







 本文介绍了一种名为CostFormer的方法,它是基于Transformer的代价体聚合解决方案,用于改进多视角立体三维重建。CostFormer通过深度感知的局部注意力机制降低计算复杂度,克服了传统方法的局限。实验结果显示了其在提高重建效果和效率方面的优势。
本文介绍了一种名为CostFormer的方法,它是基于Transformer的代价体聚合解决方案,用于改进多视角立体三维重建。CostFormer通过深度感知的局部注意力机制降低计算复杂度,克服了传统方法的局限。实验结果显示了其在提高重建效果和效率方面的优势。
一、论文题目:
CostFormer: Cost Transformer for Cost Aggregation in Multi-view Stereo,https://arxiv.org/abs/2305.10320
二、论文简介:
多视角立体是三维重建的一种重要实现方式,该方式会从一系列同一场景但不同视角的二维影像中重建该场景的三维信息;近几年,深度学习已经广泛应用于基于学习的多视角立体,比如开山之作MVSNET及其后续的改进CasMVSNet,其核心是源像素和参考像素的匹配,而代价体聚合又是其中的关键步骤;相比于卷积神经网络,Transformer是一种基于自注意力机制的深度结构,其全局的注意力机制可以克服卷积神经网络有限的局部感受野问题,因此近两年已有方法把Transformer应用到多视角立体上,比如TransMVSNet把Transformer用于提取图像特征的特征金字塔网络,但在只采用卷积的代价体聚合上,仍然会由于卷积的缺陷而产生错误的匹配,因此如何把Transformer用于代价体聚合成为一个新的改进方向,相比于图像特征,代价体多了一个深度的维度,在设计自注意力机制的时候不仅需要像图像特征那样考虑空间维度,同时也要做到深度感知,但同时由于自注意力机制指数级别增长的复杂度,且代价体各个维度的值都比较高,直接把全局自注意力机制应用于高维度的代价体,很容易引起显存的耗尽以及推理时间的大幅增长。
在此背景下,我们提出一种基于代价体Transformer的多视角立体三维重建方法,该方法设计了一种高效的Transformer,即CostFormer,改善了卷积神经网络代价体聚合的缺陷,从而进一步改善整体重建的效果;CostFormer做到深度感知的同时也克服了全局自注意力机制指数级别增长复杂度带来的显存的耗尽以及推理时间的大幅增长。CostFormer是一种可即插即用于当前基于卷积神经网络的多视角立体方法。
三、方法:
1.)Overview:
按照已有的多视角立体网络搭建起基础结构,一般包括通过金字塔网络提取多层级的金字塔特征,可微的warping,代价体构建,代价体聚合正则,以及深度或视差回归;基于PatchMatchNet的CostFormer结构如下:
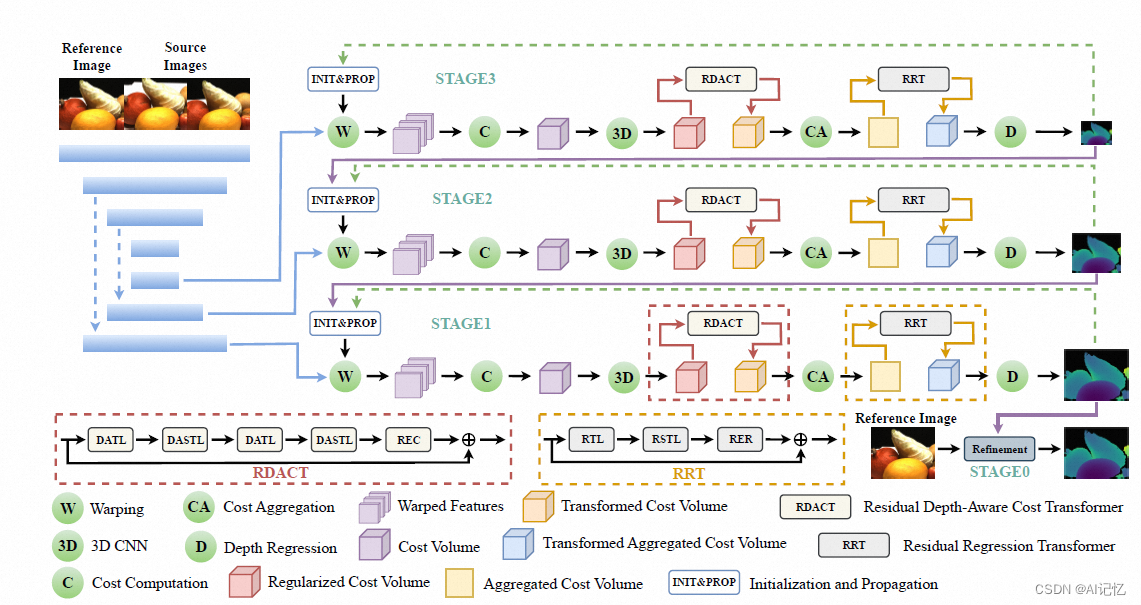
2.)RDACT:
其中RDACT整体结构图如下图,由基于窗口的深度感知Transformer层(DATL)和深度感知的移位Transformer层(DASTL)以及重嵌入代价层(REC)堆叠而成。

假定嵌入前的代价体C0,其通道数为G,通过深度感知的块嵌入层后,完成对对空间尺寸进行降采样并保持深度,假定嵌入后的代价体通道数为E。一般而言,深度感知的块嵌入层由3D卷积和LN组成;那么![]() 由第k层的DATL和DASTL对第k-1层的结果进行处理得到:
由第k层的DATL和DASTL对第k-1层的结果进行处理得到:
![]()
我们提出一种深度感知的窗口,该窗口从2维的空间窗口扩展而来,沿着空间和深度坐标,该窗口的大小为hs x ws x ds;假设一个嵌入后的代价体块宽,高,深分别为![]() ,
,![]() 和
和![]() 。该窗口滑动过整个代价体块,把这个代价体块切割成
。该窗口滑动过整个代价体块,把这个代价体块切割成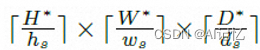 个小块,每个小块可以视作Transformer的token。假设其中的一个小块
个小块,每个小块可以视作Transformer的token。假设其中的一个小块![]() ,其中G为特征通道数;那么Q, K和V由下式得到:
,其中G为特征通道数;那么Q, K和V由下式得到:
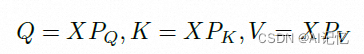
其中![]() 是投影矩阵,Q, K和V都属于
是投影矩阵,Q, K和V都属于![]() ,那么在局部3维窗口内的深度感知自注意力1(DA-SA1)表示如下:
,那么在局部3维窗口内的深度感知自注意力1(DA-SA1)表示如下:
![]()
其中![]() 是由Q,K,V进行reshape而来。深度和空间感知的相对位置偏置B1
是由Q,K,V进行reshape而来。深度和空间感知的相对位置偏置B1![]()
![]() 。
。
那么由多头深度感知注意力机制1和LN构成的DATL处理如下:
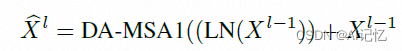
同理在局部深度维度轴线上的深度感知自注意力2(DA-SA2)的表示如下:
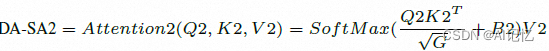
其中![]() 亦由Q,K,V reshape而来。深度感知的相对位置偏置B2
亦由Q,K,V reshape而来。深度感知的相对位置偏置B2![]()
![]() ;那么由多头深度感知自注意力机制1和2以及LN构成的DATL处理如下:
;那么由多头深度感知自注意力机制1和2以及LN构成的DATL处理如下:
![]()
深度感知的相对位置偏置B1和B2都有沿着深度的维度,且在该维度上范围![]() 。注意力机制后是一个由两层全连接层,GELU激活函数组成的MLP模块,DATL接下来的处理如下:
。注意力机制后是一个由两层全连接层,GELU激活函数组成的MLP模块,DATL接下来的处理如下:
![]()
相比于全局的自注意力机制,这些深度感知的局部注意力机制大幅降低了计算复杂度和耗时,使得自注意力在高分辨率下计算成为可能,但由于这些固定位置的局部窗口相互之间没有交集,仍不能有效克服卷积神经网络受限感受野的问题,因此需要进一步通过移位让这些局部窗口相互间进行交互;在下一层级,这些窗口会沿着高,宽和深度轴进行移位,具体移位为![]() ,参照之前没移位的情况,新的深度感知自注意力机制将在这些移位后的窗口内进行计算,具体处理过程如下:
,参照之前没移位的情况,新的深度感知自注意力机制将在这些移位后的窗口内进行计算,具体处理过程如下:
![]()
![]()
其中DAS-MSA1为移位的多头深度感知自注意力1,DAS-MSA2为移位的多头深度感知自注意力2。
在注意力计算后,![]() 的特征通道数也为E,我们需要通过REC把它恢复到G,再和C0进行残差连接,得到RDACT的最终结果:
的特征通道数也为E,我们需要通过REC把它恢复到G,再和C0进行残差连接,得到RDACT的最终结果:
![]()
一般而言,重嵌入代价层是一个输出通道数为G的3维卷积;特别的,如果E=G,那么重嵌入代价层就是保持层:
![]()
3.)RRT:
RRT整体结构图如下图:
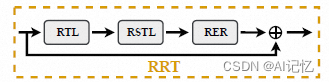
聚合后的代价体![]() 将进一步进行深度回归,参照RDACT,我们把深度视作特征数,提出残差回归Transformer:
将进一步进行深度回归,参照RDACT,我们把深度视作特征数,提出残差回归Transformer:
![]()
![]()
其中![]() 是第k个回归Transformer层,
是第k个回归Transformer层,![]() 是第k个移位回归Transformer层;这两种Transformer层都只在空间窗口上进行计算,是非深度感知的。RER是恢复深度信息的重嵌入层,通常情况下它是一个输出维度为D的二维矩阵,如果嵌入维度为D,那么该层也等同于保持层。
是第k个移位回归Transformer层;这两种Transformer层都只在空间窗口上进行计算,是非深度感知的。RER是恢复深度信息的重嵌入层,通常情况下它是一个输出维度为D的二维矩阵,如果嵌入维度为D,那么该层也等同于保持层。
损失函数:
Final loss combines with the losses of all iterations at all stages and the loss from the final refinement module:
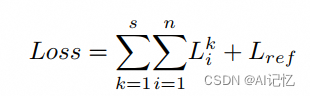
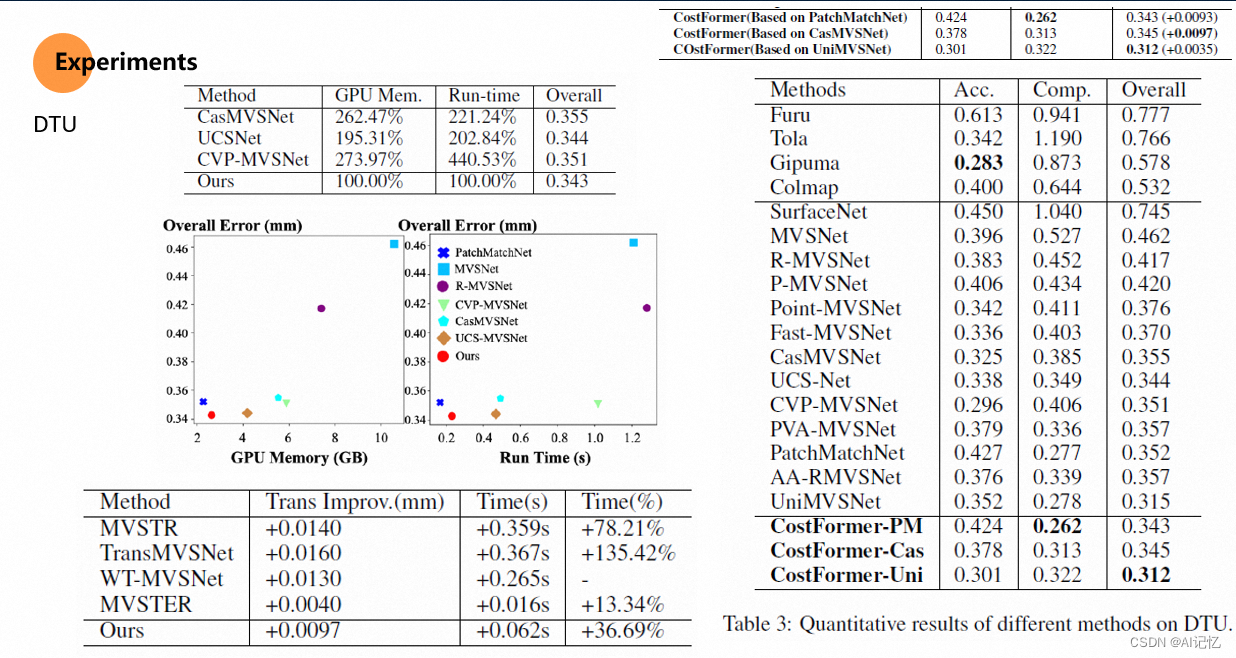
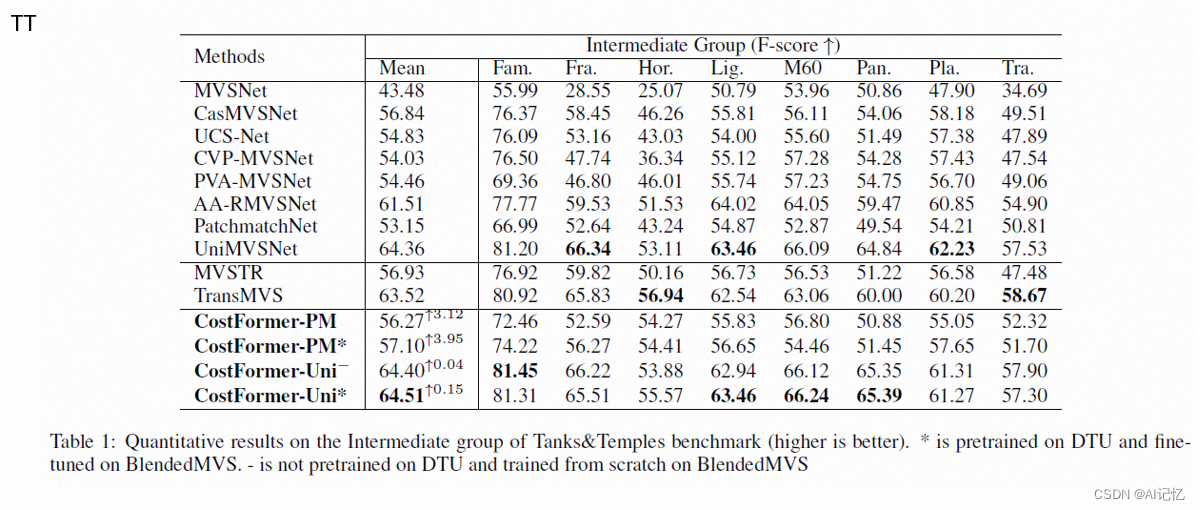
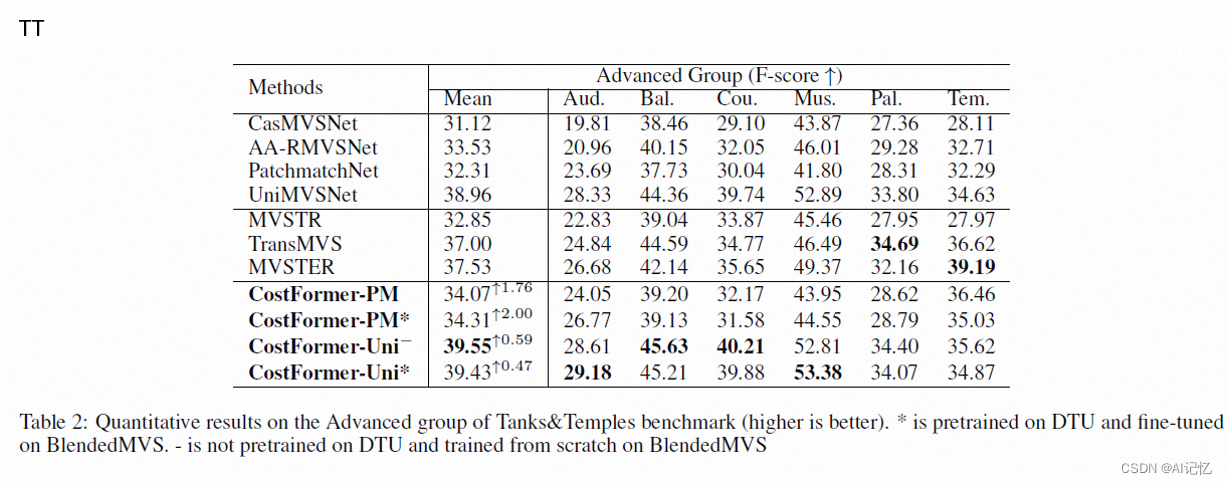
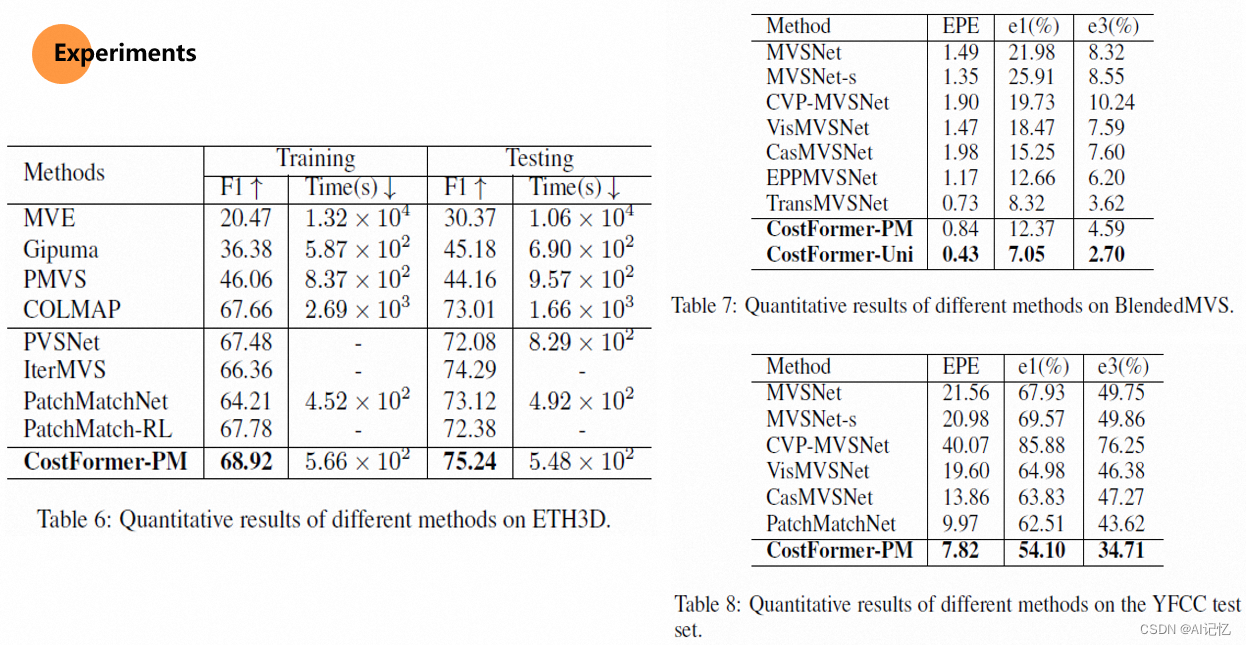
四、实验结果:






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











