






本文目录:
一、K-近邻算法思想
K-近邻算法(K Nearest Neighbor,简称KNN)。如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别 。就好像根据你的邻居来推断你的类别。
样本相似性:样本都是属于一个任务数据集的,样本距离越近则越相似。
K值的选择:

欧式距离:

二、KNN的应用方式
( 一)分类流程

1.计算未知样本到每一个训练样本的距离(欧式距离);
2.将训练样本根据距离大小升序排列;
3.取出距离最近的 K 个训练样本;
4.进行多数表决,统计 K 个样本中哪个类别的样本个数最多;
5.将未知的样本归属到出现次数最多的类别。
(二)回归流程

1.计算未知样本到每一个训练样本的距离;
2.将训练样本根据距离大小升序排列;
3.取出距离最近的 K 个训练样本;
4.把这 K 个样本的目标值计算其平均值;
5.作为未知的样本预测的值。
三、API介绍
(一)分类预测操作
例:
#分类预测操作
#导包
from sklearn.neighbors import KNeighborsClassifier
# #准备数据集
x_train=[[1,1],[1,2],[2,1],[2,2]]
y_train=[0,0,0,1]
# 创建模型
knn=KNeighborsClassifier(n_neighbors=3)#k默认为5
# 训练模型
knn.fit(x_train,y_train)
# 预测
print(knn.predict([[1.1,1.1]]))
(二)回归预测操作
例:
#回归预测操作
#1.导包
from sklearn.neighbors import KNeighborsRegressor
#2、创建模型算法对象 (回归的)
es = KNeighborsRegressor(n_neighbors=2)
#
#3、准备训练集 x和y
x_train=[[0,0,1],[1,1,0],[3,10,10],[4,11,12]]
y_train=[0.1,0.2,0.3,0.4]
#4、准备测试集
x_test=[[3,10,11]]
#5、模型训练
es.fit(x_train,y_train)
#6、模型预测(并打印结果)
y_test = es.predict(x_test)
print(f"预测结果为{y_test}")
四、距离度量方法
(一)曼哈顿距离
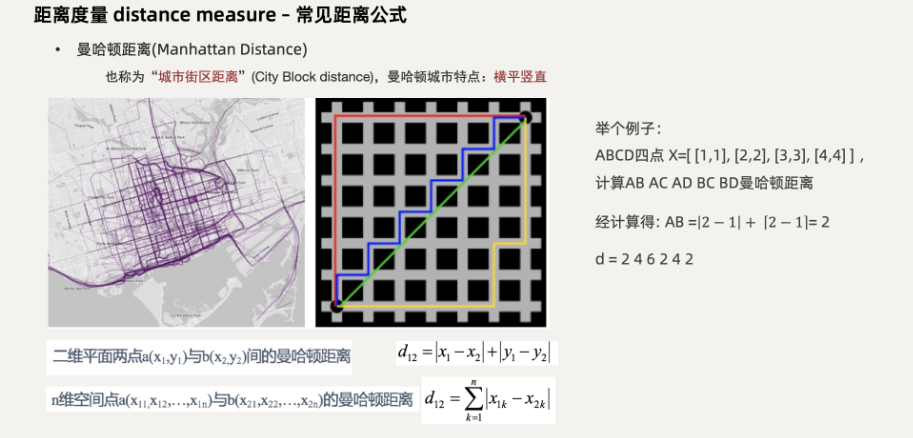
(二)切比雪夫距离
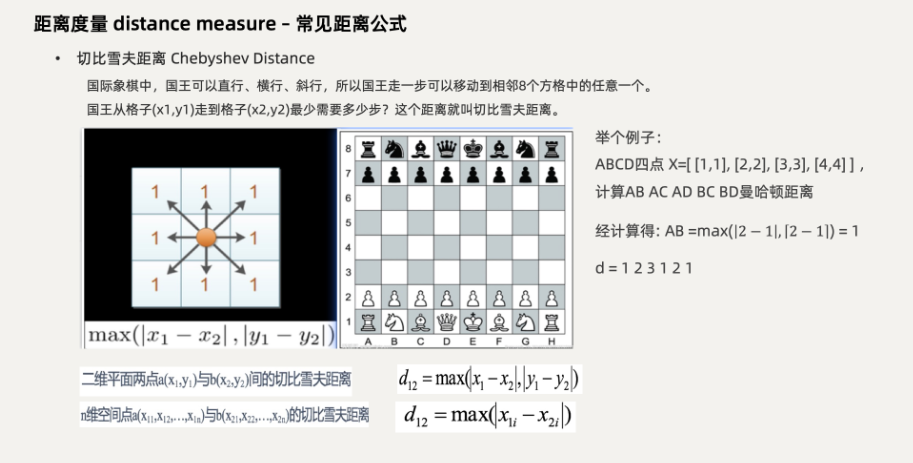
(三)闵式距离

五、特征预处理:归一化与标准化
例:
**(一)归一化操作流程**
#归一化操作,主要针对数据量较少场景
#1.导包
from sklearn.preprocessing import MinMaxScaler
#2.加载数据
X_TRAIN=[
[1,2,3,4,5,6,7,8,9,10],
[11,12,13,14,15,16,17,18,19,20],
]
X_TEST=[
[21,22,23,24,25,26,27,28,29,30]
]
#3.归一化
scaler = MinMaxScaler(feature_range=(0,1))
#4.特征数据训练集转换
X_TRAIN = scaler.fit_transform(X_TRAIN)
#5.特征数据测试集转换
X_TEST = scaler.transform(X_TEST)
#6.打印
print(X_TRAIN)
print(X_TEST)
**(二)标准化操作流程**
#标准化操作,主要针对大数据场景
#1.导包
from sklearn.preprocessing import StandardScaler
#2.建立标准化对象
scaler = StandardScaler()
#3.特征数据训练集转换
scaler.fit(X_TRAIN)
#4.特征数据测试集转换
X_TRAIN = scaler.fit_transform(X_TRAIN)
#5.特征数据测试集转换
X_TEST = scaler.transform(X_TEST)
#6.打印
print(X_TRAIN)
print(X_TEST)
六、鸢尾花实例
例:
# 导入工具包
from sklearn.datasets import load_iris # 加载鸢尾花测试集的.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 分割训练集和测试集的
from sklearn.preprocessing import StandardScaler # 数据标准化的
from sklearn.neighbors import KNeighborsClassifier # KNN算法 分类对象
from sklearn.metrics import accuracy_score # 模型评估的, 计算模型预测的准确率
# 1. 定义函数 dm01_loadiris(), 加载数据集.
def dm01_loadiris():
# 1. 加载数据集, 查看数据
iris_data = load_iris()
print(iris_data) # 字典形式, 键: 属性名, 值: 数据.
print(iris_data.keys())
# 1.1 查看数据集
print(iris_data.data[:5])
# 1.2 查看目标值.
print(iris_data.target)
# 1.3 查看目标值名字.
print(iris_data.target_names)
# 1.4 查看特征名.
print(iris_data.feature_names)
# 1.5 查看数据集的描述信息.
print(iris_data.DESCR)
# 1.6 查看数据文件路径
print(iris_data.filename)
# 2. 定义函数 dm02_showiris(), 显示鸢尾花数据.
def dm02_showiris():
# 1. 加载数据集, 查看数据
iris_data = load_iris()
# 2. 数据展示
# 读取数据, 并设置 特征名为列名.
iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
# print(iris_df.head(5))
iris_df['label'] = iris_data.target
# 可视化, x=花瓣长度, y=花瓣宽度, data=iris的df对象, hue=颜色区分, fit_reg=False 不绘制拟合回归线.
sns.lmplot(x='petal length (cm)', y='petal width (cm)', data=iris_df, hue='label', fit_reg=False)
plt.title('iris data')
plt.show()
# 3. 定义函数 dm03_train_test_split(), 实现: 数据集划分
def dm03_train_test_split():
# 1. 加载数据集, 查看数据
iris_data = load_iris()
# 2. 划分数据集, 即: 特征工程(预处理-标准化)
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2,
random_state=22)
print(f'数据总数量: {len(iris_data.data)}')
print(f'训练集中的x-特征值: {len(x_train)}')
print(f'训练集中的y-目标值: {len(y_train)}')
print(f'测试集中的x-特征值: {len(x_test)}')
# 4. 定义函数 dm04_模型训练和预测(), 实现: 模型训练和预测
def dm04_model_train_and_predict():
# 1. 加载数据集, 查看数据
iris_data = load_iris()
# 2. 划分数据集, 即: 数据基本处理
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3. 数据集预处理-数据标准化(即: 标准的正态分布的数据集)
transfer = StandardScaler()
# fit_transform(): 适用于首次对数据进行标准化处理的情况,通常用于训练集, 能同时完成 fit() 和 transform()。
x_train = transfer.fit_transform(x_train)
# transform(): 适用于对测试集进行标准化处理的情况,通常用于测试集或新的数据. 不需要重新计算统计量。
x_test = transfer.transform(x_test)
# 4. 机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=5)
estimator.fit(x_train, y_train)
# 5. 模型评估.
# 场景1: 对抽取出的测试集做预测.
# 5.1 模型评估, 对抽取出的测试集做预测.
y_predict = estimator.predict(x_test)
print(f'预测结果为: {y_predict}')
# 场景2: 对新的数据进行预测.
# 5.2 模型预测, 对测试集进行预测.
# 5.2.1 定义测试数据集.
my_data = [[5.1, 3.5, 1.4, 0.2]]
# 5.2.2 对测试数据进行-数据标准化.
my_data = transfer.transform(my_data)
# 5.2.3 模型预测.
my_predict = estimator.predict(my_data)
print(f'预测结果为: {my_predict}')
# 5.2.4 模型预测概率, 返回每个类别的预测概率
my_predict_proba = estimator.predict_proba(my_data)
print(f'预测概率为: {my_predict_proba}')
# 6. 模型预估, 有两种方式, 均可.
# 6.1 模型预估, 方式1: 直接计算准确率, 100个样本中模型预测正确的个数.
my_score = estimator.score(x_test, y_test)
print(my_score) # 0.9666666666666667
# 6.2 模型预估, 方式2: 采用预测值和真实值进行对比, 得到准确率.
print(accuracy_score(y_test, y_predict))
# 在main方法中测试.
if __name__ == '__main__':
# 1. 调用函数 dm01_loadiris(), 加载数据集.
# dm01_loadiris()
# 2. 调用函数 dm02_showiris(), 显示鸢尾花数据.
# dm02_showiris()
# 3. 调用函数 dm03_train_test_split(), 查看: 数据集划分
# dm03_train_test_split()
# 4. 调用函数 dm04_模型训练和预测(), 实现: 模型训练和预测
dm04_model_train_and_predict()
**【附赠】网格搜索和交叉验证在鸢尾花实例上的应用:**
# 4. 模型训练.
# 4.1 创建估计器对象.
estimator = KNeighborsClassifier()
# 4.2 使用校验验证网格搜索. 指定参数范围.
param_grid = {"n_neighbors": range(1, 10)}
# 4.3 具体的 网格搜索过程 + 交叉验证.
# 参1: 估计器对象, 参2: 参数范围, 参3: 交叉验证的折数.
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=5)
# 具体的模型训练过程.
estimator.fit(x_train, y_train)
# 4.4 交叉验证, 网格搜索结果查看.
print(estimator.best_score_) # 模型在交叉验证中, 所有参数组合中的最高平均测试得分
print(estimator.best_estimator_) # 最优的估计器对象.
print(estimator.cv_results_) # 模型在交叉验证中的结果.
print(estimator.best_params_) # 模型在交叉验证中的结果.
# 5. 得到最优模型后, 对模型重新预测.
estimator = KNeighborsClassifier(n_neighbors=6)
estimator.fit(x_train, y_train)
print(f'模型评估: {estimator.score(x_test, y_test)}') # 因为数据量和特征的问题, 该值可能小于上述的平均测试得分.
备注:如果存在中文乱码问题,可如下设置:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
即 通过设置全局变量(默认字体设为‘SimHei’【支持中文】和将unicode里的负号禁止不用【默认的负号无法被识别,禁用后将不再影响】)来处理乱码。
以上代码的简洁版:
#导包
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV,train_test_split
from sklearn.datasets import load_iris
import seaborn as sns
#解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#加载数据集
def iris_data():
data=load_iris()
# print(data)
iris=pd.DataFrame(data.data,columns=data.feature_names)
iris['类别']=data.target
iris.columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度','类别']
print(iris.head())
return iris
if __name__=='__main__':
iris=iris_data()
# 绘制回归图,fit_reg=Ture:展示回归线
sns.lmplot(data=iris,x='花萼长度',y='花萼宽度',hue='类别',fit_reg=True)#一种绘图方式
# iris.plot(kind='scatter',x='花萼长度',y='花萼宽度') #另一种绘图方式,但没有sns精致
plt.show()
#切割数据
x_train,x_test,y_train,y_test=train_test_split(iris[['花萼长度','花萼宽度','花瓣长度','花瓣宽度']],iris['类别'],test_size=0.3,random_state=88)
# 数据标准化
knn=StandardScaler()
new_x_train=knn.fit_transform(x_train)
new_x_test=knn.transform(x_test)
# 训练模型
aa=KNeighborsClassifier()
aa=GridSearchCV(aa,param_grid={'n_neighbors':[i for i in range(1,11)]},cv=4)
aa.fit(new_x_train,y_train)
#打印最佳参数,最佳得分,整体参数
print(aa.best_score_,aa.best_params_,aa.cv_results_['params'])
#预测并打印准确率
print(accuracy_score(aa.predict(new_x_test),y_test))
print(aa.score(new_x_test,y_test))

















 4039
4039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









