







推荐系统系列文章目录
Part1 推荐系统基础
Part2 Movienles介
Part3 协同过滤基础
目录
前言
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。它对业界的影响力非常大,并且应用广泛,现有的很多算法也是在协同过滤的基础上演化得到,所以学习并掌握这个算法是非常有必要的。

所谓协同过滤, 基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐),一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。目前应用比较广泛的协同过滤算法是基于邻域的方法, 而这种方法主要有下面两种算法:
- 基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
- 基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
1、基于用户的协同过滤(UserCF)
基于用户的协同过滤(UserCF)可以追溯到1993年, 可以说是非常早的一种算法了, 这种算法的思想其实比较简单, 当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A没有听说过的物品推荐给A。
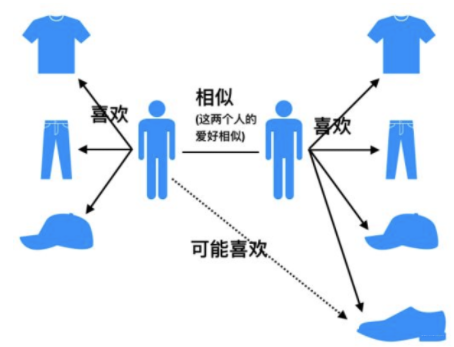
所以基于用户的协同过滤算法主要包括两个步骤:
- 找到和目标用户兴趣相似的集合
- 找到这个集合中的用户喜欢的, 且目标用户没有听说过的物品推荐给用户。
上面的两个步骤中, 第一个步骤里面, 我们会基于前面给出的相似性度量的方法找出与目标用户兴趣相似的用户, 而第二个步骤里面, 如何基于相似用户喜欢的物品来对目标用户进行推荐呢? 这个要依赖于目标用户对相似用户喜欢的物品的一个喜好程度, 那么如何衡量这个程度大小呢? 为了更好理解上面的两个步骤, 下面拿一个具体的例子把两个步骤具体化。
以下图为例,此例将会用于本文各种算法中

给用户推荐物品的过程可以形象化为一个猜测用户对商品进行打分的任务,上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度
应用UserCF算法的两个步骤:
- 首先根据前面的这些打分情况(或者说已有的用户向量)计算一下Alice和用户1, 2, 3, 4的相似程度, 找出与Alice最相似的n个用户
- 根据这n个用户对物品5的评分情况和与Alice的相似程度会猜测出Alice对物品5的评分, 如果评分比较高的话, 就把物品5推荐给用户Alice, 否则不推荐。
下文所使用的的数据集,用户与物品所表达的喜好程度(即评分),如下表所示:

1.1 相似度计算
计算相似度需要根据特点的不同选择不同的相似度计算方法:
1.杰卡德(Jaccard)相似系数
2.余弦相似度
3.皮尔逊相关系数
这里选用的是余弦相似度来计算用户之间的相似度:

针对用户u和v,上述公式中的参数如下。
- N(u):用户u有过评分的物品集合;
- N(v):用户v有过评分的物品集合;
- Wuv:用户u和用户v的余弦相似度。
结合上表,可以分别求得用户C和其他三个用户的相似度,见下面三公式:
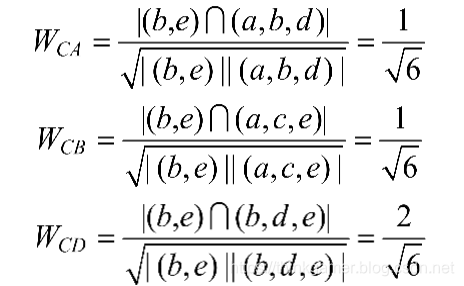
从计算结果来看,D用户与C用户相似度最大。 从表中也可以直接看出,用户D和C都在b和e物品上进行了评分,用户A、B和C也都在b物品上进行了评分。
1.2手动计算推荐结果
用户C进行评分的物品是b和e,接下来计算用户C对物品a、c、d的偏好程度,见下面三公式:

从上面的计算可以得到,在用户C没有进行评分的物品中倒序排列为a→c→e。这样就可以根据需要取前 K个物品推荐给C用户。
算法实现代码如下所示:
def userSimilarity(self):
W=dict()
for u in self.user_score_dict.keys():
W.setdefault(u,{})
for v in self.user_score_dict.keys():
if u==v:
continue
u_set = set([key for key in self.user_score_dict[u].keys() if
self.user_score_dict[u][key]>0])
v_set = set([key for key in self.user_score_dict[v].keys() if
self.user_score_dict[v][key]>0])
W[u][v] = float(len(u_set&v_set))/math.sqrt(len(u_set)*len(v_set))
print((u_set&v_set))
return W算法复杂度优化
但是上面的计算存在一个问题——需要计算每一对用户的相似度。代码实现对应的时间复杂度为O(|U|*|U|),U为用户个数。
在实际生产环境中,很多用户之间并没有交集,也就是并没有对同一样物品产生过行为,所以很多情况下分子为0,这样的稀疏数据就没有计算的必要。
上面的代码实现将时间浪费在计算这种用户之间的相似度上,所以这里可以进行优化:
(1)计算出的用户对(u,v);
(2)对其除以分母得到u和v的相似度。
针对以上优化思路,需要两步:
(1)建立物品到用户的倒排表T,表示该物品被哪些用户产生过行为;
(2)根据倒查表T,建立用户相似度矩阵W:
在T中,对于每个物品i,设其对应的用户为j、k,
在W中,更新对应位置的元素值,W[j][k]=W[j][k]+1,W[k][j]=W[k][j]+1。
以此类推,这样在扫描完倒查表T之后,就能得到一个完整的用户相似度矩阵W了。
这里的W对应的是前面介绍的余弦相似度中的分子部分,然后用W除以分母,便能最终得到两个用户的兴趣相似度。
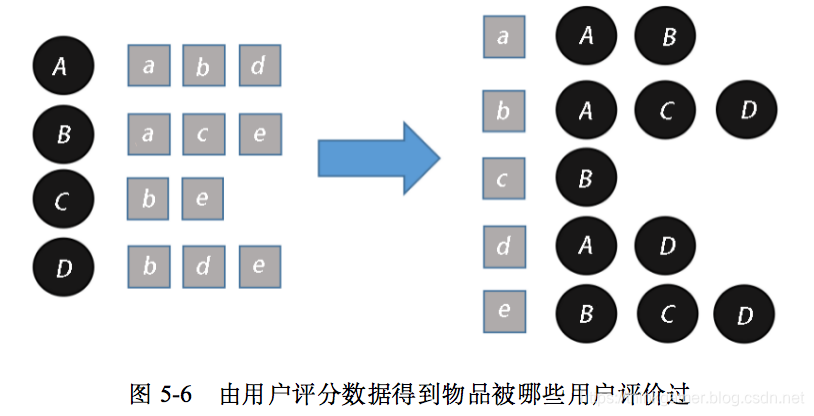
以上表为例,总共有4个用户,那么要建一个4行4列的倒排表,具体建立过程如下:
(1)由用户的评分数据得到每个物品被哪些用户评价过,如图5-6所示。
(2)建立用户相似度矩阵W,如图5-7所示。
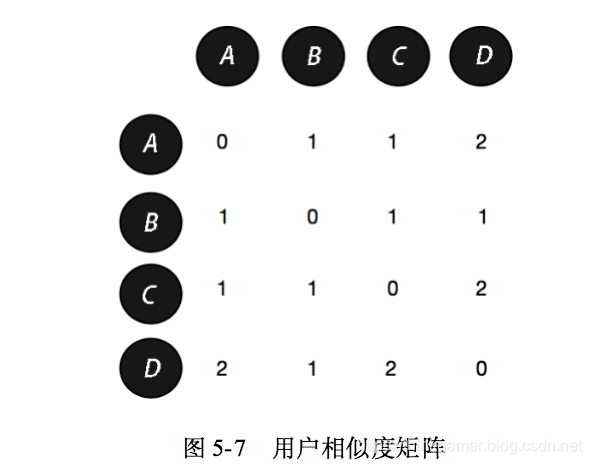
得到的相似度矩阵W对应的是计算两两用户相似度的分子部分,然后除以分母得到的便是两两用户的相似度。
还是以C用户为例。从图5-7可知,A、B用户与C用户相似度计算的分子都为1,D用户与C用户相似度计算的分子部分为2。其他用户与C用户的相似度计算如下:

得到用户的相似度之后,就可以计算用户对未评分物品的可能评分了。采用的计算方式依旧是:
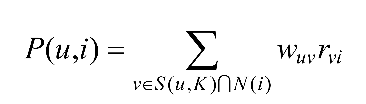
其中各参数说明如下。
P(u,i):用户u对物品i的感兴趣程度;
S(u,K):和用户u兴趣最接近的K个用户;
N(i):对物品i有过行为的用户集合;
Wuv:用户u和用户v的兴趣相似度;
rvi:用户v对物品i的兴趣,即用户对物品的评分。
依据上式,分别计算用户C对物品a、c、d的可能评分:
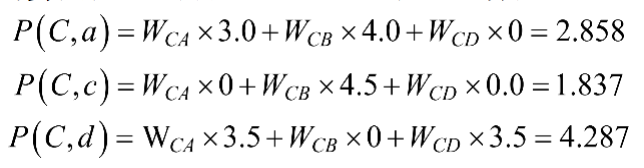
同样,对比优化前后的计算可知,结果是一致的。改进后的代码如下所示:
def userSimilartyBetter(self):
item_users = dict()
# u是键 items是值
#这个遍历相当于对整个字典进行遍历
for u,items in self.user_score_dict.items():
#对于每一个键值对
for i in items.keys():
item_users.setdefault(i,set())
if(self.user_score_dict[u][i])>0:
item_users[i].add(u)
C = dict()
N = dict() #n就是所有物品,所有客户的清单
for i,users in item_users.items():
for u in users:
N.setdefault(u,0)
N[u] += 1
print(N)
C.setdefault(u,{})
for v in users:
C[u].setdefault(v,0)
if u==v:
continue
C[u][v] += 1
print(C)
W = dict()
#u确定了行,v确定了列
for u,related_users in C.items():
W.setdefault(u,{})
for v,cuv in related_users.items():
if u==v:
continue
W[u].setdefault(v,0.0)
W[u][v] = cuv/math.sqrt(N[u]*N[v])
return W但是以上改进后的算法还是存在一些缺点,比如说,如果两个用户都买过《新华字典》,这并不能说明他们兴趣相同,因为绝大多数中国人都买过《新华字典》。
但如果两个用户都买过《机器学习实战》,那可以认为他们的兴趣比较相似,因为只有研究机器学习的人才可能买这本书。
因此,John S. Breese在论文中提出了式(5.4),根据用户行为计算用户的兴趣相似度:
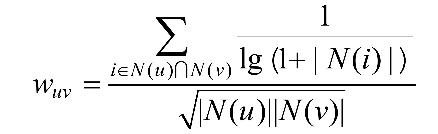
- 分子中的倒数部分,惩罚了用户u和用户v共同兴趣列表中热门物品,减小了热门物品对用户相似度的影响。
- N(i)是对物品i有过行为的用户集合。物品i越热门,N(i)越大。
具体的代码实现如函数userSimilarityBest()所示:
def userSimilaryBest(self):
item_users = dict()
for u,items in self.user_score_dict.items():
for i in items.keys():
item_users.setdefault(i,set())
if self.user_score_dict[u][i]>0:
item_users[i].add(u)
C = dict()
N = dict()
for i,users in item_users.items():
for u in users:
N.setdefault(u,0)
N[u]+=1
C.setdefault(u,{})
for v in users:
C[u].setdefault(v,0)
if u==v:
continue
C[u][v] += 1/math.log(1+len(users))
W = dict()
for u,related_users in C.items():
W.setdefault(u,{})
for v,cuv in related_users.items():
if u==v:
continue
W[u].setdefault(v,0.0)
W[u][v] = cuv/math.sqrt(N[u]*N[v])
return W1.3完整代码和推荐结果
完整代码:
# _*_coding utf-8_*_
# 开发团队: DMU
# 开发人员: $(USER)
# 开发时间: $(DATE)$(TIME)
# 文件名: $(NAME).py
# 开发工具: $(PRODUCT_NAME)
import math
class UserCF:
def __init__(self):
self.user_score_dict = self.initUserScore()
self.users_sim = self.userSimilaryBest()
print(self.users_sim)
def initUserScore(self):
user_score_dict ={
'A':{'a':3.0,'b':4.0,'c':0.0,'d':3.5,'e':0.0},
'B': {'a': 4.0, 'b': 0.0, 'c': 4.5, 'd': 0.0, 'e': 3.5},
'C': {'a': 0.0, 'b': 3.5, 'c': 0.0, 'd': 0.0, 'e': 3.0},
'D': {'a': 0.0, 'b': 4.0, 'c': 0.0, 'd': 3.5, 'e': 3.0}
}
return user_score_dict
#优化的用户相似度
def userSimilaryBest(self):
item_users = dict()
for u,items in self.user_score_dict.items():
for i in items.keys():
item_users.setdefault(i,set())
if self.user_score_dict[u][i]>0:
item_users[i].add(u)
C = dict()
N = dict()
for i,users in item_users.items():
for u in users:
N.setdefault(u,0)
N[u]+=1
C.setdefault(u,{})
for v in users:
C[u].setdefault(v,0)
if u==v:
continue
C[u][v] += 1/math.log(1+len(users))
W = dict()
for u,related_users in C.items():
W.setdefault(u,{})
for v,cuv in related_users.items():
if u==v:
continue
W[u].setdefault(v,0.0)
W[u][v] = cuv/math.sqrt(N[u]*N[v])
return W
def userSimilartyBetter(self):
item_users = dict()
# u是键 items是值
#这个遍历相当于对整个字典进行遍历
for u,items in self.user_score_dict.items():
#对于每一个键值对
for i in items.keys():
item_users.setdefault(i,set())
if(self.user_score_dict[u][i])>0:
item_users[i].add(u)
C = dict()
N = dict() #n就是所有物品,所有客户的清单
for i,users in item_users.items():
for u in users:
N.setdefault(u,0)
N[u] += 1
print(N)
C.setdefault(u,{})
for v in users:
C[u].setdefault(v,0)
if u==v:
continue
C[u][v] += 1
print(C)
W = dict()
#u确定了行,v确定了列
for u,related_users in C.items():
W.setdefault(u,{})
for v,cuv in related_users.items():
if u==v:
continue
W[u].setdefault(v,0.0)
W[u][v] = cuv/math.sqrt(N[u]*N[v])
return W
def userSimilarity(self):
W=dict()
for u in self.user_score_dict.keys():
W.setdefault(u,{})
for v in self.user_score_dict.keys():
if u==v:
continue
u_set = set([key for key in self.user_score_dict[u].keys() if
self.user_score_dict[u][key]>0])
v_set = set([key for key in self.user_score_dict[v].keys() if
self.user_score_dict[v][key]>0])
W[u][v] = float(len(u_set&v_set))/math.sqrt(len(u_set)*len(v_set))
print((u_set&v_set))
return W
def preUserItemScore(self,userA,item):
score=0.0
# score include all of the users info;
for user in self.users_sim[userA].keys():
score += self.users_sim[userA][user]*self.user_score_dict[user][item]
return score
def recommend(self,userA):
user_item_score_dict = dict()
#item is a b c d
for item in self.user_score_dict[userA].keys():
# because we are going to recommend new items
if self.user_score_dict[userA][item] <= 0:
user_item_score_dict[item] = self.preUserItemScore(userA,item)
return user_item_score_dict
if __name__ == "__main__":
ub = UserCF()
print(ub.recommend('C'))
推荐结果:
{'B': {'A': 0.3034130755422791, 'D': 0.2404491734814939, 'C': 0.2944888920518062},
'A': {'B': 0.3034130755422791, 'D': 0.543862249023773, 'C': 0.2944888920518062},
'D': {'C': 0.5889777841036123, 'A': 0.543862249023773, 'B': 0.2404491734814939},
'C': {'D': 0.5889777841036123, 'A': 0.2944888920518062, 'B': 0.2944888920518062}}
{'a': 2.0614222443626433, 'c': 1.3252000142331277, 'd': 3.092133366543965}2、基于物品的协同过滤(ItemCF)
基于物品的协同过滤算法通过对item的评分来评测item之间的相似性,从而基于item的相似性做推荐。不知道大家平时在网上购物的时候有没有这样的体验,比如你在网上商城下单了一个手机,在订单完成的界面,网页会给你推荐同款手机的手机壳,你此时很可能就会点进去浏览一下,顺便买一个手机壳。其实这就是ItemCF算法在背后默默工作。ItemCF算法给用户推荐那些和他们之前喜欢的物品相似的物品。因为你之前买了手机,ItemCF算法计算出来手机壳与手机之间的相似度较大,所以给你推荐了一个手机壳,这就是它的工作原理。看起来是不是跟UserCF算法很相似是不是?只不过这次不再是计算用户之间的相似度,而是换成了计算物品之间的相似度。
简单来说,就是给用户推荐他之前喜欢物品的相似物品。
由上述描述可以知道ItemCF算法的主要步骤如下:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
ItemCF算法并不是直接根据物品本身的属性来计算相似度,而是通过分析用户的行为来计算物品之间的相似度。
什么意思呢?比如手机和手机壳,除了形状相似之外没有什么其它的相似点,直接计算相似度似乎也无从下手。但是换个角度来考虑这个问题,如果有很多个用户在买了手机的同时,又买了手机壳,那是不是可以认为手机和手机壳比较相似呢?
由此引出物品相似度的计算公式:


上述公式看起来还是很合理的,但是如果物品v很热门,很多人都喜欢,那么上式中分子与分母就会很接近,此时就会很接近1。即任何商品都和热门商品之间的相似度很高,这会导致ItemCF算法会总是推荐热门商品,这并不是一个好的设计。因此可以采用下面的公式:

上式的改进在于,如果N(v)很大的话,分母也会相应变大,相当于惩罚了物品的权值,减轻了热门物品会和很多其他物品相似的可能性。
在建立起了物品的相似度矩阵之后,与UserCF算法一样,我们也要面临一个问题,就是如何从众多相似的物品中挑选出用户最感兴趣的物品。因此ItemCF算法通过以下公式计算用户u对物品j的感兴趣程度:


完整代码和推荐结果
# _*_coding utf-8_*_
# 开发团队: DMU
# 开发人员: $(USER)
# 开发时间: $(DATE)$(TIME)
# 文件名: $(NAME).py
# 开发工具: $(PRODUCT_NAME)
import math
class ItemCF:
def __init__(self):
self.user_score_dict = self.initUserScore()
self.items_sim = self.ItemSimilarityBest()
print(self.items_sim)
def initUserScore(self):
user_score_dict ={
'A':{'a':3.0,'b':4.0,'c':0.0,'d':3.5,'e':0.0},
'B': {'a': 4.0, 'b': 0.0, 'c': 4.5, 'd': 0.0, 'e': 3.5},
'C': {'a': 0.0, 'b': 3.5, 'c': 0.0, 'd': 0.0, 'e': 3.0},
'D': {'a': 0.0, 'b': 4.0, 'c': 0.0, 'd': 3.5, 'e': 3.0}
}
return user_score_dict
def ItemSimilarityBest(self):
itemSim = dict()
item_user_count = dict()
count = dict()
for user,item in self.user_score_dict.items():
for i in item.keys():
item_user_count.setdefault(i,0)
if self.user_score_dict[user][i]>0:
item_user_count[i] += 1
for j in item.keys():
count.setdefault(i,{}).setdefault(j,0)
if(
self.user_score_dict[user][i]>0.0
and self.user_score_dict[user][j]>0.0
and i!=j
):
count[i][j] += 1
for i,related_items in count.items():
itemSim.setdefault(i,dict())
for j,cuv in related_items.items():
itemSim[i].setdefault(j,0)
itemSim[i][j] = cuv/math.sqrt(item_user_count[i]*item_user_count[j])
return itemSim
def ItemSimilarity(self):
itemSim = dict()
item_user_count = dict()
count = dict()
for user,item in self.user_score_dict.items():
for i in item.keys():
item_user_count.setdefault(i,0)
if self.user_score_dict[user][i]>0:
item_user_count[i] += 1
for j in item.keys():
count.setdefault(i,{}).setdefault(j,0)
if(
self.user_score_dict[user][i]>0.0
and self.user_score_dict[user][j]>0.0
and i!=j
):
count[i][j] += 1
for i,related_items in count.items():
itemSim.setdefault(i,dict())
for j,cuv in related_items.items():
itemSim[i].setdefault(j,0)
itemSim[i][j] = cuv/item_user_count[i]
return itemSim
def preUserItemScore(self,userA,item):
score = 0.0
for item1 in self.items_sim[item].keys():
if item1 != item:
score +=(
self.items_sim[item][item1]*self.user_score_dict[userA][item1]
)
return score
def recommend(self,userA):
user_item_score_dict = dict()
for item in self.user_score_dict[userA].keys():
user_item_score_dict[item] = self.preUserItemScore(userA,item)
return user_item_score_dict
if __name__ == "__main__":
ib = ItemCF()
print(ib.recommend("C"))推荐结果:
相似度矩阵:
{'a': {'a': 0.0, 'b': 0.4082482904638631, 'c': 0.7071067811865475, 'd': 0.5, 'e': 0.4082482904638631},
'b': {'a': 0.4082482904638631, 'b': 0.0, 'c': 0.0, 'd': 0.8164965809277261, 'e': 0.6666666666666666},
'c': {'a': 0.7071067811865475, 'b': 0.0, 'c': 0.0, 'd': 0.0, 'e': 0.5773502691896258},
'd': {'a': 0.5, 'b': 0.8164965809277261, 'c': 0.0, 'd': 0.0, 'e': 0.4082482904638631},
'e': {'a': 0.4082482904638631, 'b': 0.6666666666666666, 'c': 0.5773502691896258, 'd': 0.4082482904638631, 'e': 0.0}}
推荐结果:
{'a': 2.65361388801511, 'b': 2.0, 'c': 1.7320508075688776, 'd': 4.08248290463863, 'e': 2.333333333333333}引用:
《推荐系统开发实战》















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









