#coding:utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#import MNIST_data.input_data as input_data
import time
"""
权重初始化
初始化为一个接近0的很小的正数
"""
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1) #随机生成数
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
"""
卷积和池化,使用卷积步长为1(stride size),0边距(padding size)
池化用简单传统的2x2大小的模板做max pooling
"""
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding = 'SAME')
# tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
# x(input) : [batch, in_height, in_width, in_channels]
# W(filter) : [filter_height, filter_width, in_channels, out_channels]
# strides : The stride of the sliding window for each dimension of input.
# For the most common case of the same horizontal and vertices strides, strides = [1, stride, stride, 1]
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1],
strides = [1, 2, 2, 1], padding = 'SAME')
# tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
# x(value) : [batch, height, width, channels]
# ksize(pool大小) : A list of ints that has length >= 4. The size of the window for each dimension of the input tensor.
# strides(pool滑动大小) : A list of ints that has length >= 4. The stride of the sliding window for each dimension of the input tensor.
start = time.clock() #计算开始时间
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #MNIST数据输入
"""
第一层 卷积层
x_image(batch, 28, 28, 1) -> h_pool1(batch, 14, 14, 32)
"""
x = tf.placeholder(tf.float32,[None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1]) #最后一维代表通道数目,如果是rgb则为3
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# x_image -> [batch, in_height, in_width, in_channels]
# [batch, 28, 28, 1]
# W_conv1 -> [filter_height, filter_width, in_channels, out_channels]
# [5, 5, 1, 32]
# output -> [batch, out_height, out_width, out_channels]
# [batch, 28, 28, 32]
h_pool1 = max_pool_2x2(h_conv1)
# h_conv1 -> [batch, in_height, in_weight, in_channels]
# [batch, 28, 28, 32]
# output -> [batch, out_height, out_weight, out_channels]
# [batch, 14, 14, 32]
"""
第二层 卷积层
h_pool1(batch, 14, 14, 32) -> h_pool2(batch, 7, 7, 64)
"""
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# h_pool1 -> [batch, 14, 14, 32]
# W_conv2 -> [5, 5, 32, 64]
# output -> [batch, 14, 14, 64]
h_pool2 = max_pool_2x2(h_conv2)
# h_conv2 -> [batch, 14, 14, 64]
# output -> [batch, 7, 7, 64]
"""
第三层 全连接层
h_pool2(batch, 7, 7, 64) -> h_fc1(1, 1024)
"""
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
"""
Dropout
h_fc1 -> h_fc1_drop, 训练中启用,测试中关闭
"""
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
"""
第四层 Softmax输出层
"""
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
"""
训练和评估模型
ADAM优化器来做梯度最速下降,feed_dict中加入参数keep_prob控制dropout比例
"""
y_ = tf.placeholder("float", [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv)) #计算交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #使用adam优化器来以0.0001的学习率来进行微调
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) #判断预测标签和实际标签是否匹配
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
sess = tf.Session() #启动创建的模型
sess.run(tf.initialize_all_variables()) #旧版本
#sess.run(tf.global_variables_initializer()) #初始化变量
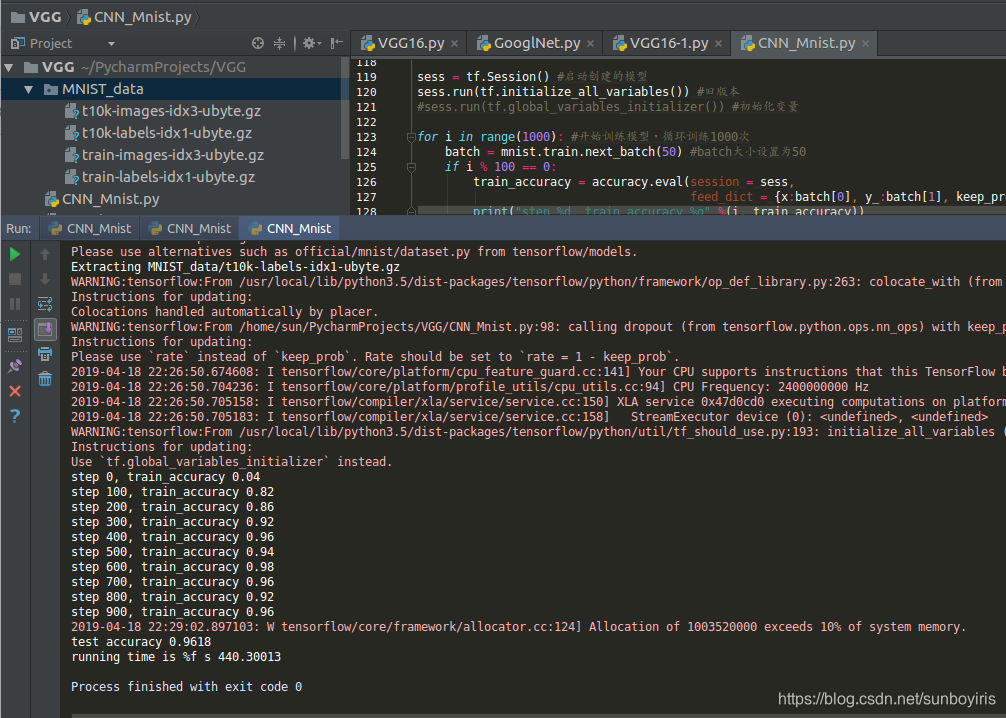
for i in range(5000): #开始训练模型,循环训练5000次
batch = mnist.train.next_batch(10) #batch大小设置为10
if i % 100 == 0:
train_accuracy = accuracy.eval(session = sess,
feed_dict = {x:batch[0], y_:batch[1], keep_prob:1.0})
print("step %d, train_accuracy %g" %(i, train_accuracy))
train_step.run(session = sess, feed_dict = {x:batch[0], y_:batch[1],
keep_prob:0.5}) #神经元输出保持不变的概率 keep_prob 为0.5
print("test accuracy %g" %accuracy.eval(session = sess,
feed_dict = {x:mnist.test.images, y_:mnist.test.labels,
keep_prob:1.0})) #神经元输出保持不变的概率 keep_prob 为 1,即不变,一直保持输出
end = time.clock() #计算程序结束时间
print("running time is %g s") % (end-start)






















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









