






文章目录
一:哈希表(Hash Table)
1.1 简介
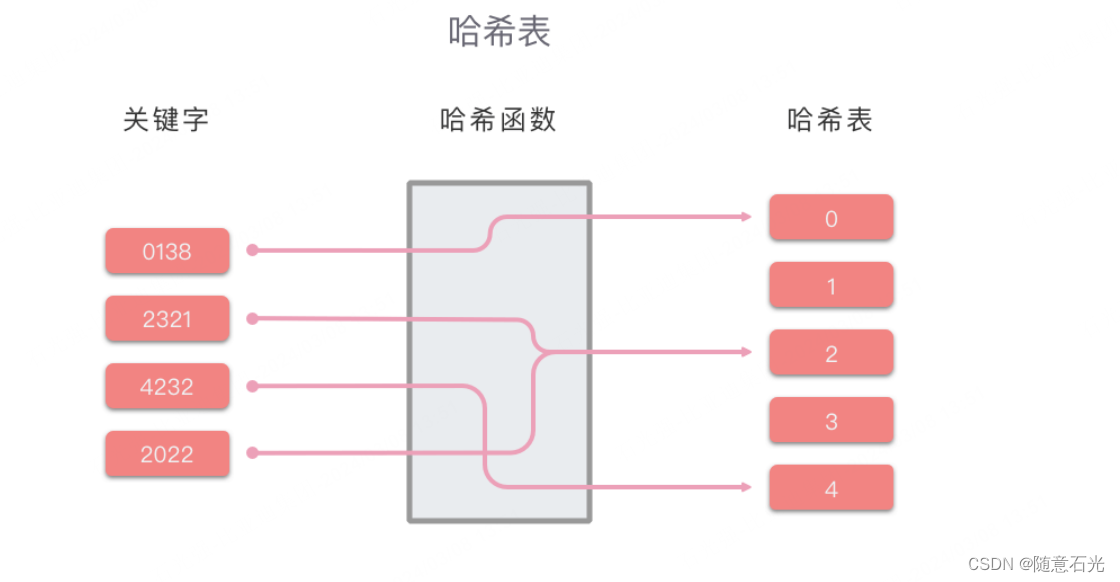
哈希表(Hash Table),又名做散列表,是根据关键字和值直接进行访问的数据结构。也就是说,它通过关键字 key 和一个映射函数 Hash计算出对应的值value,然后把键值对映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希函数,用于存放记录的数组叫做哈希表。 哈希表的关键思想是使用哈希函数,将键 key 和值 value 映射到对应表的某个区块中。
1.2 可以将算法思想分为两个部分
向哈希表中插入一个关键码值:通过哈希函数解析关键字,并将对应值存放到该区块中。
- 比如:0138 通过哈希函数 Hash(key) = 0138 // 100 = 0,得出应将 0138 分配到0 所在的区块中。
在哈希表中搜索一个关键码值:通过哈希函数解析关键字,并在特定的区块搜索该关键字对应的值。
- 比如:查找 2321,通过哈希函数,得出 2321 应该在 2 所对应的区块中。然后我们从 2 对应的区块中继续搜索,并在 2 对应的区块中成功找到了 2321。
- 比如:查找 3214,通过哈希函数,得出 3214 应该在 3 所对应的区块中。然后我们从 3 对应的区块中继续搜索,但并没有找到对应值,则说明 3214 不在哈希表中。
1.3 相关术语
- 哈希函数:在记录的关键字与记录的存储地址之间建立的一种对应关系。
- 冲突: 若关键字不同而函数值相同,则称这两个关键字为“同义词”,并称这种现象为冲突。
- 哈希查找:利用哈希函数进行查找的过程。
- 装填因子:记表中添入记录数为m,表长度为n,则装填因子为α = m n \frac{m}{n} nm
1.4 性质
- 哈希表实际上是以空间换取时间,它的查找的时间效率一般比其它方法高,但消耗空间资源
- 冲突一般不可避免,发生冲突的次数与表的装填程度呈正相关
- 哈希函数相同的情况下,处理冲突的方法不同,所得哈希表的平均查找长度也不同
- 线性探测再散列处理冲突容易造成记录的“二次聚集”,即使得本不是同义词的关键字又产生新的冲突
- 对开放定址处理冲突的哈希表而言,表长必须≥记录数
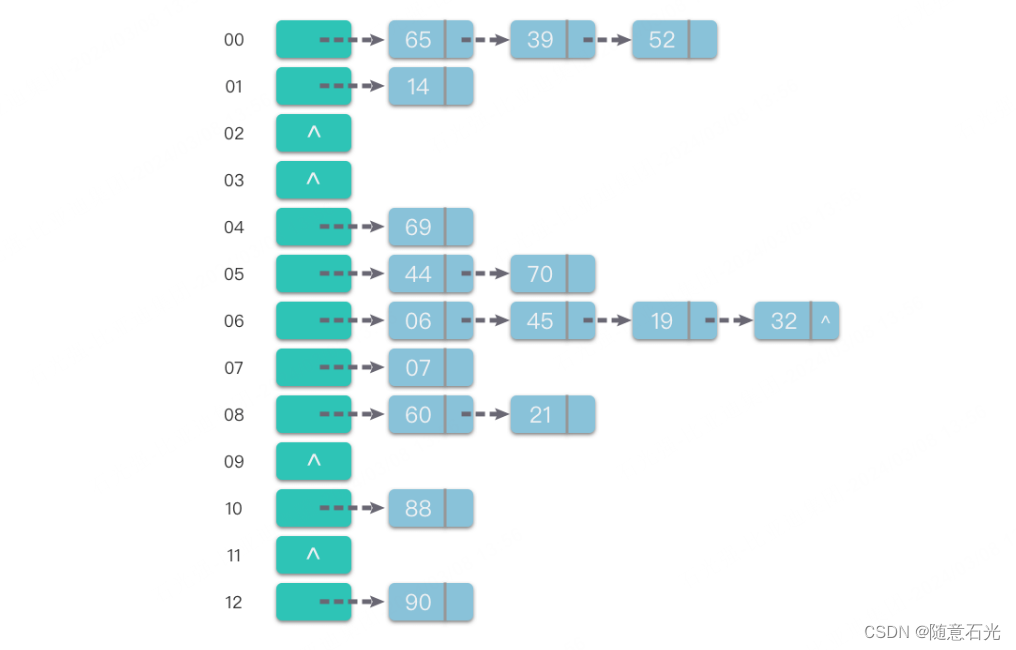
- 链地址处理冲突的哈希表不要求表长必须≥记录数,它的平均查找长度主要取决于哈希函数本身
二:哈希冲突
2.1 什么是哈希冲突
对于两个元素,e1!=e2,但Hash(e1)=Hash(e2),就会产生哈希冲突,简单点说,就是两个不同的元素经过哈希函数的计算,计算除了相同的存储地址,这样的情况成为哈希冲突。
2.2 为何要避免哈希冲突
哈希表需要尽量将元素均匀的放入到每个存储位置中去,但是如果两个元素的关键码值相等,那么就会放到同一个元素中,如果这种情况很多,就会出现一个存储位置出现很多元素的情况。这样不利于查找。
2.3 如何避免哈希冲突
理论上如果哈希桶的数量多余要存储的位置,那么哈希冲突是可以避免的,但是实际中,我们认为要存储的元素是很多的,无穷的,哈希桶的数量是有限的,创建一个哈希桶也是需要耗费资源的,因此,实际中哈希冲突是不可避免的,因此,可以设计一些方法尽可能减少哈希冲突。
2.4 如何减少哈希冲突
设计良好的哈希函数可以减少或者避免哈希冲突
下面只介绍两种常用哈希函数设计的方法:
2.4.1 直接地址法
取关键字的某个线性函数值作为哈希地址。比如:H(key)=a*key+b (a,b)都是常数
优点:直接地址法优点是哈希函数简单,不同的关键字不会产生冲突,,但是关键字集合往往是比哈希地址的结合大,因此,该方法会需要很多哈希桶,而且关键字集合往往离散,所有产生的哈希表会造成空间的巨大浪费,实际中不适用。
2.4.1 除留余数法
以一个略小于哈希地址集合个数的质数p,让关键字的关键码取它的余数作为哈希地址:H(key)=key%p,(p是质数,p<=m,m是集合地址个数)
三:代码实现
package com.sysg.dataStructuresAndAlgorithms.hashtable;
import java.util.Scanner;
public class HashTableDemo {
public static void main(String[] args) {
//创建一个哈希表
HashTable hashTable = new HashTable(7);
//写一个简单的菜单
String key = "";
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("add:添加雇员");
System.out.println("list:显示雇员");
System.out.println("find:查找雇员");
System.out.println("exit:退出系统");
key = scanner.next();
switch (key) {
case "add":
System.out.println("输入id");
int id = scanner.nextInt();
System.out.println("输入名字");
String name = scanner.next();
Emp emp = new Emp(id, name);
hashTable.add(emp);
break;
case "list":
hashTable.list();
break;
case "find":
System.out.println("请输入需要查找的id");
id = scanner.nextInt();
hashTable.findEmpById(id);
break;
case "exit":
scanner.close();
System.exit(0);
break;
default:
break;
}
}
}
}
/**
* 创建HashTable,管理多条链表
*/
class HashTable {
/**
* 链表
*/
private final EmpLinkedList[] empLinkedLists;
/**
* 表示共有多少条链表
*/
private final int size;
public HashTable(int size) {
this.size = size;
//初始化empLinkedLists
empLinkedLists = new EmpLinkedList[size];
//初始化每一条每一条链表
for (int i = 0; i < size; i++) {
empLinkedLists[i] = new EmpLinkedList();
}
}
/**
* 添加雇员
*
* @param emp 员工信息
*/
public void add(Emp emp) {
//根据员工的id查到员工应该属于那条链表
int empLinkedListNum = hashFunction(emp.id);
//将emp添加到对应的链表当中
empLinkedLists[empLinkedListNum].add(emp);
}
/**
* 遍历哈希表当中的所有linkedList
*/
public void list() {
for (int i = 0; i < size; i++) {
empLinkedLists[i].list(i);
}
}
/**
* 根据id查找雇员
*
* @param id 雇员的id
*/
public void findEmpById(int id) {
int empLinkedListNum = hashFunction(id);
//将emp添加到对应的链表当中
Emp emp = empLinkedLists[empLinkedListNum].findEmpById(id);
if (emp != null) {
//说明找到了
System.out.printf("在第%d条链表找到雇员,id=%d\n", (empLinkedListNum + 1), id);
} else {
System.out.println("在哈希表中没有找到该雇员信息");
}
}
/**
* 散列函数,取模法
*
* @param id 员工id
* @return 取模后的值
*/
public int hashFunction(int id) {
return id % size;
}
}
/**
* 表示一个雇员
*/
class Emp {
/**
* 雇员id
*/
public int id;
/**
* 雇员姓名
*/
public String name;
/**
* 下一个雇员的信息
* next默认为null
*/
public Emp next;
/**
* 构造器
*
* @param id 雇员id
* @param name 雇员姓名
*/
public Emp(int id, String name) {
super();
this.id = id;
this.name = name;
}
}
/**
* 表示雇员链表
*/
class EmpLinkedList {
/**
* 头指针,先执行第一个emp,因此我们这个链表的head是直接指向第一个head
* head默认为null
*/
public Emp head;
/**
* 添加雇员到链表
* 1.添加雇员时id是自增涨的,即id的分配就是从小到大
* 2.因此我们直接将该雇员添加到链表的最后即可
*/
public void add(Emp emp) {
//如果是添加第一个雇员
if (head == null) {
head = emp;
return;
}
//如果不是第一个雇员,就使用一个辅助指针,帮助定位到最后
Emp currentEmp = head;
while (currentEmp.next != null) {
//说明到最后一个节点了
//向后移
currentEmp = currentEmp.next;
}
//退出时,直接将emp加入到当前链表中
currentEmp.next = emp;
}
/**
* 遍历链表的雇员信息
*/
public void list(int number) {
//如果链表的头节点为null,则说明当前链表是空的
if (head == null) {
System.out.println("第" + number + "链表为空");
return;
}
Emp currentEmp = head;
while (true) {
System.out.printf("第" + (number + 1) + "条链表雇员的id=%d name=%s\t", currentEmp.id, currentEmp.name);
//如果currentEmp.next == null,说明到最后一个节点了
if (currentEmp.next == null) {
break;
}
currentEmp = currentEmp.next;
}
}
/**
* 根据id查找雇员,如果没有找到就返回null
*
* @param id 雇员的id
* @return 雇员信息
*/
public Emp findEmpById(int id) {
//判断链表是否为空
if (head == null) {
System.out.println("链表为空");
return null;
}
Emp currentEmp = head;
//找到了
while (currentEmp.id != id) {
//退出
if (currentEmp.next == null) {
//遍历完整个链表没找到
currentEmp = null;
break;
}
currentEmp = currentEmp.next;
}
return currentEmp;
}
}

















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











