






flux是目前最好的文生图模型,但是生成速度有时候真让人崩溃,多加载几个模型生成一张图更是让人望眼欲穿!今天就和大家安利comfyui_teacatch节点,使用简单,一个插件无损提升生图速度1.5倍,最快加速乘2!

1.teacache for image gen
Timestep Embedding Aware Cache (TeaCache) 是一种无需训练的缓存方法,它通过估计并利用模型在不同时间步输出之间的波动差异来加速推理过程。TeaCache 在图像扩散模型、视频扩散模型和音频扩散模型中表现良好。
-
这是一种缓存技术,专门用于处理扩散模型(Diffusion Models)中的时间步(timestep)信息。扩散模型通常通过多个时间步逐步生成数据(如图像、视频或音频),每个时间步的输出可能会有一定的差异。

-
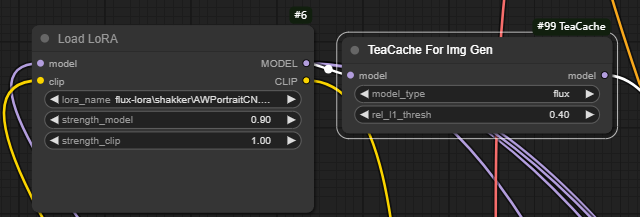
TeaCache 不需要额外的训练过程,它直接利用现有的模型输出进行缓存和优化。这意味着它可以在不改变模型结构或参数的情况下,直接应用于现有的扩散模型。表现在节点的连接上就是只需要将teacache节点连接到diffusion模型后面,如果加载lora模型,则在lora模型之后!
我对这个节点的理解是:假如生图步数是20步,这20步有些步数对图片的影响大则留,有些不大则不留,产生相同效果的步数则缓存起来,这样两部并一步去生图,速度自然快!个人理解仅供参考!

这里解释一下rel-L1-thresh,它是relative ,l1 norm,threshold相对阈值的意思,决定了用于控制缓存的重用策略!

下面是不同相对阈值tea cache的提速表现,这里当阈值设置为0.4时生图速率可以提升2倍!

2.compile model
Compile Model 使用 torch.compile 将模型编译为更高效的中间表示(IRs),从而提升模型性能。该编译过程利用后端编译器生成优化后的代码,可以显著加速推理。首次运行工作流时,编译过程可能会花费较长时间,但一旦编译完成,推理速度会非常快。使用方法如下所示:
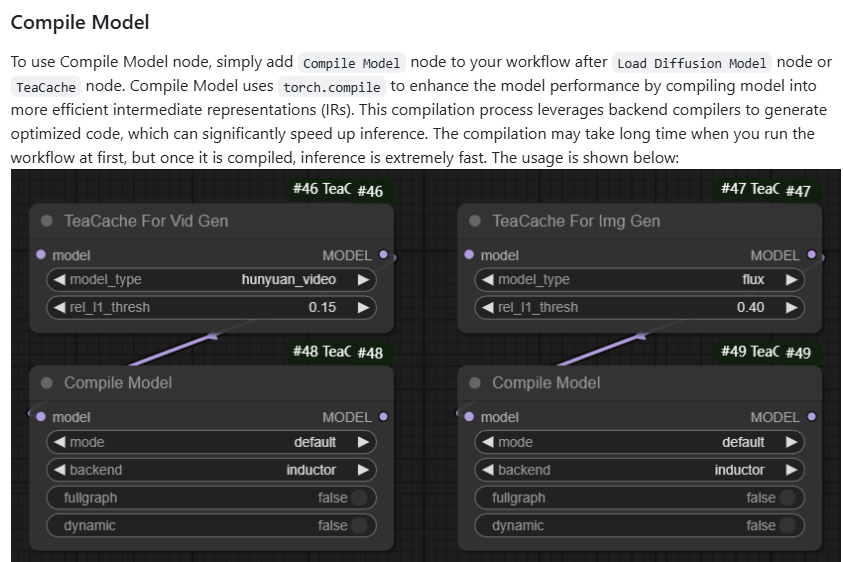
后端编译器例如cuda,torch.compile 是 PyTorch 提供的一种编译工具,能够将模型转换为更高效的中间表示(IRs)。这种转换通过优化模型的计算图,减少冗余操作并利用硬件加速特性,从而提升推理速度。比较抽象大家可以先记忆后理解!
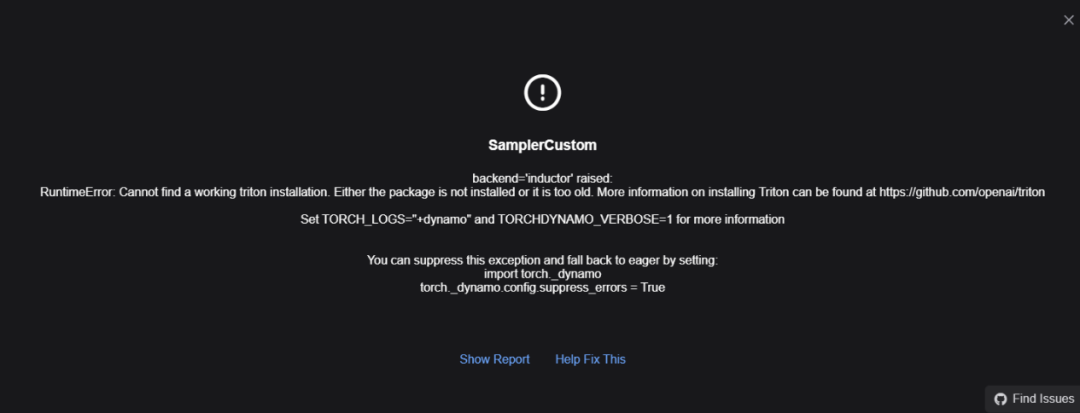
然而很多人接入compile model的时候会报错,如下这是因为缺失triton模块,下一篇文章我会写解决方案!
最后欣赏加速后的AI绘画作品:


好了,今天就到这里,感谢您的收看!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









