







根据https://www.bilibili.com/video/BV1iv411k7qG整理
01实体识别
基于nlp的g3语言去抽取实体对象和基于关系抽取的情境下,用到命名实体识别
命名实体识别通常有1通用领域:人名 地名 时间 货币等七种 2专有领域:医疗 汽车 教育
实体识别三个过程:中文分词 词性标注 识别结果和过程(过程常常涉及词法和句法分析)
实体查询
关系查询


03项目业务需求分析
基于搜索引擎的商业数据分析





04项目总体架构设计








05知识图谱模型设计方法


一个矩形框是一个本体对象,就是一个实体 一条线就是一个关系



语义关系设计要在关系抽取之前 
06.知识图谱语义类型设计
方法论:参照与对标 适配与裁剪 归纳与总结 抽象和提炼

 概念实体:某某卫生组织
概念实体:某某卫生组织
物理实体:看得见摸得见的东西 细胞
现象或过程:出现了 不一定是主动的行为 比如生病了感冒了 只有一方
活动:医药活动如诊断过程涉及活动的双方—医生和病人




长宽高是个指标 包括轴距论据车身结构 抽象成‘尺寸’或者‘xx指标’就是概念实体
把结构化数据里面的字段抽象出我们的实体对象(就是我们的本体)
车门数–座位 座位数–座椅 油箱容积–油箱 行李箱容积—行李箱 整备质量是属性不是实体对象 整备质量可以作为指标抽取出来
如图车身拆分为长度 宽度…整备质量等等就是底层明细适配法

以上就是汽车出现的现象和异常
07.知识图谱语义关系设计

高层关系可复用


底层实例需归纳


底层实体需归纳,实体间的遍历:比如找断轴和自燃 断轴和制动失灵 断轴和导航黑屏 …以一个关系为起点遍历与之所有关系的组合

底层实体需归纳,事件中抽取:
比如“凯越 发动机漏油,变速箱漏油”
事件对应是凯越品牌
发动机漏油:物理实体和现象
变速箱漏油:物理实体和现象
这样就可以把对象的实体关系逐一抽取出来
技巧:在其中把所有与发动机相关的作为起点 比如发动机漏油 发动机异响 发动机渗漏等等等 就可以把发动机相对应的事件都抽取出来了
语义关系的设计在前抽取在后,设计依赖专业知识和现有信息的归纳,抽取是对基于已有的结构化数据资源、半结构化数据资源、文本数据资源
事件实例的抽取可以通过nlp进行抽象 抽象完以后 抽象之后填充到语义关系的实体对象

08开发环境的安装和部署


1python网络爬虫开发环境的安装部署
品牌的爬取和车系的爬取




09汽车品牌数据获取
页面元素分析 品牌数据爬取 数据结构化处理(利于本地存储导入到图数据库)

26个字母下面对应了两百多个品牌

爬取:左侧列表对应cartree



banks=response.html.find('.cartree al li h3a') #因为返回是一个列表 所以遍历整个列表
for bank in blanks:#获取的文本是汽车品牌 对应的连接里面有相应的报价信息
bk=bank.text
start=bank.find('(') #去掉品牌的括号
end=bank.find(')')
bank1=bk[0:start]
Num=bk[(start+1):end]#品牌下的车型数量
url2=url1+bank.arrts.get("href",None) #品牌链接数据获取 获取绝对地址
print(url2)
save2csc(writer,bank1,Num,url12)

现在汽车之家:

右键检查会自动跳到对应的代码
11汽车数据批量导入
品牌数据导入、车系数据导入、关系数据导入


汽车品牌数据导入数:


在import内存了品牌数据和车系数据
或者直接在可视化界面中导入
LOAD CSV WITH HEADERS FROM "file://bank.csv"AS line
CREATE(:Bank{name:line.bank,count:line.count})#创建节点 Bank是结点名字

汽车车系数据导入:

LOAD CSV WITH HEADERS FROM "file://series.csv"AS line
CREATE(p:Serise{name:line.serise,count:line.count})#Series 是一个类 结点是series的实例

品牌/车系关系数据导入
构建关系:

LOAD CSV WITH HEADERS FROM "file://series.csv"AS line
MATCH(entity1:Bank{name:line.bank}),(entity2:Serise{name:line.serise})#Match(),()查找bankh对应的品牌和serise对应的系列 match的过程是从对应的标签类型去选择对应的属性和csv下存储一致的地方,选择出来并构建关系
CREATE(entity1)-[:Subtype{type:line.relation}]->(entity) #Subtype是关系类型 type的属性是relation
汽车品牌/车型创建索引

结果展示

12汽车车型数据获取
基于车系获取车型信息



结果获取了所有车系


可能有时候不能直接通过代码获取 因为是动态的
如下图:页面代码中只有宝马310w 2017款 1.5L 手动 缺少了‘舒适型’

13汽车配置数据获取

首先要获取基本参数信息(第一列),再把具体内容填充进去
找到网页代码 config_data处

下载基本参数的名称 (第一列)
每个tab都有一个参数 对应一个基本参数 最好每个tab都分开处理

可以发现页面代码中 厂商的商字不见了 所以这需要人工去处理补齐
schema的获取效果如下:就是每个基本参数的表头


用具体内容将表头信息补充完整
14.web前端框架设计
基于django的汽车知识图谱web前端框架


1django

用户访问页面的流程是从右到左按照箭头执行的

路由途径
对于不加任何东西的url 返回的是index_view.index
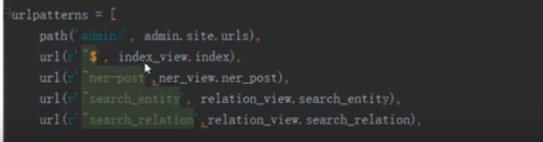
在命名实体识别的视图文件ner_view.py有个命名实体识别的函数ner-post即当url中输入的是ner-post时,调用的是ner-post这个方法,这个方法会调用模型层中neo4j_models的操作



15通用命名实体的识别
命名实体类型划分 技术方案 开源框架





corenlp(可以自己了解一下) 可以对着以下代码去写
我们所用到的是通用和领域的命名实体识别

可以看出实体识别结果 【2017 林肯 雷克萨斯】林肯和雷克萨斯是汽车品牌 ,这其中有通用的也有专业领域的命名实体识别 可以发现2017后面带的标签是t 表示是时间

16.领域命名实体识别
汽车领域命名实体词典设计和应用
汽车领域的词典就是我们之前爬虫下载下来的品牌和车系,并且把这些信息单独摘出来,且给他编号和对应的类型说明,即每个类型有个对应的标识,
比如9就对应的是宝马的这个品牌的某某车系

在模板层当有用户请求命名实体识别的时候 对应的调取视图层的函数



17.实体查询程序设计
汽车领域实体查询
neo4j开发驱动 py2neo开发框架



要学习和database和graph和cursor

run是graph的一个函数 返回的是一个游标对象 cursor,他有个对象叫.data
a:Person a代表变量 Person是一个label


18关系查询程序设计
py2neo开源框架 实体关系查询

1输入实体一 输入品牌
2实体二 输入车系
3 选择关系 关系查询 输入subbank

基于实体1+关系

基于关系+实体二


汽车实体关系查询:实体1+实体2

19.知识图谱数据可视化
数据可视化方案 Echart图数据可视化






//一,数据的准备,基于查询结果:初始化data和links列表,用于echarts可视化输出
//第一部分对应的是可视化中的实体查询和关系查询,查询完后的对象就存在entityrelation里面,之后进行解构,解构的结果放在data和links列表
var ctx=[{(ctx|safe)}];
//{entity2,rel}
var entityRelation=[{{entityRelation|Safe}}]:
var data=[];
var links=[];
if(ctx.length==0)(...)
//基于准备好的数据:data和links,设置echarts参数'
var myChart=echarts.init(document.getElementById('graph'))
//graph是一个html的一个页面对象
option={//option就是echart的参数
title:("text":"...),
tooltip:{},
animationDurationUpdate:1500,
animationEasingUpdate:'quinticInOut',
label:{...},
legend:{"x":"center"...},
series:{...}
};
//设置echart的属性
myChart.setOption(option):
通过之前查询语句的解读我们取他的名字 去设置他的结点是否允许拖拽,去设置他所隶属的类型,之后设置关系,关系的语言,关系的目标,关系的类型,设置完以后就会生成一个data和links的列表




20.推荐系统基本原理和实现机制
基于交易历史 基于行为轨迹 基于kg

协同过滤就是关联分析 就是一个概率方程,
基于交易历史:比如尿布和啤酒一起买,冷启动:就是没有交易历史
基于行为历史:搜索引擎,基于用户对商品的搜索,属于数据密集型,收集用户的搜索和访问的历史,进行漏斗,把用户舍弃和聚焦的品牌形成竞争分析矩阵,最后把用户聚焦的点找出来,这个过程依赖庞大的用户行为日志
基于知识图谱:对以上二者的一个结合,相似计算,只需要掌握部分数据即可,劣势是知识建模,在垂直领域需要很强的专业性

环境画像信息:比如用的手机app 手机型号–小米4 用的WiFi
用户画像:出生日期 性别 职业 过往的行为信息
设备信息:判断登录否 是哪个用户
三者加和形成媒体访问行为-----流量特征
结合内容画像(比如这文章是什么行业 )其中的关键词结合各种推荐策略的模型形成初始的推荐结果之后做排序



21.知识图谱与推荐系统融合的模式

1基于实体属性的推荐算法:实体相似,比如我搜索宝马x3,推荐的是奥迪a6,把正确的推荐给正确的人,实体属性就是本身的含义,没有用向量表示
2基于实体关系的推荐算法:也称为了基于路径,实体相关,宝马x3,与之相关的同一品牌的不同系列,宝马x5,x7,案例:同一品牌或同一车系或同一厂商
1、2是基于直接相关,3是基于协同过滤,用户感兴趣的东西再进行拓展,找到与之关联的实体,基于属性关联和关系关联结合起来,只是计算的时候采用是用向量计算
3基于特征向量的推荐算法,把kg中实体的关系用向量表示,表示成对应的相关的向量,水波计算,就是基于协同过滤,把你搜索的过感兴趣的东西进行延伸扩散计算出一个概率就是对某个商品的感兴趣程度,再进行推荐。


22.基于KGE的开源推荐系统框架
RippleNet基于KGE的推荐框架工作原理和实现机制
kge与word2v相似


RippleNet是基于图书的评论数据 来自亚马逊

这个知识图谱就是基于用户已访问的实体结点,加上实体结点与外部实体间的关系来进行相关性的计算
每一跳(hop)都是在kg中以点击过的某个结点为中心去找他的出度的结点
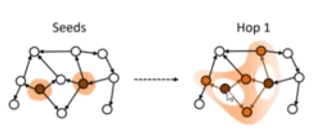
(h,r)->t h是头部r是关系 r是关系的尾部,ripple是水波扩散,其实用户的向量(user embedding )就是基于用户点击的历史 (user click history),以及在用户历史之后进行水波扩散的特征来进行表示的,所以用户向量表示的含义就是用户对商品的关注度,此时再把商品代入(item),二者结合计算相应的概率模型,基于概率推测用户对这个商品感不感兴趣




cd RippleNet-master
cd src
python preprocess.py--dataset movie
python main.py--dataset movie
23.RippleNet开源框架源码剖析
RippleNet框架源码结构、程序逻辑和流程


main.py->data_loader.py->train.py->model.py
main函数数据加载,模型训练的调度、调用模型里面具体的执行程序























 6591
6591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









