







源码:
注:
import clusters 来源于另外一篇博客
参考链接这里写链接内容
data数据集由generatefeedvector.py生成
参考链接这里写链接内容
# --coding:utf-8--
import random
import clusters
def kcluster(rows,distance =clusters.pearson,k=4):
#q确定每个点的最大值和最小值
ranges = [(min(row[i] for row in rows),max(row[i] for row in rows))for i in range(len(rows[0]))]
#随机产生k个中心点
kclusters = [[random.random() * (ranges[i][1] - ranges[i][0]) + ranges[i][0] for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print "Iteration %d" %t
bestmatches=[[] for i in range(k)]
#在每行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch = 0
for i in range(k):
d = distance(kclusters[i],row)
if d < distance(kclusters[bestmatch],row):
bestmatch = i
bestmatches[bestmatch].append(j)
#如果结果与上次相同,则结束迭代
if bestmatches == lastmatches:
break
lastmatches = bestmatches
#把中心点移到中心位置
for i in range(k):
avgs = [0.0] * len(rows[0])
if len(bestmatches[i]) > 0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m] += rows[rowid][m]
for j in range(len(avgs)):
avgs[j] / len(bestmatches[i])
kclusters[i] = avgs
return bestmatches
blognames,words,data = clusters.readfile(r"D:\subject\PycharmProjects\blogdata")
k = kcluster(data)
print k
print len(k)
for row in k:
for id in row:
print blognames[id]
print "**********"数据集:
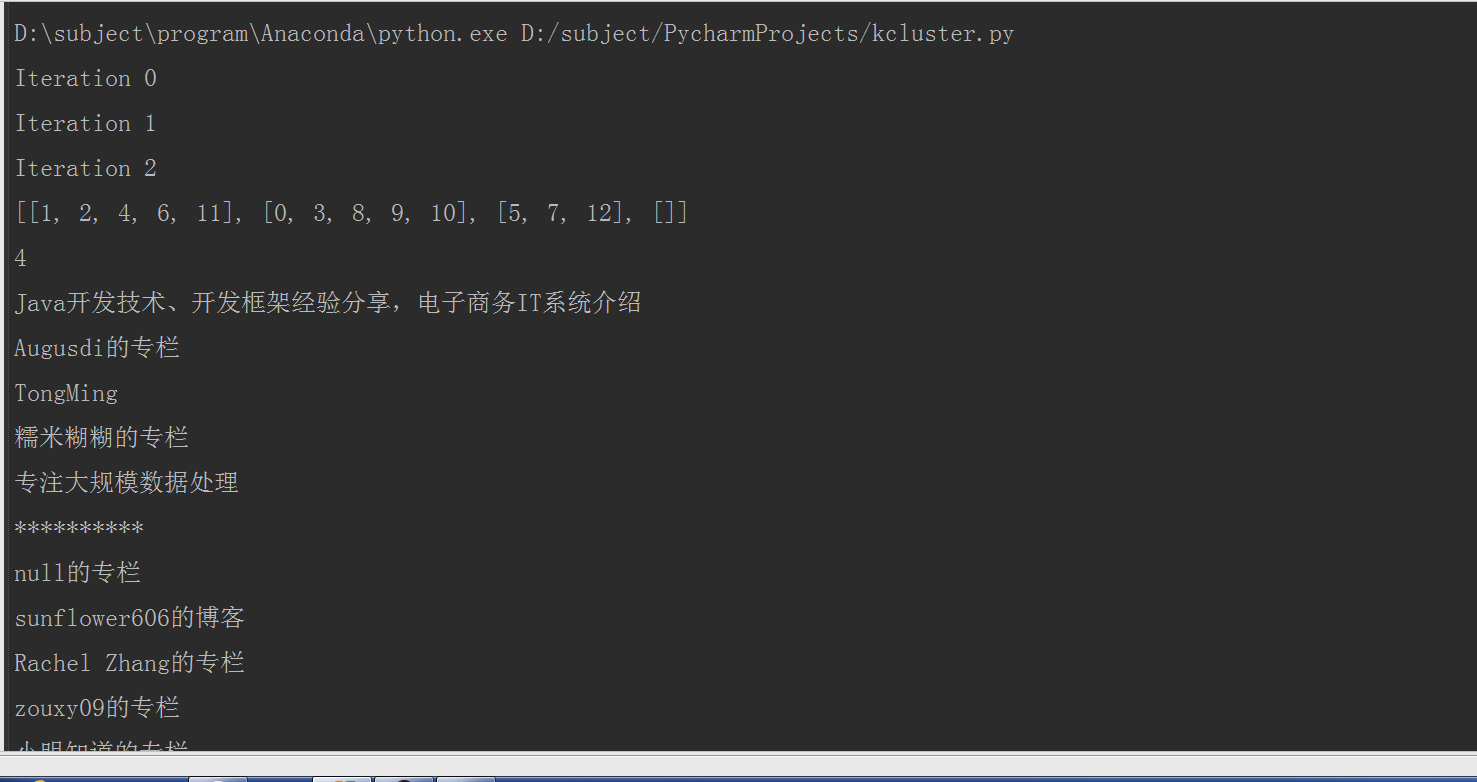
实验结果:
k=4时
k=8时
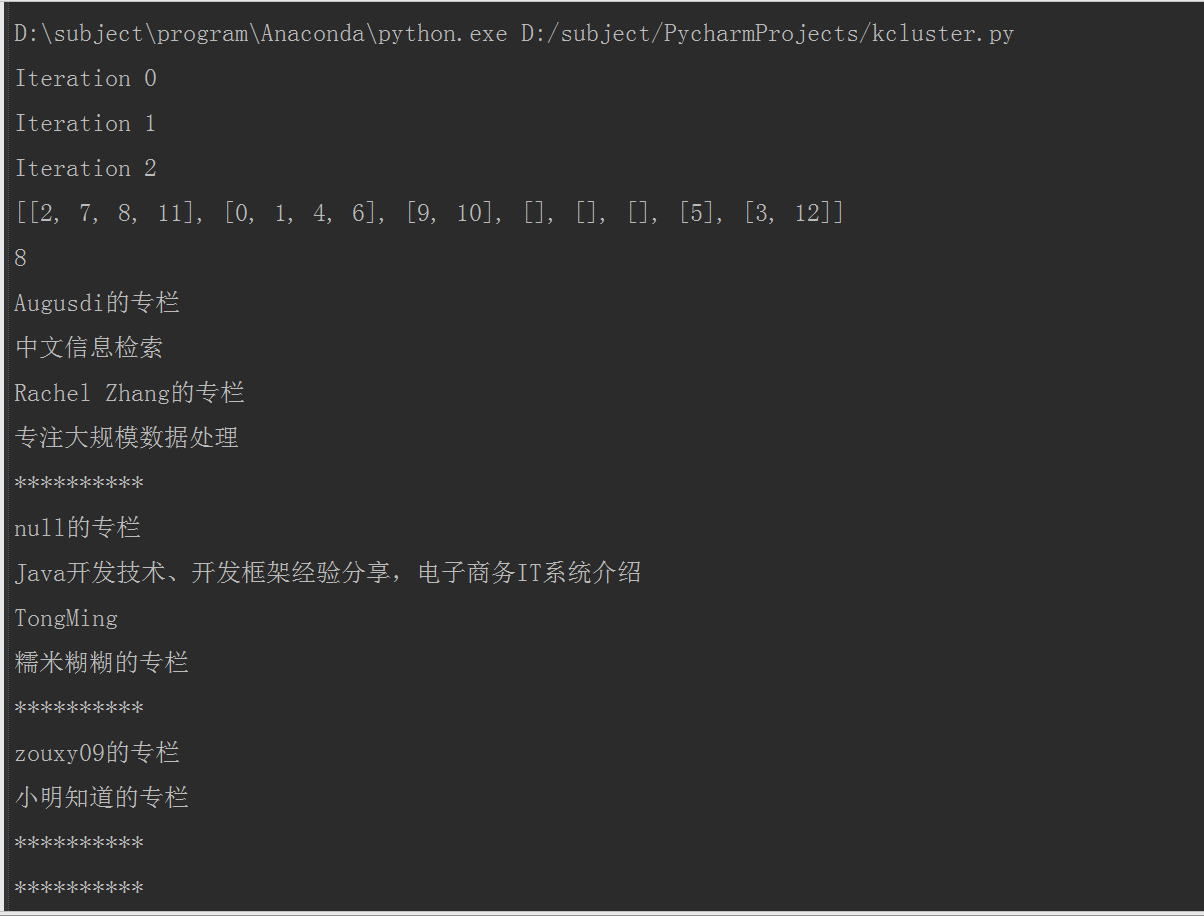
参数可以自己设定















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









