






下载地址在文末
Hunyuan3D 2.0,这是一种先进的大规模3D合成系统,用于生成高分辨率纹理3D资产。该系统包括两个基础组件:大规模形状生成模型Hunyuan3D-DiT和大规模纹理合成模型Hunyuan3D-Paint。形状生成模型基于可扩展的基于流的扩散变换器,旨在创建与给定条件图像正确对齐的几何形状,为下游应用奠定坚实的基础。纹理合成模型受益于强大的几何和扩散先验,可以为生成的或手工制作的网格生成高分辨率且充满活力的纹理贴图。此外,我们还构建了Hunyuan3D-Studio——一个多功能、用户友好的制作平台,可以简化3D资产的重新创建过程。它允许专业和业余用户有效地操纵甚至动画化他们的网格。我们系统地评估了我们的模型,结果表明Hunyuan3D 2.0在几何细节、条件对齐、纹理质量等方面优于以前的最先进模型,包括开源模型和闭源模型。
文章图片以及信息来源于Release 2025/01/22 Hunyuan3D-2 Special · YanWenKun/Comfy3D-WinPortable · GitHub

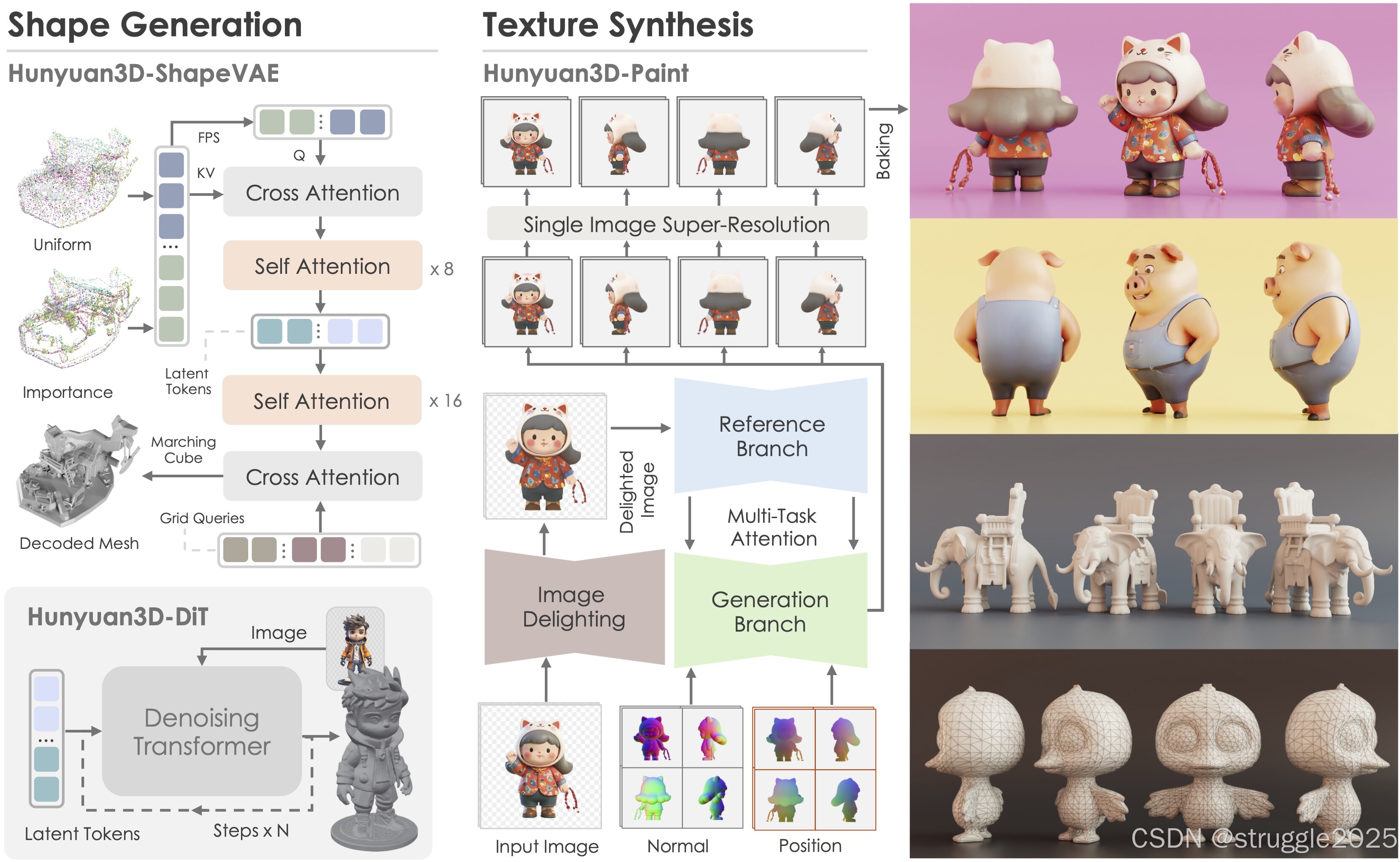
Hunyuan3D 2.0
Hunyuan3D 2.0 采用两阶段生成流程,首先创建裸网格,然后合成该网格的纹理贴图。该策略可以有效地解决形状和纹理生成的困难,并且还为生成或手工制作的网格提供纹理化的灵活性。
效果 展示:
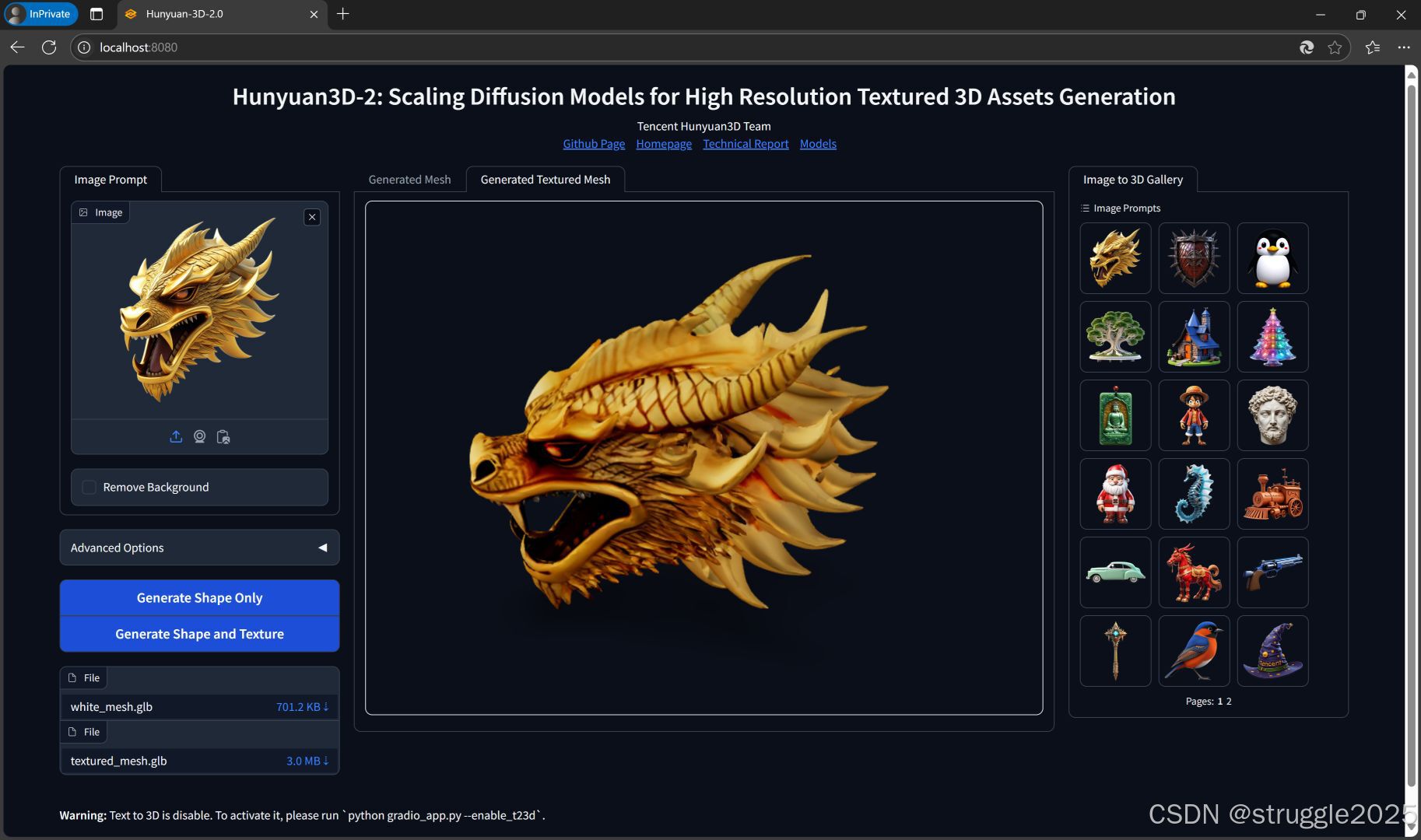

注意事项:所有的文件目录,都不要有中文文字和符号,包括软件的文件夹,使用到的图片名称等等都不要有中文,否则可能会报错。
项目建议使用英伟达显卡,运行显存建议大于等于6G,系统内存建议大于等于24G,这样速度会比较快一些,如果系统内存不够呢,可以手动调大虚拟内存
用法
- 下载并解压,启动EXE完毕后,会自动打开浏览器就 可以进行操作了
下载链接:

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









