XL, XXL) as the number of experts increases. Right: The effectiveness of activating top-k experts.
4.3What is the best routing strategy in parameter-efficient MoEs?
In Figure 4, the rightmost plot shows the overall unseen task performance when using different routing strategies for MoV. Specifically, we compare the soft merging of 10 experts (dashed line) with discrete top-2 and top-1 routing. We observe that soft merging significantly outperforms discrete routing in the MoV-10 setting. Specifically, for discrete routing with top-k experts, where k is 1 and 2, the MoE achieves an average median accuracy of 54.92 and 57.45 respectively. In contrast, using the soft merging approach, where all experts are activated, we observe an accuracy of 59.93.
Furthermore, to understand if we recover the performance loss of top-k routing by using load balancing, we integrated the loss balancing following to Fedus et al. (2022). However, we find that the top-k selection of 𝑘=2 with load balancing loss leads to a further decrease in performance 1.5 average median score.
Together, these results show that in extremely parameter-efficient MoE settings, soft merging enables superior performance. Note that top-2 and top-1 routing strategies (among 10 experts) perform better than MoV with only 2 experts and a single expert (IA)3 respectively, showing that soft merging performs better when a larger number of experts are used.
4.4Does a pronounced task information in routing lead to higher performance?
To understand the effects of a pronounced inductive bias towards task representations in our MoE framework, we compare using sentence embeddings of instructions with token embeddings for the routing input. These sentence embeddings are obtained offline using an external sentence embedding model. Here, we aim to evaluate how pronounced task information affects the router’s decision and the subsequent generalization capabilities of the model in downstream tasks. Figure 4 leftmost plot shows performances of token routing and sentence routing at all model sizes. We find that the token routing exhibits superior performance with 3.03%, 8.86%, and 0.94% improvement for 770M, 3B, and 11B base model sizes respectively. These results suggest that a higher degree of inductive bias for task datasets is not necessarily beneficial as our approaches can acquire a diverse set of task knowledge directly from the hidden representations of tokens. Furthermore, token routing enables the use of learned experts and routing layers without any prior task information for unseen tasks.
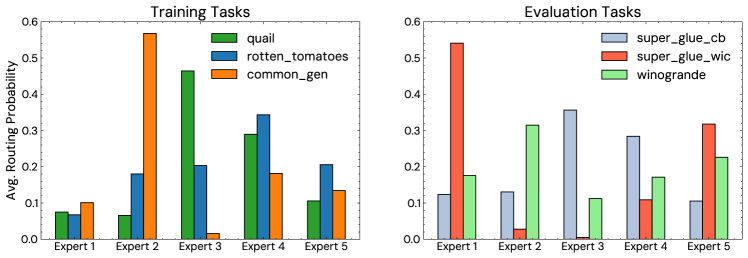
Figure 5:Mean expert routing probabilities for intermediates activations at the last feedforward layer. Values are averaged across tokens and batch. Experts are weighted differently in soft merging depending on the task. Left: Measured on tasks seen during training. Right: Measured on unseen evaluation tasks.
4.5Do experts specialize in diverse knowledge across different tasks?
To understand how expert routing differs for different tasks, we take a closer look at how experts are activated for a variety of tasks. Figure 5 shows the mean expert probabilities for MoV with 5 experts that are located in feed-forward layers in the last decoder block at 770M parameter T5 model. We selected the last decoder block as it has been shown deeper layers learn more task-specific information (Rogers et al., 2020). We plot the mean routing probabilities for both training tasks and evaluation tasks that are unseen during training, to understand cross-task generalization through the lens of experts if skills learned at training time generalize to unseen tasks at evaluation time. Intuitively, if experts have indeed learned different skills, we expect that they contribute in different degrees to tasks that are different in nature. The amount of contribution is directly reflected in the routing probability of each expert since we use soft merging i.e. summation of expert vectors weighted by the routing probability as described in Figure 2. As such, the mean routing probabilities plotted in Figure 5 provide an overall picture of the contribution of each expert, depending on the downstream task.
Specialization across unseen vs seen tasks As depicted in Figure 5, both evaluation and training tasks lead to the activation of experts at different magnitudes. For example, both quail and super_glue_cb activate Expert 3 the most out of the 5 experts, followed by Expert 4 but are different both in terms of the relative contribution of each expert and the ordering of the remaining 3 experts based on routing probability. A similar pattern can be observed for common_gen & winogrande as they both activate Expert 2 the most but are otherwise different. Overall, the fact that routing specialization seems to occur regardless of whether the downstream task was trained on, suggests that expert specialization is inherent and transferable from seen tasks to unseen tasks.
4.6Hyper-parameters Sensitivity
Given the widely documented sensitivity of MoE-style architecture to hyperparameters (Fedus et al., 2022; Shazeer et al., 2017), we ran extensive ablation studies to uncover the idiosyncrasy of PEFT methods in the context of MoE. We experimented with batch sizes of 32, 128, 256, and 2048 and we found that the larger the batch size, the more likely our MoEs to collapse to a single expert. Our empirical finding resonates with Shen et al. (2023) which also finds that a small batch is necessary for stable training. For instance, by experimenting with a batch size of 2048 and evaluating every 5K steps up to 20K, we observed that the performance of our parameter-efficient MoEs deteriorates after 5K steps, converging to performance levels akin to their dense counterparts. Additionally, we experimented with varying learning rates from 3𝑒−3 to 6𝑒−4 where we discovered for our methods, a smaller learning rate of 3𝑒−4 leads to higher performance relative to their dense PEFT counterpart and full fine-tuning. Smaller learning rates stabilize training in parameter-efficient experts by preventing rapid, imbalanced updates that can suppress diversity and lead to suboptimal solutions.
5Related Work
Mixture-of-Experts The Mixture-of-Experts (MoE) has been investigated thoroughly in Natural Language Processing (Lou et al., 2022; Mustafa et al., 2022; Shazeer et al., 2017; Lepikhin et al., 2020; Fedus et al., 2022; Du et al., 2022; Zoph et al., 2022; Clark et al., 2022; Zhou et al., 2022; Komatsuzaki et al., 2023; Kudugunta et al., 2021; Zuo et al., 2022) as an effective way of increasing the model’s capacity in parameter size where certain parts of the model are activated while computation is kept the same or close to its dense counterpart. In the context of MoE, there is a body of work focusing on improving the routing (Hazimeh et al., 2021; Lewis et al., 2021; Roller et al., 2021; Zhou et al., 2022) including random routing (Zuo et al., 2022) activating all expert through weighted average (Eigen et al., 2014) to sparsely select a single or 𝑘 experts (Fedus et al., 2022; Du et al., 2022). MoE has also been invested in multi-task settings including multilingual neural machine translation(Hazimeh et al., 2021; Kudugunta et al., 2021). Unlike these studies, our research addresses MoE by scaling both the volume of data and the number of tasks, aiming to mitigate the instability inherent in training the MoE models. But our primary emphasis remains on achieving efficient fine-tuning. Recently, Shen et al. (2023) highlighted how instruction fine-tuning with scaled tasks can counteract the generalization challenges tied to MoE models. In distinction from this, our study scrutinizes the efficacy of instruction fine-tuning in the MoE domain, specifically concentrating on a unique ensemble of the PEFT components, considering the memory cost of the traditional MoE can be prohibitive for many practitioners. Similar to the aforementioned work, Ye et al. (2022) utilized MoE in a multi-task context, employing BART Lewis et al. (2019) as their pre-trained model. However, they limited their experimental scope to a smaller scale and used replicas of each transformer layer as experts, simply multiplying the model by the number of experts. Our work, on the other hand, presents an extreme parameter efficiency with small experts at a large scale up to 11B parameter base model.
Instruction Tuning Instruction tuning, as elucidated in (Sanh et al., 2022; Wei et al., 2022; Mishra et al., 2022), is a technique where a language model is fine-tuned over a collection of tasks using paired prompts and responses. The primary goal of this technique is to enable the model to predict responses accurately based on the provided prompts, thereby augmenting its ability to understand and execute instructions effectively. The method has gained considerable attention due to its pronounced success in enhancing zero-shot performance on tasks to which the model has not been previously exposed. Additionally, instruction tuning has led to breakthroughs such as Chain of Thought Prompting (Wei et al., 2023) where a breakdown of complex problems into smaller steps to produce intermediate reasoning along with the final solution, PaLM (Chowdhery et al., 2022), FLAN (Wei et al., 2022). In our work, we explore the use of instruction fine-tuning with the intention of harnessing its benefits that enable the model to learn from a diverse set of inputs where the mixture of expert style models suits well, for enhanced evaluation performance on unseen tasks. Our objective remains to optimize computational efficiency without compromising zero-shot performance.
Parameter-Efficient Fine-tuning. Houlsby et al. (2019) established "adapters" in the NLP domain to fine-tune BERT. There are many variants of adapters with different design choices (Bapna et al., 2019; Pfeiffer et al., 2021). Li & Liang (2021) proposed updating soft prompts concatenated to embeddings or layer outputs instead of adapters. Zaken et al. (2022) show that just updating only a small subset of parameters during fine-tuning (e.g. just biases) is very effective. Hu et al. (2021) proposed LORA based on low-rank decomposition matrices of transformer layers. They show superior performance with a smaller parameter budget and no inference cost as LORA parameters can be applied offline to the baseline model. Liu et al. (2022) proposed (𝐼𝐴)3, task-specific vectors to modify attention activation. Instead of using feedforward layers inserted in transformer layers as adapters, they learn vectors to update (by broadcast multiplication) key, value, and linear layer weight matrices. Unlike the other PEFT methods, (IA)3 does not induce any additional inference cost and enables mix-batches (from different datasets). The multiplicative nature of the (IA)3 creates an interesting opportunity for the mixture-of-expert type of modeling without parallelization overhead. Chen et al. (2023) experiment with different design spaces (essentially a hyperparameter search) for PEFT. They suggest four phases: 1) grouping layers into different sets; 2) adding trainable parameters towards each group; 3) deciding which group should be trained; 4) assigning groups with different training strategies. Their finding is that different architectures have different best settings. We have chosen (𝐼𝐴)3 and LORA as our PEFT components because they offer an optimal balance between performance and parameter efficiency (Mahabadi et al., 2021; Liu et al., 2022).
Several studies have explored PEFT in the context of MoE or in a similar fashion, albeit with certain distinctions. For instance, Wang et al. (2022) focused on single-task fine-tuning employing a mixture of adapters for BERTbase with 110M parameters (Devlin et al., 2019) and 𝑅𝑜𝐵𝐸𝑅𝑇𝑎𝑙𝑎𝑟𝑔𝑒 with 355M parameters (Liu et al., 2019), incorporating random routing, and adopting a few-shot evaluation. In divergence from this, our work centers on instruction-tuning with multiple tasks present during fine-tuning. We underscore the efficacy of this approach by rigorously testing up to 11B parameter text-to-text model Raffel et al. (2020), implementing token routing, and strictly emphasizing evaluation on a set of unseen (held-out) tasks to underscore the potential of instruction tuning. In another work, Ponti et al. (2022) introduced Polytropon, which involves learning adapters (termed as ’skills’) specific to each task and employing a task-skills binary matrix to determine the skill set associated with each task. In their method, input examples dictate the selection of adapters. These adapters are then aggregated, and the resultant single adapter is integrated into the overall architecture. Extending upon the Polytropon framework, Caccia et al. (2023) implemented a distinct skill set for every layer in their variant named Polytropon-S. They introduce a deterministic routing function, delve into supplementary inductive biases, show effectiveness up to 3B models, and they don’t employ MoE style architecture. Our research presents a departure from these two studies. Specifically, our primary experimental setup employs MoEs that do not require any specific task identifier during fine-tuning by the use of their token routing strategy. In this way, we can evaluate our instruction-tuned MoEs on unseen tasks without any further task-specific few-shot fine-tuning. We showed the scaling property of our MoEs in this setting by fine-tuning models up to 11B parameters.
6Conclusion
This work introduces MoEs in an extremely computationally limited environment. We propose introduce the Mixture of Vectors (MoV) and Mixture of LoRA (MoLORA) to mitigate the challenges associated with scaling instruction-tuned LLMs at scale. Our method outperforms parameter-efficient techniques and achieves performance parity with full fine-tuning on unseen tasks by updating less than 1% of the 3B and 11B model parameters. This percentage may vary depending on the base model size and the number of experts involved. Our extensive experiments, including rigorous ablations across model sizes, representation of tokens vs embeddings, soft vs top-k routing, confirm the effectiveness of our approach across diverse unseen tasks, highlighting its superior accuracy and computational efficiency. Furthermore, our framework’s versatility seamlessly integrates with other parameter-efficient strategies and remains compatible with efficiency-enhancing techniques such as quantization.
Limitations A primary constraint of our experimental framework is its focus on text-to-text models, such as T5, without extending the evaluation to decoder-only such as GPT style models. We leave this as the subject of future work. Additionally, our assessment is exclusively within the context of fine-tuning. Exploration of its efficacy during the pre-training phase remains an avenue for future research.
References
- Anil et al. (2023)Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernandez Abrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vlad Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, Guy Gur-Ari, Steven Hand, Hadi Hashemi, Le Hou, Joshua Howland, Andrea Hu, Jeffrey Hui, Jeremy Hurwitz, Michael Isard, Abe Ittycheriah, Matthew Jagielski, Wenhao Jia, Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Music Li, Wei Li, YaGuang Li, Jian Li, Hyeontaek Lim, Hanzhao Lin, Zhongtao Liu, Frederick Liu, Marcello Maggioni, Aroma Mahendru, Joshua Maynez, Vedant Misra, Maysam Moussalem, Zachary Nado, John Nham, Eric Ni, Andrew Nystrom, Alicia Parrish, Marie Pellat, Martin Polacek, Alex Polozov, Reiner Pope, Siyuan Qiao, Emily Reif, Bryan Richter, Parker Riley, Alex Castro Ros, Aurko Roy, Brennan Saeta, Rajkumar Samuel, Renee Shelby, Ambrose Slone, Daniel Smilkov, David R. So, Daniel Sohn, Simon Tokumine, Dasha Valter, Vijay Vasudevan, Kiran Vodrahalli, Xuezhi Wang, Pidong Wang, Zirui Wang, Tao Wang, John Wieting, Yuhuai Wu, Kelvin Xu, Yunhan Xu, Linting Xue, Pengcheng Yin, Jiahui Yu, Qiao Zhang, Steven Zheng, Ce Zheng, Weikang Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu.Palm 2 technical report, 2023.
- Bapna et al. (2019)Ankur Bapna, Naveen Arivazhagan, and Orhan Firat.Simple, scalable adaptation for neural machine translation, 2019.
- Brown et al. (2020)Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei.Language models are few-shot learners, 2020.
- Caccia et al. (2023)Lucas Caccia, Edoardo Ponti, Zhan Su, Matheus Pereira, Nicolas Le Roux, and Alessandro Sordoni.Multi-head adapter routing for cross-task generalization, 2023.
- Chen et al. (2023)Jiaao Chen, Aston Zhang, Xingjian Shi, Mu Li, Alex Smola, and Diyi Yang.Parameter-efficient fine-tuning design spaces, 2023.
- Chen et al. (2022)Zixiang Chen, Yihe Deng, Yue Wu, Quanquan Gu, and Yuanzhi Li.Towards understanding the mixture-of-experts layer in deep learning.In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems, 2022.URL Towards Understanding the Mixture-of-Experts Layer in Deep Learning | OpenReview.
- Chowdhery et al. (2022)Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel.Palm: Scaling language modeling with pathways, 2022.
- Chung et al. (2022)Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei.Scaling instruction-finetuned language models, 2022.
- Clark et al. (2022)Aidan Clark, Diego de las Casas, Aurelia Guy, Arthur Mensch, Michela Paganini, Jordan Hoffmann, Bogdan Damoc, Blake Hechtman, Trevor Cai, Sebastian Borgeaud, George van den Driessche, Eliza Rutherford, Tom Hennigan, Matthew Johnson, Katie Millican, Albin Cassirer, Chris Jones, Elena Buchatskaya, David Budden, Laurent Sifre, Simon Osindero, Oriol Vinyals, Jack Rae, Erich Elsen, Koray Kavukcuoglu, and Karen Simonyan.Unified scaling laws for routed language models, 2022.
- Devlin et al. (2019)Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova.Bert: Pre-training of deep bidirectional transformers for language understanding, 2019.
- Du et al. (2022)Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathleen Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V Le, Yonghui Wu, Zhifeng Chen, and Claire Cui.Glam: Efficient scaling of language models with mixture-of-experts, 2022.
- Eigen et al. (2014)David Eigen, Marc’Aurelio Ranzato, and Ilya Sutskever.Learning factored representations in a deep mixture of experts, 2014.
- Fedus et al. (2022)William Fedus, Barret Zoph, and Noam Shazeer.Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022.
- Hazimeh et al. (2021)Hussein Hazimeh, Zhe Zhao, Aakanksha Chowdhery, Maheswaran Sathiamoorthy, Yihua Chen, Rahul Mazumder, Lichan Hong, and Ed H. Chi.Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning, 2021.
- Houlsby et al. (2019)Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly.Parameter-efficient transfer learning for nlp, 2019.
- Hu et al. (2021)Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen.Lora: Low-rank adaptation of large language models, 2021.
- Ivison et al. (2023)Hamish Ivison, Akshita Bhagia, Yizhong Wang, Hannaneh Hajishirzi, and Matthew E Peters.Hint: Hypernetwork instruction tuning for efficient zero-and few-shot generalisation.In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 11272–11288, 2023.
- Kaplan et al. (2020)Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei.Scaling laws for neural language models, 2020.
- Kingma & Ba (2017)Diederik P. Kingma and Jimmy Ba.Adam: A method for stochastic optimization, 2017.
- Komatsuzaki et al. (2023)Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby.Sparse upcycling: Training mixture-of-experts from dense checkpoints, 2023.
- Kudugunta et al. (2021)Sneha Kudugunta, Yanping Huang, Ankur Bapna, Maxim Krikun, Dmitry Lepikhin, Minh-Thang Luong, and Orhan Firat.Beyond distillation: Task-level mixture-of-experts for efficient inference, 2021.
- Lepikhin et al. (2020)Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen.Gshard: Scaling giant models with conditional computation and automatic sharding, 2020.
- Lester et al. (2021)Brian Lester, Rami Al-Rfou, and Noah Constant.The power of scale for parameter-efficient prompt tuning, 2021.
- Lewis et al. (2019)Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer.Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension, 2019.
- Lewis et al. (2021)Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer.Base layers: Simplifying training of large, sparse models.In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 6265–6274. PMLR, 18–24 Jul 2021.URL BASE Layers: Simplifying Training of Large, Sparse Models.
- Li & Liang (2021)Xiang Lisa Li and Percy Liang.Prefix-tuning: Optimizing continuous prompts for generation, 2021.
- Liu et al. (2022)Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel.Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning, 2022.
- Liu et al. (2019)Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov.Roberta: A robustly optimized bert pretraining approach, 2019.
- Longpre et al. (2023)Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V. Le, Barret Zoph, Jason Wei, and Adam Roberts.The flan collection: Designing data and methods for effective instruction tuning, 2023.
- Loshchilov & Hutter (2019)Ilya Loshchilov and Frank Hutter.Decoupled weight decay regularization, 2019.
- Lou et al. (2022)Yuxuan Lou, Fuzhao Xue, Zangwei Zheng, and Yang You.Cross-token modeling with conditional computation, 2022.
- Mahabadi et al. (2021)Rabeeh Karimi Mahabadi, Sebastian Ruder, Mostafa Dehghani, and James Henderson.Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks, 2021.
- Mishra et al. (2022)Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi.Cross-task generalization via natural language crowdsourcing instructions, 2022.
- Muennighoff et al. (2023)Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, and Colin Raffel.Crosslingual generalization through multitask finetuning, 2023.
- Muqeeth et al. (2023)Mohammed Muqeeth, Haokun Liu, and Colin Raffel.Soft merging of experts with adaptive routing, 2023.
- Mustafa et al. (2022)Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby.Multimodal contrastive learning with limoe: the language-image mixture of experts, 2022.
- Ni et al. (2021)Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernández Ábrego, Ji Ma, Vincent Y. Zhao, Yi Luan, Keith B. Hall, Ming-Wei Chang, and Yinfei Yang.Large dual encoders are generalizable retrievers, 2021.
- Ni et al. (2022)Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang.Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models.In Findings of the Association for Computational Linguistics: ACL 2022, pp. 1864–1874, 2022.
- Nie et al. (2020)Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela.Adversarial nli: A new benchmark for natural language understanding, 2020.
- Pfeiffer et al. (2021)Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych.Adapterfusion: Non-destructive task composition for transfer learning, 2021.
- Phang et al. (2023)Jason Phang, Yi Mao, Pengcheng He, and Weizhu Chen.Hypertuning: Toward adapting large language models without back-propagation.In International Conference on Machine Learning, pp. 27854–27875. PMLR, 2023.
- Ponti et al. (2022)Edoardo M. Ponti, Alessandro Sordoni, Yoshua Bengio, and Siva Reddy.Combining modular skills in multitask learning, 2022.
- Raffel et al. (2020)Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.Exploring the limits of transfer learning with a unified text-to-text transformer, 2020.
- Riquelme et al. (2021)Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby.Scaling vision with sparse mixture of experts.Advances in Neural Information Processing Systems, 34:8583–8595, 2021.
- Roberts et al. (2022)Adam Roberts, Hyung Won Chung, Anselm Levskaya, Gaurav Mishra, James Bradbury, Daniel Andor, Sharan Narang, Brian Lester, Colin Gaffney, Afroz Mohiuddin, Curtis Hawthorne, Aitor Lewkowycz, Alex Salcianu, Marc van Zee, Jacob Austin, Sebastian Goodman, Livio Baldini Soares, Haitang Hu, Sasha Tsvyashchenko, Aakanksha Chowdhery, Jasmijn Bastings, Jannis Bulian, Xavier Garcia, Jianmo Ni, Andrew Chen, Kathleen Kenealy, Jonathan H. Clark, Stephan Lee, Dan Garrette, James Lee-Thorp, Colin Raffel, Noam Shazeer, Marvin Ritter, Maarten Bosma, Alexandre Passos, Jeremy Maitin-Shepard, Noah Fiedel, Mark Omernick, Brennan Saeta, Ryan Sepassi, Alexander Spiridonov, Joshua Newlan, and Andrea Gesmundo.Scaling up models and data with t5x and seqio.arXiv preprint arXiv:2203.17189, 2022.URL https://arxiv.org/abs/2203.17189.
- Rogers et al. (2020)Anna Rogers, Olga Kovaleva, and Anna Rumshisky.A primer in bertology: What we know about how bert works, 2020.
- Roller et al. (2021)Stephen Roller, Sainbayar Sukhbaatar, Arthur Szlam, and Jason Weston.Hash layers for large sparse models, 2021.
- Sakaguchi et al. (2019)Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi.Winogrande: An adversarial winograd schema challenge at scale, 2019.
- Sanh et al. (2022)Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Tali Bers, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M. Rush.Multitask prompted training enables zero-shot task generalization, 2022.
- Shazeer & Stern (2018)Noam Shazeer and Mitchell Stern.Adafactor: Adaptive learning rates with sublinear memory cost.In International Conference on Machine Learning, pp. 4596–4604. PMLR, 2018.
- Shazeer et al. (2017)Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean.Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017.
- Shazeer et al. (2018)Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, Ryan Sepassi, and Blake Hechtman.Mesh-tensorflow: Deep learning for supercomputers, 2018.
- Shen et al. (2023)Sheng Shen, Le Hou, Yanqi Zhou, Nan Du, Shayne Longpre, Jason Wei, Hyung Won Chung, Barret Zoph, William Fedus, Xinyun Chen, Tu Vu, Yuexin Wu, Wuyang Chen, Albert Webson, Yunxuan Li, Vincent Zhao, Hongkun Yu, Kurt Keutzer, Trevor Darrell, and Denny Zhou.Mixture-of-experts meets instruction tuning:a winning combination for large language models, 2023.
- Touvron et al. (2023)Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample.Llama: Open and efficient foundation language models, 2023.
- Vaswani et al. (2023)Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin.Attention is all you need, 2023.
- Wang et al. (2020)Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman.Superglue: A stickier benchmark for general-purpose language understanding systems, 2020.
- Wang et al. (2022)Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao.Adamix: Mixture-of-adaptations for parameter-efficient model tuning, 2022.
- Wei et al. (2022)Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le.Finetuned language models are zero-shot learners, 2022.
- Wei et al. (2023)Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou.Chain-of-thought prompting elicits reasoning in large language models, 2023.
- Ye et al. (2022)Qinyuan Ye, Juan Zha, and Xiang Ren.Eliciting and understanding cross-task skills with task-level mixture-of-experts, 2022.
- Zaken et al. (2022)Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg.Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models, 2022.
- Zellers et al. (2019)Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi.Hellaswag: Can a machine really finish your sentence?, 2019.
- Zhou et al. (2022)Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew Dai, Zhifeng Chen, Quoc Le, and James Laudon.Mixture-of-experts with expert choice routing, 2022.
- Zoph et al. (2022)Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus.St-moe: Designing stable and transferable sparse expert models, 2022.
- Zuo et al. (2022)Simiao Zuo, Xiaodong Liu, Jian Jiao, Young Jin Kim, Hany Hassan, Ruofei Zhang, Tuo Zhao, and Jianfeng Gao.Taming sparsely activated transformer with stochastic experts, 2022.
AFull Experimental Results
A.1Zero-Shot Evaluation for P3 dataset
In our study, we conducted a comprehensive evaluation of the variants of our proposed methods in comparison to our established baselines. This evaluation encompassed various sizes of the T5 model, specifically 770M, 3B, and 11B. Both mean and median scores were reported for every evaluation set derived from the P3 dataset, which covers a range of tasks. For further details and a more in-depth exploration, please refer to the following URL: https://huggingface.co/datasets/bigscience/P3.
T5-Large (770M)
| Model | % Params. | Metric | ANLI | CB | RTE | WSC | WIC | Copa | WNG | HS | Average | |
| Full-FT | T0-770M (ours) | 100% | median | 35.6 | 71.43 | 75.63 | 57.21 | 51.41 | 77.0 | 53.04 | 26.78 | 56.01 |
| mean | 35.57 | 57.74 | 75.88 | 52.31 | 52.52 | 74.6 | 52.93 | 26.74 | 53.54 | |||
| PEFT | (IA)3 | 0.036% | median | 33.5 | 42.86 | 67.87 | 62.02 | 52.35 | 67.0 | 51.22 | 26.33 | 50.39 |
| mean | 33.27 | 45.12 | 67.08 | 58.17 | 52.74 | 66.63 | 51.35 | 26.32 | 50.09 | |||
| LoRA | 0.497% | median | 35.0 | 55.36 | 57.4 | 63.46 | 50.24 | 77.0 | 53.28 | 26.67 | 52.3 | |
| mean | 35.26 | 51.67 | 59.35 | 62.98 | 50.66 | 76.5 | 52.41 | 27.24 | 52.0 | |||
| Our Method | MOV-5 | 0.27% | median | 33.6 | 41.07 | 71.48 | 61.54 | 50.86 | 76.5 | 51.46 | 26.02 | 51.57 |
| mean | 33.51 | 42.62 | 71.26 | 60.96 | 51.14 | 73.8 | 51.55 | 26.01 | 51.36 | |||
| MoV-10 | 0.55% | median | 33.9 | 42.86 | 74.19 | 62.5 | 50.31 | 77.0 | 52.64 | 26.34 | 52.47 | |
| mean | 33.68 | 42.38 | 74.51 | 59.23 | 50.74 | 74.82 | 52.2 | 26.72 | 51.78 | |||
| MoV-20 | 1.10% | median | 33.7 | 41.07 | 73.83 | 63.46 | 50.94 | 75.46 | 51.14 | 25.48 | 51.89 | |
| mean | 33.98 | 45.12 | 73.36 | 59.13 | 51.33 | 73.47 | 51.3 | 25.45 | 51.64 | |||
| MoV-30 | 1.66% | median | 33.75 | 41.07 | 72.92 | 55.77 | 51.25 | 77.0 | 51.46 | 26.55 | 51.22 | |
| mean | 33.81 | 44.88 | 72.56 | 56.15 | 51.29 | 77.43 | 51.81 | 26.52 | 51.81 | |||
| MoV-60 | 3.32% | median | 34.0 | 53.57 | 75.81 | 57.69 | 50.55 | 77.96 | 53.12 | 26.33 | 53.63 | |
| mean | 34.24 | 52.26 | 75.02 | 58.37 | 50.78 | 77.06 | 52.87 | 26.74 | 53.42 | |||
| MoLoRA-10 | 5.60% | median | 33.2 | 67.86 | 68.41 | 64.9 | 50.39 | 80.0 | 52.64 | 52.64 | 55.52 | |
| mean | 33.37 | 56.31 | 68.88 | 63.37 | 51.55 | 79.35 | 52.31 | 52.31 | 53.99 |
Table 2:Zero-shot evaluation of the 770M parameter model across all unseen tasks, comparing different numbers of experts for both MoV and MoLoRA.
T5-XL (3B)
| Model | % Params. | Metric | ANLI | CB | RTE | WSC | WIC | Copa | WNG | HS | Average | |
| Full-FT | T0-3B (Sanh et al., 2022) | 100% | median | 33.46 | 50.0 | 64.08 | 64.42 | 50.39 | 74.92 | 50.51 | 27.51 | 51.91 |
| mean | 33.42 | 45.36 | 64.55 | 65.10 | 50.69 | 72.40 | 50.97 | 27.29 | 51.22 | |||
| T0-3B (our replication) | 100% | median | 41.08 | 80.36 | 76.17 | 53.37 | 53.92 | 88.94 | 57.46 | 29.19 | 60.06 | |
| mean | 40.73 | 74.52 | 76.82 | 52.21 | 53.84 | 88.99 | 56.83 | 29.2 | 59.14 | |||
| PEFT | (IA)3 | 0.018% | median | 34.08 | 50.0 | 66.43 | 56.25 | 55.41 | 79.08 | 52.09 | 29.91 | 52.90 |
| mean | 34.56 | 51.07 | 68.38 | 54.9 | 55.61 | 78.23 | 52.14 | 28.97 | 52.98 | |||
| LoRA | 0.3% | median | 37.5 | 75.57 | 73.53 | 61.02 | 51.25 | 83.6 | 54.33 | 25.32 | 57.51 | |
| mean | 37.85 | 66.9 | 77.04 | 56.73 | 52.29 | 82.83 | 55.64 | 26.79 | 57.01 | |||
| Our Method | MoV-2 | 0.18% | median | 34.7 | 46.43 | 66.06 | 56.25 | 54.86 | 85.42 | 53.75 | 29.25 | 53.34 |
| mean | 35.14 | 50.36 | 69.31 | 56.15 | 54.4 | 83.79 | 53.69 | 28.47 | 53.91 | |||
| MoV-5 | 0.23% | median | 37.1 | 76.79 | 78.16 | 57.69 | 52.27 | 86.77 | 53.99 | 29.31 | 59.01 | |
| mean | 37.66 | 62.14 | 78.3 | 58.46 | 53.54 | 86.52 | 54.54 | 28.3 | 57.43 | |||
| MoV-10 | 0.32% | median | 38.92 | 75.0 | 78.88 | 62.5 | 52.19 | 85.77 | 55.96 | 30.24 | 59.93 | |
| mean | 38.83 | 63.45 | 79.49 | 60.19 | 53.04 | 86.41 | 56.27 | 29.11 | 58.35 | |||
| MoV-20 | 0.50% | median | 39.2 | 75.0 | 76.71 | 57.69 | 53.45 | 89.0 | 55.64 | 30.89 | 59.7 | |
| mean | 39.25 | 64.05 | 76.53 | 56.63 | 53.45 | 86.93 | 56.24 | 29.36 | 57.81 | |||
| MoV-30 | 0.68% | median | 38.7 | 78.57 | 80.87 | 63.46 | 51.1 | 87.25 | 56.27 | 28.63 | 60.61 | |
| mean | 38.9 | 67.5 | 81.23 | 59.9 | 52.43 | 86.28 | 56.39 | 27.57 | 58.77 | |||
| MoV-60 | 1.22% | median | 38.83 | 76.79 | 74.55 | 60.1 | 52.66 | 89.79 | 55.49 | 30.47 | 59.83 | |
| mean | 38.97 | 63.93 | 75.38 | 57.79 | 53.5 | 86.04 | 55.88 | 29.28 | 57.59 | |||
| MoV-10 (top-1) | 0.32% | median | 33.9 | 75.0 | 71.12 | 61.06 | 50.71 | 70.0 | 51.7 | 25.89 | 54.92 | |
| mean | 34.31 | 60.6 | 71.41 | 58.94 | 51.24 | 68.39 | 51.79 | 25.98 | 52.82 | |||
| MoV-10 (top-2) | 0.32% | median | 38.7 | 82.14 | 75.63 | 48.08 | 53.68 | 79.88 | 54.14 | 27.37 | 57.45 | |
| mean | 38.89 | 69.76 | 74.95 | 47.69 | 53.51 | 79.89 | 53.83 | 26.91 | 55.67 | |||
| MoLORA-2 | 0.75% | median | 39.2 | 82.14 | 80.32 | 62.5 | 50.39 | 80.58 | 57.38 | 28.47 | 60.12 | |
| mean | 38.86 | 65.71 | 80.0 | 60.0 | 50.8 | 82.17 | 56.51 | 28.03 | 57.76 | |||
| MoLORA-5 | 1.66% | median | 36.75 | 71.43 | 79.96 | 56.25 | 55.17 | 85.81 | 55.8 | 27.63 | 58.6 | |
| mean | 37.52 | 62.14 | 80.22 | 52.6 | 55.34 | 84.05 | 56.04 | 26.62 | 56.82 | |||
| MoLORA-10 | 3.18% | median | 38.5 | 78.57 | 78.16 | 63.46 | 50.86 | 86.5 | 55.41 | 26.72 | 59.77 | |
| mean | 38.49 | 66.43 | 77.44 | 59.9 | 51.63 | 84.96 | 56.1 | 26.7 | 57.71 | |||
| MoLORA-15 | 4.69% | median | 40.0 | 80.36 | 80.51 | 62.98 | 50.86 | 89.0 | 55.33 | 27.3 | 60.79 | |
| mean | 39.73 | 69.52 | 80.97 | 60.67 | 51.54 | 86.5 | 55.03 | 27.25 | 58.9 |
Table 3:In our most comprehensive experimental setup, we conducted a zero-shot evaluation across all unseen tasks using a 3B parameter model. We compared varying numbers of experts for both MoV and MoLoRA and experimented with a top-k selection routing strategy
T5-XXL (11B)
| Model | % Params. | Metric | ANLI | CB | RTE | WSC | WIC | Copa | WNG | HS | Average | |
| Full-FT | T0-11B (Sanh et al., 2022) | 100% | median | 42.17 | 78.57 | 81.23 | 64.42 | 57.21 | 90.79 | 60.46 | 33.65 | 63.56 |
| mean | 41.16 | 70.12 | 80.83 | 61.45 | 56.58 | 90.02 | 59.94 | 33.58 | 61.70 | |||
| T0-11B (our replication) | 100% | median | 47.1 | 80.36 | 81.41 | 60.1 | 56.27 | 96.08 | 67.32 | 31.61 | 65.03 | |
| mean | 45.83 | 72.62 | 81.52 | 58.17 | 56.66 | 96.0 | 66.77 | 30.95 | 63.57 | |||
| PEFT | (IA)3 | 0.0098% | median | 42.3 | 73.21 | 75.99 | 58.65 | 52.04 | 86.27 | 54.3 | 30.27 | 59.12 |
| mean | 42.1 | 63.27 | 75.31 | 55.49 | 52.27 | 85.74 | 55.06 | 30.09 | 57.41 | |||
| Our Method | MoV-10 | 0.143% | median | 45.83 | 76.79 | 78.52 | 53.85 | 51.88 | 94.23 | 63.77 | 33.5 | 62.3 |
| mean | 44.73 | 70.12 | 78.88 | 54.23 | 53.26 | 93.64 | 63.57 | 33.59 | 61.5 | |||
| MoV-20 | 0.287% | median | 44.58 | 76.79 | 73.83 | 55.77 | 52.98 | 95.0 | 62.27 | 32.92 | 61.77 | |
| mean | 43.54 | 69.17 | 74.4 | 52.88 | 54.5 | 93.93 | 62.95 | 32.85 | 60.53 | |||
| MoV-30 | 0.431% | median | 43.6 | 76.79 | 77.62 | 56.73 | 53.84 | 93.62 | 64.25 | 31.34 | 62.22 | |
| mean | 43.32 | 69.29 | 77.22 | 53.56 | 56.03 | 93.65 | 63.52 | 31.32 | 60.99 | |||
| MoV-60 | 0.862% | median | 45.17 | 75.0 | 83.03 | 60.1 | 53.68 | 95.42 | 65.82 | 34.38 | 64.08 | |
| mean | 43.9 | 69.88 | 83.07 | 56.54 | 54.51 | 94.01 | 64.56 | 34.17 | 62.58 |
Table 4:We evaluated the largest available model size from the original T5 pre-trained checkpoint, T5-XXL with 11B parameters, to demonstrate the efficacy of our proposed mixture of PEFT experts at this scale.
A.2Token vs. Sentence Embeddings for Routing
We present the mean and median results for our routing strategies. Specifically, we assessed performance by either passing tokens directly to the router or by passing sentence embeddings. Our findings indicate that, particularly for the T5-XL(3B) model, token routing consistently yields better performance in terms of both mean and median values. The Anli dataset is excluded from our embedding dataset.
MoV – Token vs. Sentence Embedding
| Model | Metric | CB | RTE | WSC | WIC | Copa | WNG | HS | Average |
| MoV-10 (Token) - 770M | median | 42.86 | 74.19 | 62.5 | 52.64 | 52.64 | 77.0 | 26.34 | 55.12 |
| mean | 42.38 | 74.51 | 59.23 | 52.2 | 52.2 | 74.82 | 26.72 | 54.37 | |
| MoV-10 (Embedding) - 770M | median | 48.21 | 67.15 | 62.98 | 51.8 | 50.99 | 67.0 | 26.38 | 53.5 |
| mean | 51.67 | 67.29 | 58.37 | 51.79 | 50.99 | 65.8 | 26.57 | 53.21 | |
| MoV-10 (Token) - 3B | median | 75.0 | 78.8 | 62.5 | 52.19 | 55.96 | 85.77 | 30.24 | 62.94 |
| mean | 63.45 | 79.49 | 60.19 | 53.04 | 56.27 | 86.41 | 29.11 | 61.14 | |
| MoV-10 (Embedding) - 3B | median | 57.14 | 67.15 | 61.06 | 55.33 | 52.49 | 82.5 | 29.08 | 57.82 |
| mean | 51.07 | 68.81 | 58.65 | 55.28 | 52.57 | 80.53 | 28.51 | 56.49 | |
| MoV-10 (Token) - 11B | median | 76.79 | 78.52 | 53.85 | 51.88 | 63.77 | 94.23 | 33.5 | 64.65 |
| mean | 70.12 | 78.88 | 54.23 | 53.26 | 63.57 | 93.64 | 33.59 | 63.9 | |
| MoV-10 (Embedding) - 11B | median | 75.0 | 78.7 | 57.69 | 54.0 | 57.85 | 92.0 | 33.08 | 64.05 |
| mean | 66.19 | 79.1 | 58.37 | 54.83 | 58.78 | 91.17 | 32.7 | 63.02 |
Table 5:The above results demonstrate the effectiveness of token routing in comparison to imposing a strong inductive bias, such as sentence embedding across various model parameters.
















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











