






一、软件介绍
文末提供程序和源码下载
ComfyUI_Step1X-Edit自定义节点将 Step1X-Edit 图像编辑模型集成到 ComfyUI 中。Step1X-Edit 是一种最先进的图像编辑模型,可处理参考图像和用户的编辑指令以生成新图像。支持 TeaCache 加速,以最小的质量损失实现 2 倍的推理速度
二、Features 特征
- Support for FP8 inference
支持 FP8 推理 - Optimizing inference speed
优化推理速度
三、Examples 例子
以下是您可以使用 ComfyUI_Step1X-Edit 实现的一些示例:
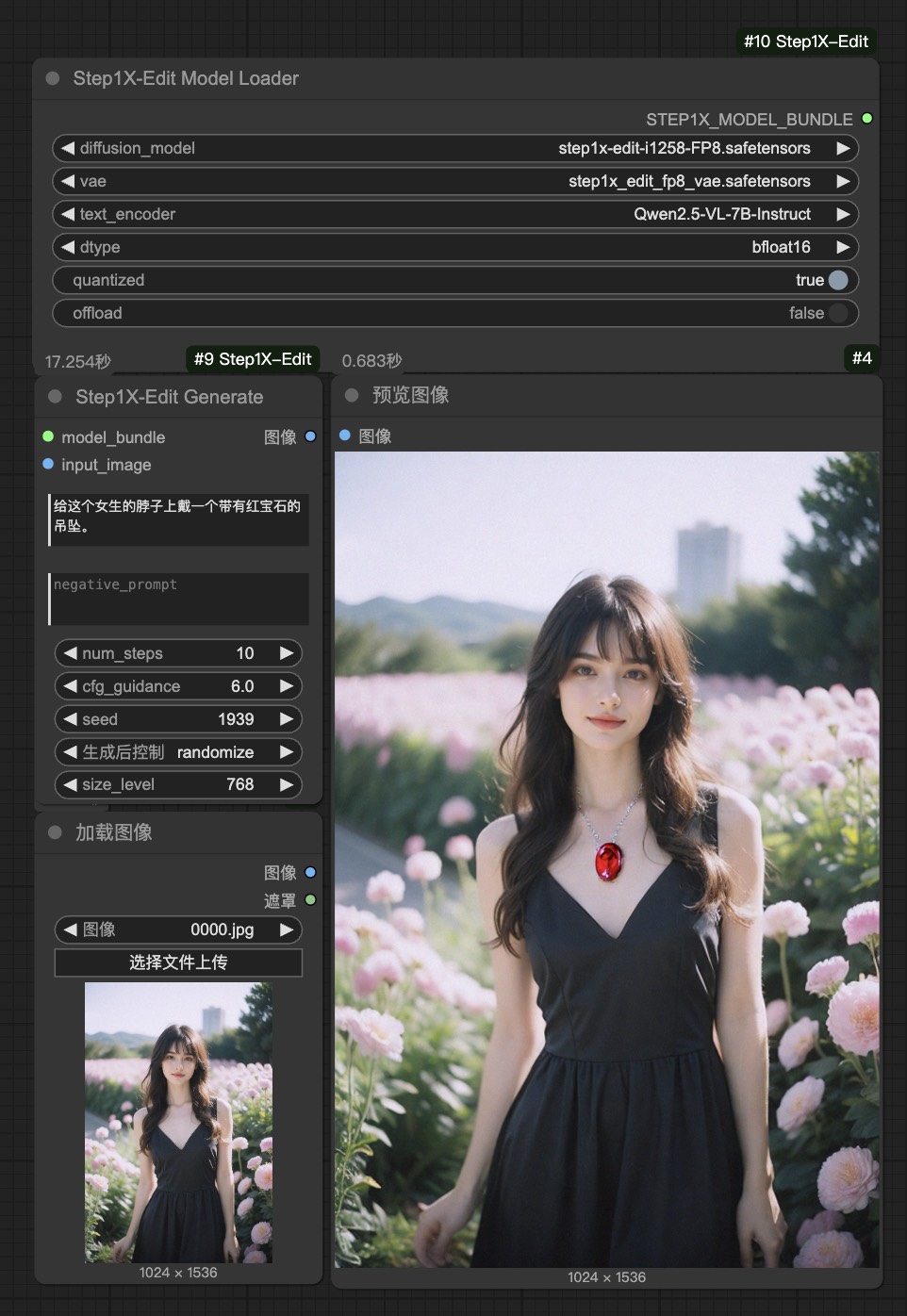
示例 1: “在这个女孩的脖子上添加带有红宝石的吊坠。
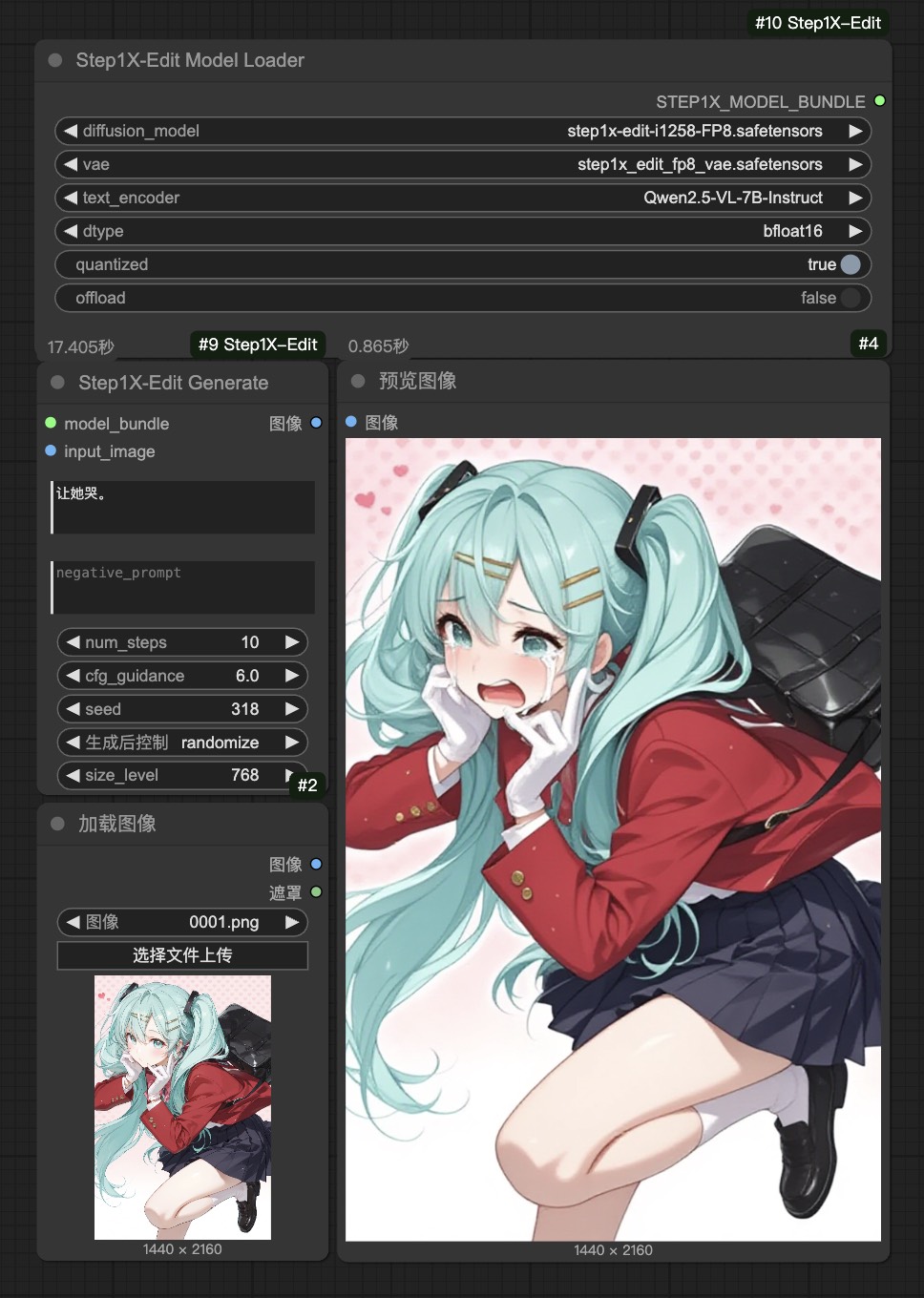
例 2: “让她哭吧。
四、Installation 安装
-
将此仓库克隆到你的 ComfyUI
custom_nodes的目录中:(文末提供直接源码下载)cd ComfyUI/custom_nodes git clone https://github.com/raykindle/ComfyUI_Step1X-Edit.git -
安装所需的依赖项:
Step 1: Install ComfyUI_Step1X-Edit dependencies
第 1 步:安装 ComfyUI_Step1X-Edit 依赖项cd ComfyUI_Step1X-Edit pip install -r requirements.txt第 2 步:安装flash-attn(文末链接下载),这里我们提供了一个脚本来帮助找到适合您系统的预构建 wheel。python utils/get_flash_attn.pyThe script will generate a wheel name like
flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl, which could be found in:
该脚本将生成一个 wheel 名称,例如flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl,可以在以下位置找到:
Linux 版本:Dao-AILab 的 flash-attn 版本(文末链接下载)
Windows 版本:kingbri1 的 flash-attn 版本(文末链接下载)
然后,您可以下载相应的预构建 wheel 并按照 中的 flash-attn 说明进行安装。
注意:即使 CUDA 和 Torch 版本不完全匹配,您仍然可以成功安装 flash-attention。但是,为了获得最佳性能和兼容性,建议使用与您的系统完全匹配的版本。
五、下载 Step1X-Edit-FP8 模型
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>ComfyUI/
└── models/
├── diffusion_models/
│ └── step1x-edit-i1258-FP8.safetensors
├── vae/
│ └── vae.safetensors
└── text_encoders/
└── Qwen2.5-VL-7B-Instruct/
</code></span></span></span></span>- Step1X-Edit diffusion model: Download
step1x-edit-i1258-FP8.safetensorsfrom HuggingFace and place it in ComfyUI'smodels/diffusion_modelsdirectory
Step1X - 编辑扩散模型:从 HuggingFace 下载step1x-edit-i1258-FP8.safetensors并放置在 ComfyUI 的models/diffusion_models目录中 - Step1X-Edit VAE: Download
vae.safetensorsfrom HuggingFace and place it in ComfyUI'smodels/vaedirectory
Step1X-编辑VAE:从HuggingFace下载vae.safetensors并放入ComfyUI的目录下models/vae - Qwen2.5-VL model: Download Qwen2.5-VL-7B-Instruct and place it in ComfyUI's
models/text_encoders/Qwen2.5-VL-7B-Instructdirectory
Qwen2.5-VL 模型:下载 Qwen2.5-VL-7B-Instruct 并将其放在 ComfyUI 的models/text_encoders/Qwen2.5-VL-7B-Instruct目录中
六、Usage 用法
- Start ComfyUI and create a new workflow.
启动 ComfyUI 并创建一个新的工作流程。 - Add the "Step1X-Edit Model Loader" node (or the faster "Step1X-Edit TeaCache Model Loader" for 2x speedup) to your workflow.
将“Step1X-Edit Model Loader”节点(或更快的“Step1X-Edit TeaCache Model Loader”节点,速度提高 2 倍)添加到您的工作流程中。 - Configure the model parameters:
配置模型参数:- Select
step1x-edit-i1258-FP8.safetensorsas the diffusion model
选择step1x-edit-i1258-FP8.safetensors作为扩散模型 - Select
vae.safetensorsas the VAE
选择vae.safetensors作为 VAE - Set
Qwen2.5-VL-7B-Instructas the text encoder
设置为Qwen2.5-VL-7B-Instruct文本编码器 - Set additional parameters (
dtype,quantized,offload) as needed
根据需要设置其他参数 (dtype,quantizedoffload, ) - If using TeaCache, set an appropriate threshold value
如果使用 TeaCache,请设置适当的阈值
- Select
- Connect a "Step1X-Edit Generate" node (or "Step1X-Edit TeaCache Generate" if using TeaCache) to the model node.
将“Step1X-Edit Generate”节点(如果使用 TeaCache,则为“Step1X-Edit TeaCache Generate”)连接到模型节点。 - Provide an input image and an editing prompt.
提供输入图像和编辑提示。 - Run the workflow to generate edited images.
运行工作流以生成编辑后的图像。
Parameters 参数
Step1X-Edit Model Loader Step1X-编辑模型加载器
diffusion_model: The Step1X-Edit diffusion model file (select from the diffusion_models dropdown)
diffusion_model:Step1X-Edit 扩散模型文件(从diffusion_models下拉列表中选择)vae: The Step1X-Edit VAE file (select from the vae dropdown)
vae:Step1X-Edit VAE 文件(从 vae 下拉列表中选择)text_encoder: The path to the Qwen2.5-VL model directory name (e.g., "Qwen2.5-VL-7B-Instruct")
text_encoder:Qwen2.5-VL 模型目录名称的路径(例如,“Qwen2.5-VL-7B-Instruct”)dtype: Model precision (bfloat16, float16, or float32)
dtype:模型精度(bfloat16、float16 或 float32)quantized: Whether to use FP8 quantized weights (true recommended)
quantized:是否使用 FP8 量化权重(推荐 true)offload: Whether to offload models to CPU when not in use
offload:是否在不使用时将模型卸载到 CPU
Step1X-Edit TeaCache Model Loader (Additional Parameters)
Step1X-编辑 TeaCache Model Loader (附加参数)
teacache_threshold: Controls the trade-off between speed and quality
teacache_threshold:控制速度和质量之间的权衡0.25: ~1.5x speedup
0.25: ~1.5 倍加速0.4: ~1.8x speedup
0.4: ~1.8 倍加速0.6: 2x speedup (recommended)
0.6:2 倍加速(推荐)0.8: ~2.25x speedup with minimal quality loss
0.8:~2.25 倍加速,质量损失最小
verbose: Whether to print TeaCache debug information
verbose:是否打印 TeaCache 调试信息
Step1X-Edit Generate / Step1X-Edit TeaCache Generate
Step1X-编辑生成 / Step1X-编辑 TeaCache 生成
model: The Step1X-Edit model bundle
model:Step1X-Edit 模型捆绑包image: The input image to edit
image:要编辑的输入图像prompt: Text instructions describing the desired edit
prompt:描述所需编辑的文本说明negative_prompt: Text describing what to avoid
negative_prompt:描述要避免的内容的文本steps: Number of denoising steps (more steps = better quality but slower)
steps:降噪步骤数(步骤越多 = 质量越好,但速度越慢)cfg_scale: Guidance scale (how closely to follow the prompt)
cfg_scale: 指导量表(遵循提示的程度)image_size: Size of the output image (512 recommended)
image_size:输出图像的大小(推荐 512)seed: Random seed for reproducibility
seed:用于可重复性的随机种子
TeaCache Acceleration TeaCache 加速
This implementation includes TeaCache acceleration technology, which provides:
此实现包括 TeaCache 加速技术,该技术提供:
- 2x faster inference with no quality loss
推理速度提高 2 倍,且无质量损失 - Training-free acceleration with no additional model fine-tuning
无需训练的加速,无需额外的模型微调 - Adaptive caching based on timestep embeddings
基于时间步嵌入的自适应缓存 - Adjustable speed-quality trade-off via threshold parameter
通过阈值参数调整速度-质量权衡
TeaCache works by intelligently skipping redundant calculations during the denoising process. It analyzes the relative changes between steps and reuses previously computed results when possible, significantly reducing computational requirements without compromising output quality.
TeaCache 的工作原理是在降噪过程中智能地跳过冗余计算。它分析步骤之间的相对变化,并在可能的情况下重用以前计算的结果,从而在不影响输出质量的情况下显著降低计算要求。
Based on TeaCache research, which was developed for accelerating video diffusion models and adapted here for image generation.
基于 TeaCache 研究,该研究是为加速视频扩散模型而开发的,并在此处进行了调整以用于图像生成。
七、软件下载
本文信息来源于GitHub作者地址:GitHub - raykindle/ComfyUI_Step1X-Edit: 🔥🔥🔥 Support TeaCache acceleration for 2x faster inference with minimal quality loss

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









