






本人毕设
本课题旨在实现并改进基于CNN的手写数字识别算法并且将其应用于手写试卷数字的识别中,最终完成一个识别教师批改的小题分数数字并统计的试卷分数统计系统。旨在替代高投入,低准确的传统试卷处理方式。并为在线考试和评估系统提供技术支持。
除了教育领域外,手写数字识别系统还可以应用于金融、医疗、法律等领域。例如,银行可以利用这种系统自动识别和处理客户的手写支票;医院可以利用这种系统自动识别和处理病历、化验单等信息。
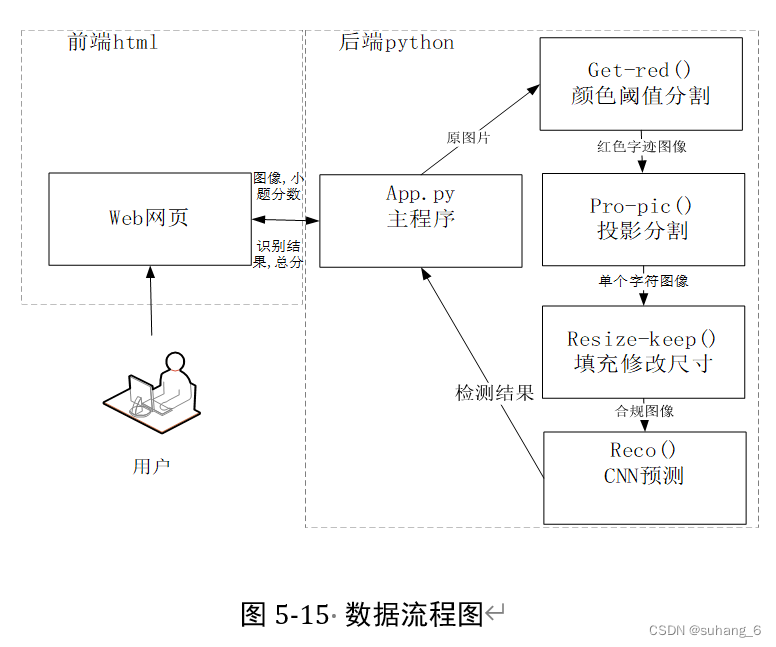
图像预处理部分
import cv2
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import cnn.reco as reco
#颜色阈值分割
def getred(strFilePath):
img = cv2.imread(strFilePath)
# 在彩色图像的情况下,解码图像将以b g r顺序存储通道。
grid_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 从RGB色彩空间转换到HSV色彩空间
grid_HSV = cv2.cvtColor(grid_RGB, cv2.COLOR_RGB2HSV)
# H、S、V范围一:
lower1 = np.array([0, 43, 46])
upper1 = np.array([10, 255, 255])
mask1 = cv2.inRange(grid_HSV, lower1, upper1) # mask1 为二值图像
res1 = cv2.bitwise_and(grid_RGB, grid_RGB, mask=mask1)
# H、S、V范围二:
lower2 = np.array([156, 43, 46])
upper2 = np.array([180, 255, 255])
mask2 = cv2.inRange(grid_HSV, lower2, upper2)
res2 = cv2.bitwise_and(grid_RGB, grid_RGB, mask=mask2)
# 将两个二值图像结果 相加
mask3 = mask1 + mask2
return mask3
# 投影法分割 输入灰度图像,rc=0为行向分割,rc=1为列分割
def pre_pic(img_gray, rc):
# img为灰度图,rc01
# 二值化
t, binary = cv2.threshold(img_gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY)
rows, cols = binary.shape
# print(rows,cols)
if rc == 0:
hor_list = [0] * rows
for i in range(rows):
for j in range(cols):
# 统计每一行的白色像素总数
if binary.item(i, j) > 122:
hor_list[i] = hor_list[i] + 1
elif rc == 1:
hor_list = [0] * cols
for j in range(cols):
for i in range(rows):
# 统计每一列的白色像素总数
if binary.item(i, j) > 122:
hor_list[j] = hor_list[j] + 1
'''
对hor_list中的元素进行筛选,可以去除一些噪点
'''
hor_arr = np.array(hor_list)
hor_arr[np.where(hor_arr < 2)] = 0
hor_list = hor_arr.tolist()
img_white = np.ones(shape=(rows, cols), dtype=np.uint8) * 255
#绘制水平投影
if rc == 0:
for i in range(rows):
pt1 = (cols - 1, i)
pt2 = (cols - 1 - hor_list[i], i)
cv2.line(img_white, pt1, pt2, (0,), 1)
# # 绘制垂直投影
elif rc == 1:
for j in range(cols):
pt1 = (j, rows - 1)
pt2 = (j, rows - 1 - hor_list[j])
cv2.line(img_white, pt1, pt2, (0,), 1)
plt.imshow(img_white)
plt.axis('off') # 去坐标轴
plt.xticks([]) # 去 x 轴刻度
plt.yticks([]) # 去 y 轴刻度
plt.show()
# 取出list中像素存在的区间
vv_list = list()
v_list = list()
for index, i in enumerate(hor_list):
if i > 0:
v_list.append(index)
else:
if v_list:
vv_list.append(v_list)
# list的clear与[]有区别
v_list = []
# 取出各个文字区间,存入图片列表
img_ready = []
for i in vv_list:
if rc == 0:
img_hor = img_gray[i[0]:i[-1], :]
elif rc == 1:
img_hor = img_gray[:, i[0]:i[-1]]
img_ready.append(img_hor) # 加入结果list
# plt.imshow(img_hor)
# plt.show()
return img_ready
# 该函数用于保持形状的改变图像尺寸
def resize_keep(img, target_size):
# img = cv2.imread(img_name) # 读取图片
old_size = img.shape[0:2] # 原始图像大小
ratio = min(float(target_size[i]) / (old_size[i]) for i in range(len(old_size))) # 计算原始图像宽高与目标图像大小的比例,并取其中的较小值
new_size = tuple([int(i * ratio) for i in old_size]) # 根据上边求得的比例计算在保持比例前提下得到的图像大小
img = cv2.resize(img, (new_size[1], new_size[0])) # 根据上边的大小进行放缩
pad_w = target_size[1] - new_size[1] # 计算需要填充的像素数目(图像的宽这一维度上)
pad_h = target_size[0] - new_size[0] # 计算需要填充的像素数目(图像的高这一维度上)
top, bottom = pad_h // 2, pad_h - (pad_h // 2)
left, right = pad_w // 2, pad_w - (pad_w // 2)
img_new = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, None, (0, 0, 0))
return img_new
def all(img_path):
# 提取红色部分保存
a = getred(img_path)
# 行分割
plt.imshow(a)
plt.show()
b = pre_pic(a, 0)
# 识别结果储存
result = []
for i in b:
# 列分割
c = pre_pic(i, 1)
plt.imshow(i)
plt.show()
row = []
for j in c:
plt.imshow(j)
plt.show()
j = resize_keep(j, [28, 28])
d=reco.preImg(j)
if int(d)==5:d="T"
row.append(d)
# print(reco.preImg(j)) # 链接pre文件中的preImg函数,预测图片值
result.append(row)
# result=[['T'], ['T'], [3], [2], [2, 3], [3, 1]]
#print(result)
return result
if __name__ == "__main__":
img_path = "paper2.png"
print(all(img_path))
训练部分
# 导入相关功能包
import os
import numpy as np
import paddle.fluid as fluid
from paddle import paddle
import matplotlib.pyplot as plt
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
BUF_SIZE = 512
# 每批数据大小
BATCH_SIZE = 128
# 训练集
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(),
buf_size=BUF_SIZE
),
batch_size=BATCH_SIZE
)
# 测试集
test_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.test(),
buf_size=BUF_SIZE
),
batch_size=BATCH_SIZE
)
def cnn(img):
# 第一个卷积-池化层
conv1 = fluid.layers.conv2d(input=img,num_filters=20,
filter_size=5,padding='SAME',act='relu')
pooling1 = fluid.layers.pool2d(input=conv1,pool_size=2,
pool_stride=2,pool_type='max')
conv1_pool_1 = fluid.layers.batch_norm(input=pooling1)
# 第二个卷积-池化层
conv2 = fluid.layers.conv2d(input=conv1_pool_1, num_filters=50,
filter_size=5, padding='SAME',act='relu')
pooling2 = fluid.layers.pool2d(input=conv2,pool_size=2,
pool_stride=2,pool_type='max')
prediction = fluid.layers.fc(input=pooling2,act='softmax',size=10)
return prediction
# 数据格式
paddle.enable_static()
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')
prediction = cnn(image)
label = fluid.layers.data(name='lable', shape=[1], dtype='int64')
# 定义损失函数
cost = fluid.layers.cross_entropy(input=prediction, label=label) # 交叉熵损失
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=prediction, label=label)
# 定义优化方法
optimizer = fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_cost) # 为网络添加反向计算过程
print('ok')
# 创建执行器
paddle.enable_static()
place = fluid.CPUPlace()
exe = fluid.Executor(place=place)
exe.run(fluid.default_startup_program())
# 定义数据映射器
feeder = fluid.DataFeeder(feed_list=[image, label], place=place)
# print(type(feeder))
# 训练过程可视化
all_train_iter = 0
all_train_iters = []
all_train_costs = []
all_train_accs = []
def draw_train_process(title, iters, costs, accs, label_cost, lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs, color='red', label=label_cost)
plt.plot(iters, accs, color='green', label=lable_acc)
plt.legend()
plt.grid()
plt.show()
EPCOH_NUM = 2 # 训练轮数
for epoch_num in range(EPCOH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(), # 运行主程序
feed=feeder.feed(data), # 给模型喂入数据
fetch_list=[avg_cost, acc]) # fetch 误差、准确率
all_train_iter = all_train_iter + BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
# 每200个batch打印一次信息 误差、准确率
if batch_id % 200 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(epoch_num, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_program = fluid.default_main_program().clone(for_test=True)
test_accs = []
test_costs = []
# 每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()): # 遍历test_reader
test_cost, test_acc = exe.run(program=test_program, # 执行训练程序
feed=feeder.feed(data), # 喂入数据
fetch_list=[avg_cost, acc]) # fetch 误差、准确率
test_accs.append(test_acc[0]) # 每个batch的准确率
test_costs.append(test_cost[0]) # 每个batch的误差
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs)) # 每轮的平均误差
test_acc = (sum(test_accs) / len(test_accs)) # 每轮的平均准确率
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (epoch_num, test_cost, test_acc))
model_save_dir = "./first.cnn.model"
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir, # 保存推理model的路径
['image'], # 推理(inference)需要 feed 的数据
[prediction], # 保存推理(inference)结果的 Variables
exe) # executor 保存 inference model
print('训练模型保存完成!')
draw_train_process("training", all_train_iters, all_train_costs, all_train_accs, "trainning cost", "trainning acc")
预测部分
# 导入相关功能包
import numpy as np
import paddle.fluid as fluid
from paddle import paddle
import matplotlib.pyplot as plt
from PIL import Image
import os
import cv2
#本文件用于预测
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
model_save_dir = r"C:\Users\11387\Documents\cnn-paper\cnn\first.cnn.model"
paddle.enable_static()
place = fluid.CPUPlace()
def load_image(im):
# im = Image.open(file).convert('L') # 将RGB转化为灰度图像,L代表灰度图像,像素值在0~255之间
# im = im.resize((28, 28), ) # resize image with high-quality 图像大小为28*28
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32) # 返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。
# print(im)
im = im / 255.0 * 2.0 - 1.0 # 归一化到【-1~1】之间
return im
def preImg(img):
# img = Image.open(infer_path)输入更换
plt.imshow(img) # 根据数组绘制图像
plt.show() # 显示图像
infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
# 加载数据并开始预测
with fluid.scope_guard(inference_scope):
# 获取训练好的模型
# 从指定目录中加载 推理model(inference model)
[inference_program, # 推理Program
feed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,
# fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。model_save_dir:模型保存的路径
infer_exe) # infer_exe: 运行 inference model的 executor
img_p = load_image(img)
results = infer_exe.run(program=inference_program, # 运行推测程序
feed={feed_target_names[0]: img_p}, # 喂入要预测的img
fetch_list=fetch_targets) # 得到推测结果,
# 获取概率最大的label
lab = np.argsort(results) # argsort函数返回的是result数组值从小到大的索引值
#print("该图片的预测结果的label为: %d" % lab[0][0][-1]) # -1代表读取数组中倒数第一列
return lab[0][0][-1]
if __name__ == '__main__':
strFilePath = "infer_3.png"
# img = Image.open(strFilePath)
img = cv2.imread(strFilePath)
print('1',type(img))
print(preImg(img))
前端部分
使用flask+html
后端代码
# coding:utf-8
from flask import Flask, make_response, render_template, request
import numpy as np
import paddle.fluid as fluid
from paddle import paddle
import matplotlib.pyplot as plt
from PIL import Image
import os
from prepro.prepro import all
app = Flask(__name__)
@app.route('/', methods=['GET'])
def hello_world():
myName = "abc"
myAge = 21
myList = range(0, 10)
res = make_response(render_template('index.html', mName=myName, mAge=myAge, mList=myList))
return res
@app.route('/uploadImg', methods=['GET', 'POST'])
def uploadImg():
if request.method == 'GET':
res = make_response(render_template('index.html'))
return res
elif request.method == "POST":
if 'myImg' in request.files:
objFile = request.files.get('myImg')
myt=request.form.get('myt')
# print(myt)
strFileName = objFile.filename
strFilePath = "C:/Users/11387/Documents/cnn-paper/static/myImages/" + strFileName
objFile.save(strFilePath)
#a为识别后返回的二维数组
a = all(strFilePath)
#b为总分数
b = 0
#x为选择单题分数
x = int(myt)
for i in a:
if len(i) == 1:
if i == ['T']:
b = b + x
else:
b = b + int(i[0])
if len(i) == 2:
b = b + 10 * int(i[0]) + int(i[1])
c="每题分数为"+str(a)+"<br>"+"总分为"+str(b)
return c
else:
err = "error"
return err
else:
err = "error"
return err
if __name__ == '__main__':
app.run(host='0.0.0.0', port=80)
# http 80 https 443 tcp/ip
# get post request response
# get request ->服务器处理->response->浏览器渲染html内容
#
# html 超文本标记语言 js css jquery
前端代码:
<!DOCYTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Title<Thead</title>
<script>
function showImg(file) {
var reader = new FileReader();
reader.onload = function (evt){
document.getElementById('myImg1').src = evt.target.result;
}
reader.readAsDataURL(file.files[0])
}
</script>
</head>
<body>
<img id="myImg1"src="" style="max-width: 500px; max-height: 500px;">
<form method="post" action="/uploadImg" enctype="multipart/form-data">
<input type="file" name="myImg" onchange="showImg(this)"><br><br>
#小题分数默认为2
<br><input type="text" name="myt" value="2"><br>
<input type="submit" value="上传">
</form>
</body>
</html>

















 7457
7457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









