






概述
FRI (Fast Reed-Solomon IOPP)是零知识证明协议ZK-STARK的核心。ZK-STARK协议主要可以分为两部分内容:
- 算术化:将程序的执行过程转化为一个算术问题,这个算术问题被称为RPT (Reed-Solomon Proximity Testing)
- FRI协议:即针对RPT问题设计的零知识证明协议
所以,FRI只是零知识证明的一个部件,而不是零知识证明本身。其功能与KGZ10的功能类似。
KGZ10中,欲证明一个多项式f(1) = 2,则需要证明是一个多项式。
同理,FRI的过程就是证明p(x)是多项式且是一个次数不高于degree(f(x)) - 1的多项式。
Reed-Solomon编码
所谓的Reed Solomon编码,下文称RS码,就是利用多项式冗余进行纠错的编码。已知d个点值可以唯一确定一个阶数不大于d-1的多项式f(x),在编码时对f(x)的N个点值进行编码,接收方接收到的码字中只要包含足够多正确的点值,则可以恢复出正确的多项式,并纠正错误的点。
举例如下:
设编码大小为N。给定一个集合.。待编码的内容为d个元素
,编码过程如下进行:设多项式
,编码结果为
,即多项式f(x)在集合S指定的这N个点上的取值,简洁起见,将这个编码记为f(S)。
即将d个有效元素编码为长度为N的码字。我们记码率为。
对于两个不同的d-1次多项式,在这N个点中,最多有d−1个点上的取值相等,所以两个不同的编码,至少有N−d+1个位置不同。因此,这样的编码可以容纳N−d个随机的错误(即当码字的错误元素小于等于N-d时,可以通过正确的d个码元恢复出原始正确码字来)。显然,如果N=d,这个编码毫无容错性,即该编码没有检错功能。
一个RS码记为,其中
RPT问题
简单来说,RPT (RS Proximity Testing)问题是给定一个长度为N的编码,判断它是否属于,即判断一个编码是否是一个合法的RS编码,即判断该编码恢复出的是不是一个degree < ρN 的一个多项式。
RPT问题还有另外一个限制条件:它的输入要么是一个合法的编码,要么和所有合法的编码都有至少δN个位置不同。这就是它的名称中Proximity这个词的意思。
RPT问题最简单直接的方法是对给定的编码进行解码,即多项式插值,恢复出多项式f(x)的各项系数。如果f(x)的次数不大于ρNρN,则输出1,否则输出0。实际上,作为一个纠错码,RS码最初设计来就是这么用的。
RPT是否存在更高效的解法?例如,能否不读取完整的编码,即完整的f(S),只读取其中一小部分(logN级别),就能够以大概率作出准确的判断?FRI就是在做这样的事情。
注:
目前对于的取值,认可度比较高的是Johnson bound,即
FRI
概述
FRI全称为Fast Reed-Solomon Interactive Oracle Proofs of Proximity。
FRI的思想与FFT思想类似,即通过将多项式的奇偶项进行拆分(split),再将降次后的奇偶多项式进行线性组合(fold),可以将多项式的次数降低为原来的1/2,这样对degree<d的多项式,最多进行logd次拆分后便可得到一个常量。
假设原始多项式为,
的偶数次项多项式为g(x), 奇数次项多项式为h(x),则:
(1)
可以知道:
g(x) 和h(x)为次数不高于d/2的多项式,此时证明的degree < d,转换为了证明g(x) 和h(x)的degree < d/2,可以将这两个多项式进行线性组合:
(2)
此时经过split-fold得到第一层,依次向下类推,最多进行logd次split-fold,变得到了一组常量。verifier需要给出各层fold的随机数,并发出query,prover则需要对各层进行进行commit和提供verifier query的数据和证明。
FRI 的commitment是每一层全部点值构成的merkle树的root
注:假设所有元素都是有限域F上的元素,中的x的集合是
,
为F的乘法子群,
则中的x的集合
是
的乘法子群,且元素个数为
的1/2。
详细过程
FRI分为commit和query两个阶段。
commit阶段
1.FRI原始多项式为,prover提供
的commit,即该层点值构成的merkle树的root
2. prover提供随机数, prover进行fold-split,根据上述公式(2)得到
,并求该层所有点值,构造merkle tree,并将root发送给prover.
3. ....
4.以此类推,直至prover发送verifier一组常量
query阶段
用户指定上的某个位置索引,prover提供各层路径上涉及到的值,以及merkle proof.
如下,如果prover指定要验证在x处的值,在prover需要提供
和最后一层的常量,
verifier需要验证两个内容:
(1)相邻层之间的数据是否满足上述公式(2)
(2)每一层的merkle proof是否成立
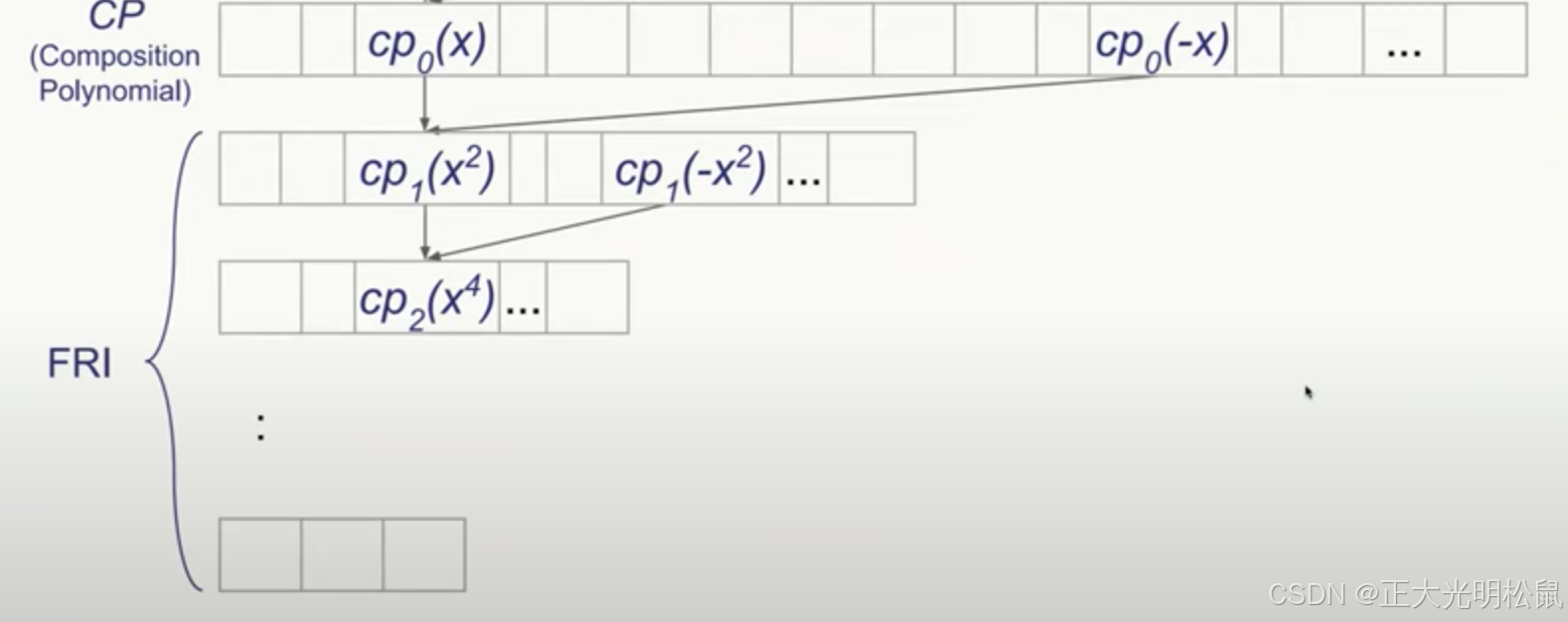
可以发现,验证仅需要logd组数据,每层的proof大小为logd.
soundness
为了将错误放大,其实中的点集是进行了RS code编码后的结果。
为什么说RS编码将错误放大了呢?如果prover不知道多项式或者想对多项式进行造假,则码字越长,其出错的位概率上越大,那我们采样验证时,暴露其错误的概率越大。
每次query,会得到比特的正确率,
为上面介绍的码率。需要的正确率越高,则需要的query次数越多。
参考文献:
深入zk-STARK原理和安全性分析 - 深入理解zk-STARK证明系统
https://trapdoor-tech.github.io/zkstark-book/chapter_3.html

















 1434
1434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









