







转自:http://superangevil.wordpress.com/2010/03/16/basic_collaborative_filtering/
特别详细的资料
推荐系统中,协同过滤(Collaborative Filtering)技术已经获得了相当广泛的成功,最著名的就是Amazon,这里就不多说了。虽然是互联网上迟到的80后,但我们还是有热情去在互联网的舞台上脚踏实地的去拼搏、去奋斗。说到“脚踏实地”,一直以为CF没啥,现在觉得还是应该踏踏实实把它记录下来,算是对自己的积淀吧。
0. 数据准备:
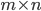 阶user-item关系的rating矩阵:
阶user-item关系的rating矩阵: 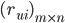 — 行代表user,列代表item
— 行代表user,列代表item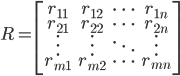
1. User-Based Collaborative Filtering
STEP1. 对user u,计算u与其他每个user v的相似度:
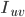 为user u和user v都打过分的items集合
为user u和user v都打过分的items集合
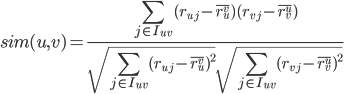
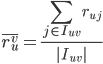 ,
,
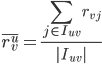
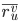 表示user u对
表示user u对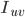 中items打分的均值;
中items打分的均值; 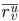 表示user v对
表示user v对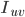 中items打分的均值。
中items打分的均值。此种度量方式实际上是调整后的cosine相似度(还有很多相似度度量方式,比如Euclidean Distance, Pearson Correlation等等,具体选用哪种相似度度量方式,要根据具体应用和数据的具体特点而定)。
STEP2. 这样,对user u,就找到了u与其他用户的相似度度量,根据相似度排序,取top-k个用户(kNN过程—找到了k个最近邻):
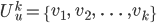 为排好序的与user u最近似的k个最近邻,相应的相似度为
为排好序的与user u最近似的k个最近邻,相应的相似度为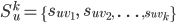
此步的一个直接结果就是找到了相似用户。
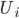 为对item i打过分的users集合
为对item i打过分的users集合
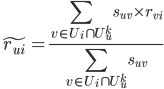

STEP1. 对任意两个item i, j,计算它们之间的相似度:
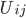 为对item i和item j都打过分的users集合
为对item i和item j都打过分的users集合
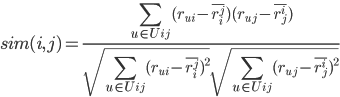
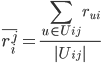
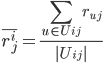
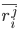 表示
表示
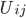 中的users对item i打分的均值;
中的users对item i打分的均值;
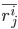 表示
表示
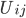 中的users对item j打分的均值。
中的users对item j打分的均值。
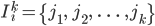 为排好序的与item i最近似的k个最近邻,相应的相似度为
为排好序的与item i最近似的k个最近邻,相应的相似度为
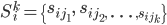
此步的直接结果是找到了相似物品。
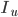 为user u打过分的items集合
为user u打过分的items集合
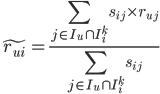
用user u打过分且在item i相似kNN的items集中打分的加权凭据作为u对i喜欢程度的预测,同样找到user u对起未关注国的item i的可能喜欢程度;对u所有未打分的items都这样作,就形成了一个预测列表,排序后给出推荐列表。
在 User-based 方法中,随着用户数量的不断增多,在大数量级的用户范围内进行“最近邻搜索”会成为整个算法的瓶颈。
Item-based 方法通过计算项之间的相似性来代替用户之间的相似性。对于项来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而大大降低了在线计算量,提高推荐效率















 3500
3500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









