







对单个数据进行标准化
函数介绍
sklearn.preprocessing.scale(
X:{array-like, sparse matrix}, 需要进行变换的数据阵
axis=0:指分别按照列(0)或是整个样本(1)计算均数、标准差并进行变换
注意:在sklearn中没有按行计算均数的,若有需要则需将此矩阵进行转置。然后再进行列变化,最后再转置回原样即可
with_mean=True:是否中心化数据(移除均数)
with_std=True:是否均一化标准差(除以标准差)
copy=True:是否生成副本而不是替换原数据
)
代码解释
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import datasets
boston = datasets.load_boston()
bostondf = pd.DataFrame(boston.data, columns=boston.feature_names)
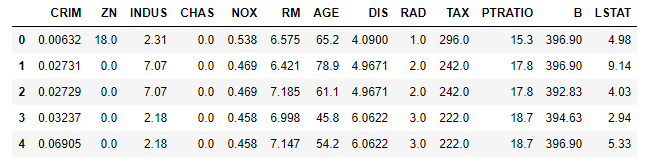
# 查看原始数据,默认显示前5行
bostondf.head()
运行结果:
bostondf.describe()
对表格中的数据进行描述,结果如下:

以CRIM这一列为例,用sklearn对该列做数据的标准变换
from sklearn import preprocessing
# 对数据进行标化,做标准正太变换
x_scaled = preprocessing.scale(bostondf)
# 取出数据的前两行
x_scaled[:2]
结果如下

# 计算转换后的均数和标准差
x_scaled.mean(axis=0), x_scaled.std(axis=0)

从上图可以看出,每一列的均数都非常接近于0,标准差都为1。显然每一列都进行了标化
# 对整个矩阵统一做标化
X_scaled1 = preprocessing.scale(bostondf, axis=1)
X_scaled1[:2]
结果如下

# 分列进行计算
X_scaled1.mean(axis=0), X_scaled1.std(axis=0)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









