







李宏毅学习笔记复习总结
文章目录
- 李宏毅学习笔记复习总结
- 1、Regression(回归)和 Classification(分类)
- 2、Deep Learning
- 3、CNN(卷神经网络)
- 4、RNN
- 5、半监督学习和无监督学习
- 6、Explainable ML
- 7、Attack ML models
- 8、PCA和K-Means
- 9、Manifold Learning(流形学习)
- 10、Deep Auto-encoder
- 11、ELMO,BERT,GPT
- 12、Anomaly Detection(异常侦测)
- 13、Conditional Generation by GAN
- 14、Transfer Learning
- 15、Life Long Learning(终生学习)
- 16、Deep Reinforcemen Learning(深度强化学习)
1、Regression(回归)和 Classification(分类)
1.1 是什么
回归问题通常是预测一个值,预测的结果是连续的,例如预测房价,股票等,分类问题是预测事物的所属标签,预测结果是离散的,例如预测宝可梦的类别,股票的涨停等。分类模型通常可以在回归模型上建立,分类模型的最后一层通常用Softmax函数判断其所属类别。
1.2 怎么做
回归模型和分类模型都可用下图所示的神经网络。回归模型通常情况下Output layer的n=1。分类模型按照所分的类别的数量来决定Output layer中n的取值,F通常是Softmax函数。

Hiddle laters的激活函数可根据实际问题来选择。常用的激活函数有:
- sigmod函数

- ReLU函数
F(x) = max(0,x)

- ELU函数

- PReLU函数
F(x) = max(ax, x)

- MAXOUT函数
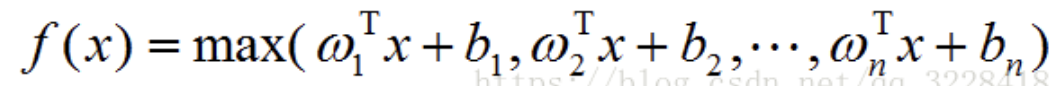
- softmax函数
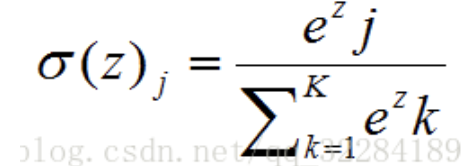
2、Deep Learning
2.1 是什么
Deep Learning是通过提高神经网络模型的深度(中间层的层数)以提高模型学习能力的方法。
2.2 怎么做
因为有Hidden layers有很多层,所以模型参数很多,学习能力强,所以在对模型进行优化时,需要用前向传播和反向传播求出每层参数的导数,再用梯度下降的方法对参数进行优化。简单来说,就是用优化方法对模型进行暴力优化。

3、CNN(卷神经网络)
3.1 是什么
CNN是对图像进行重点信息提取从而实现降维的神经网络。
3.2 怎么做
用一组参数作为Filter,对图片数据进行内积(对应位置相乘求和),得到降维后的数据,这层叫做卷积层。

对卷积层得到的数据每2*2作为一组,取每组的最大值或者平均值作为新的数据,这层叫做池化层。

经过多次卷积池化,对图片数据进行降维,最好得到的数据拉直就可送入合适的神经网络进行训练了。所以说CNN做的事情是将图片进行降维。
4、RNN
4.1 是什么
RNN是具有记忆功能的神经网络,适合处理需要根据上下文语境得出答案的问题。例如,智能对话,总结文章等。下图是最简单的RNN。

4.2 怎么做
最常用的RNN是LSTM,如下图所示:
 LSTM有4个输入,只有一个输出,Z口负责输入数据,Zi口会判断此时是否允许输入,Zf口负责记忆功能,Zo口负责控制输出。将多个LSTM连接起来,就可组成有Deep的RNN,可以很好的解决智能对话,总结文章这类的问题。
LSTM有4个输入,只有一个输出,Z口负责输入数据,Zi口会判断此时是否允许输入,Zf口负责记忆功能,Zo口负责控制输出。将多个LSTM连接起来,就可组成有Deep的RNN,可以很好的解决智能对话,总结文章这类的问题。

5、半监督学习和无监督学习
5.1 是什么
半监督学习:是指训练资料有一部分是有labels的有一部分是无labels,且通常情况下无labels data数据量远大于有labels data。
无监督学习:是指训练资料都是无label的。
5.2 怎么做
- 半监督学习比较经典的一个方法是Self-training,它的做法是:
- 用labeled data训练出一个好的模型 f。
- 再将模型f运用到unlabeled data中,得到unlabeled data的label。
- 根据第二步得到的label,将一些合适的unlabeled data及对应的label移入labeled data,再重复上面步骤。
还有Semi-supervised Learning for Generative Model、semi-supervised SVM等方法。
- 无监督学习比较常用的方法是Word Embedding-Prediction based,它是把一句话中的一个或多个word的vector作为Input,把这些word的下一个词作为label,如此反复迭代,完成训练。
6、Explainable ML
6.1 是什么
Explainable ML是解释机器行为的方法,也就是知道机器为什么做某个行为。例如机器在做影像识别时,我们可以用Explainable ML的方法去知道机器是通过该image的哪个特征做出正确判断的。
6.2 怎么做
Explainable ML主要分类两类,分别是Local Explanation和Global Explanation。
- Local Explanation的基本思想是改变输入(遮挡法,Gradient法),观察输出的变化程度,来判断什么是重要的。
- Global Explanation的基本思想是用一个容易解释的model去模仿不能解释的model的局部或者全部行为(通常是局部行为),然后用容易解释的model解释该行为。
7、Attack ML models
7.1 是什么
Attack ML models是对机器学习的model进行攻击。对机器学习的模型进行攻击是训练一个输入x,使得机器看见该x后就会做出错误的行为或者我们向让其做的行为。
7.2 怎么做
和训练机器学习的model差不多,这里也是用gradient的方法来求解,不过Attack时,是将输入x作为train的对象,对x做微小的改变△x,在训练时要求△x越小越好,输出结果离正常结果越远越好。学习Attack ML models的主要目的是让我们掌握常见的攻击手法,从而在训练机器学习的model时,刻意的去规避自己的model被攻击,提高model的稳定性。
8、PCA和K-Means
8.1 是什么
K-Means是聚类算法,属于无监督学习,是对数据进行分类的算法。PCA(主成分分析)是对高纬度空间中线性分布的数据进行降维的算法,实际应用很广泛。
8.2 怎么做
- K-means是将Unlabeled datas随机取K个中心点,按照它们与每个中心点的距离分为K个类别,再求K个类别中数据的均值点,再将均值点作为中心点重新进行分类,直至中心点不再移动。
- PCA它的想法是将N维数据特征映射到K维上,它的工作是从原始的空间中找K组坐标轴,第一个新的坐标轴选择的是原始数据中方差最大的方向,第二个坐标轴的选择是与第一个坐标轴相交的平面中方差最大的方向,第三个坐标轴的选择是与第一,二个坐标轴相交的平面中方差最大的方向,以此类推。实际上,通过计算数据矩阵的协方差矩阵,得到协方差矩阵的特征向量,选择特征值最大的K个特征所对应的特征向量组成的矩阵,就是降维后的K维空间的数据。
9、Manifold Learning(流形学习)
9.1 是什么
Manifold Learning是对高维空间中非线性分布的数据进行降维的方法。
9.2 怎么做
常用的做法有LLE、LE、T-SNE。
- LLE: 利用data point之间的联系进行降维。选定每个点和其周围点,用周围的点加权求和表示该点,这些权重就是联系,保持权重(联系)不变的情况下将全部的高维空间data point投映到低维空间。
- Laplacian Eigenmaps(LE):将data point构建成图进行降维。将每一个点与其周围的K个点连接起来构建成图,然后定义其每个点之间权重wij的值,构建拉普拉斯矩阵,通过计算其特征向量得到其降维后的点。
- T-SNE:利用data point各个点之间的相似度进行降维。计算data point各个点之间的相似度P以及降维后的点的相似度Q,我们希望P和Q越接近越好,所以用衡量distribution相似度的函数KL得到Loss Function,对该Function用梯度下降法就可得到降维后的点。
10、Deep Auto-encoder
10.1 是什么
Deep Auto-encoder是对数据进行降维变成一个低维度的Vector且可以较完整的保留原始数据信息的技术。
10.2 怎么做
在对图片进行降维时,先将图片进行升维放到细节,在对其进行降维变成一个code,再按原本降维的步骤反着来对图片进行还原,还原度越高越好。

11、ELMO,BERT,GPT
11.1 是什么
ELMO,BERT,GPT是用来解决编码时,“一词多译”的问题,对同一个词进行多个编码的方法。
11.2 怎么做
- ELMO的做法是training一个正向的RNN和反向的RNN,两者组合作为word的Embedding,这样word Embedding不仅考虑了前文语境思,也考虑了后文语境,且不同语境得到的word也都是不同的。
- BERT是Transformer的Encoder,它常用的训练方法有两个,一个是将句子中的某些word用标志符[mask]代替,让machine去猜被代替的词是什么,如此就可以找到每个word的Embedding。另一个是输入分类标志符和句子间的分隔标志符,然后输入句子是否是可以连在一块的,让machine知道句子间的联系及含义。
- GPT是Transformer的Dncoder,它是将每一个word分为3个vector,每一层的输出作为下一次的输入,将联系一层一层传递下去,然后training出所有word的vectors。
12、Anomaly Detection(异常侦测)
12.1 是什么
Anomaly Detection是让机器识别异常的输入数据的方法。
12.2 怎么做
- Binary Classification:它是有监督的Anomaly Detection,是将正常资料分为一类,异常资料分为一类,然后训练一个分类器,以此实现Anomaly Detection。
- With Classifier:它是有监督的Anomaly Detection,是在Classifier的基础上,引入Confidence score,让机器知道自己答案的可信度,设置Confidence score阈值,从而实现异常检测。
- Gaussian Distribution:它的异常侦测是无监督的Anomaly Detection,和With Classifier的方法相似,不同点在于它是在Gaussian Distribution的分类器上引入Confidence score。
- Auto-encoder:它是无监督的Anomaly Detection,它的想法是用Encoder-Decoder 模型将Training data中的重要特征抓住,并以此来对数据进行降维,当异常数据输入时,model还会以同样的方法对数据进行降维,但如此降维后的数据将无法很好的还原出来,当还原度低于一定阈值时,machine就会知道该数据是异常的。
13、Conditional Generation by GAN
13.1 是什么
GAN是用来根据现有数据生成和原始数据不一样但又相似的数据的神经网络。GAN内主要包括Generator(G)和Discriminator(D)。Conditional Generation by GAN是让机器根据人们的要求去生成数据。例如根据现实人物生成动漫人物。
13.2 怎么做
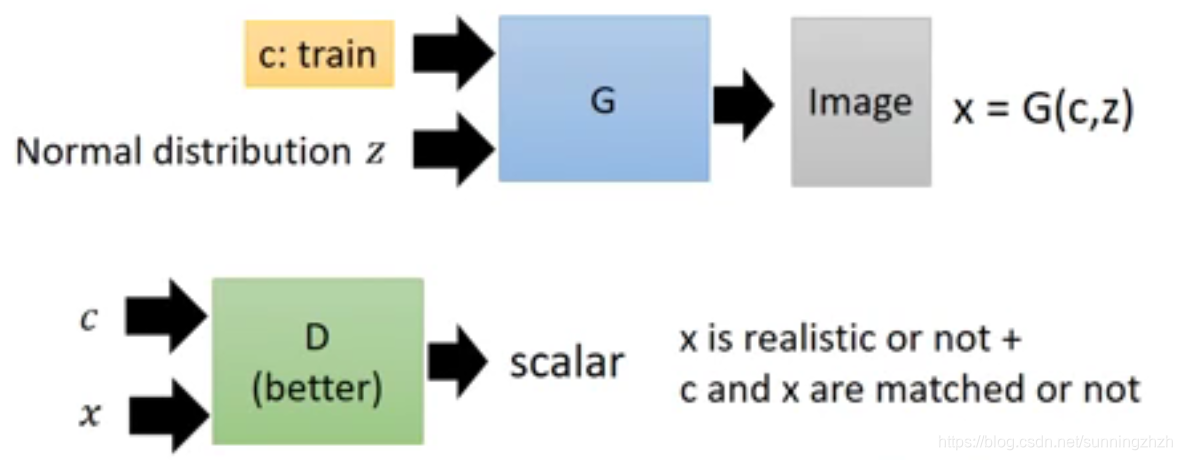
-
Supervised Conditional GAN用的方法是将train data和noise同时丢给G,G会生成图片,将G生成的图片及期望该图片对应的文字的encode组合起来丢给D,D在打分时,只有当G生成的图片像真的且文字和G对应的图片是匹配的时候才给高分。
-
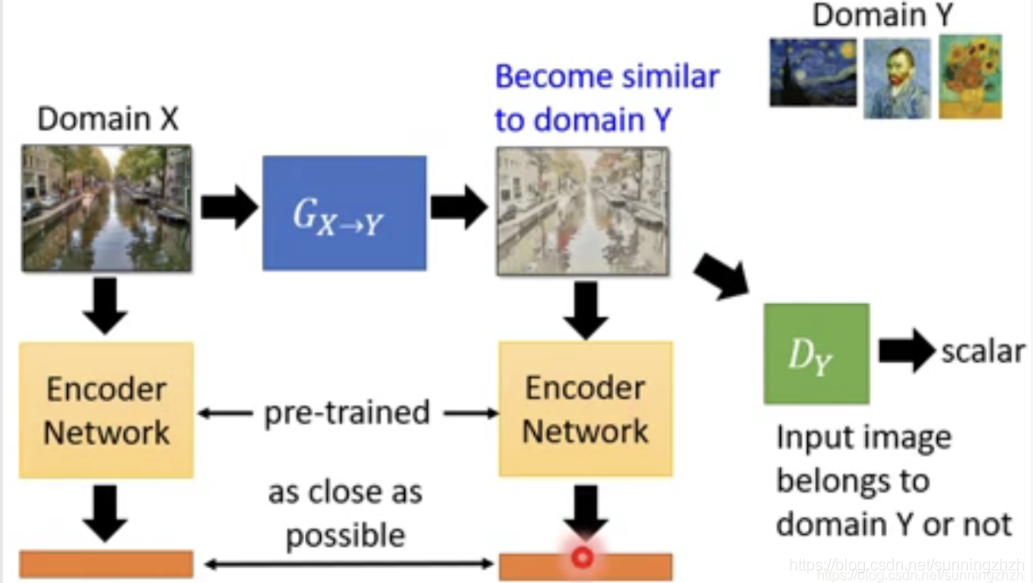
Unsupervised Conditional GAN的方法有很多,它主要分为两类,一类是将输入从一个Domain转移到目标Domain,以真实照片二次元化为例,它的方法主要分为两步,一步是将Domain X和Domain Y通过Pre-trained将两者转换为vector,训练的时候让其越接近越好以保持生成的图片保留了Domain X的信息,一步是将Domain Y丢给D,D以Domain Y是否二次元给Domain Y评分以确保产生的图片是二次元的。
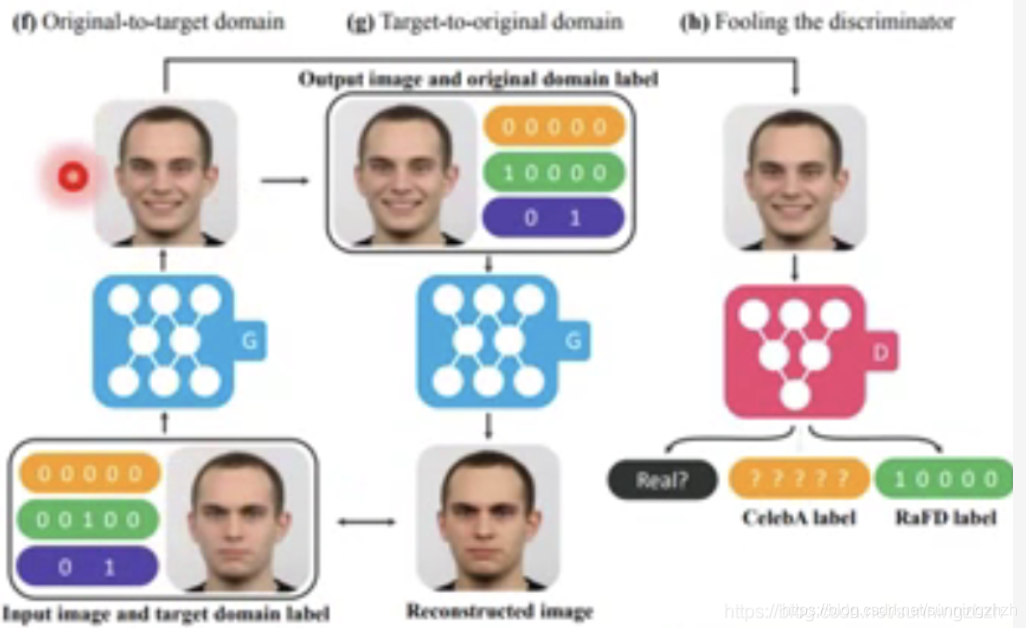
另一类是改变输入的某些特征。它的一个重要的方法叫StarGAN,以将人从愤 怒表情转换为微信为例,它的做法和上述方法类似,分为两步,一步将G生成的微信的图片再经过G还原成愤怒的图片,在训练时希望还原的图片与真实图片越接近越好,以此确保生成的图片保留了输入图片完整的信息,一步是将生成的图片丢给D,D根据图片的真实度及是否是目标Domain(这里是微笑表情)打分。
14、Transfer Learning
14.1 是什么
Transfer Learning是用与训练数据相似的数据和训练数据一起对模型进行训练的算法。以达到让机器利用类似数据进行联系学习的效果。
14.2 怎么做
- Source 和Target data都是有label时:进行训练的方法主要用的是Model Fine-tuning和Multitask Learning。前者是用Source data对model进行训练,得到的model作为model初始化参数,再用Target data对model进行训练,再训练时,要求model与初始化参数越接近越好,以防止over fit。后者是用model共用一些layer同时去训练source data和target data,前提就是source data和target data要有相似之处。
- Target data无label Source data有label时:进行训练的方法主要有Domain-adversarial training和Zero-shot Learning。前者是设计一些神经网络作为特征消除器,将Target data的一些多余特征消除,使其与Source data特征接近,来实现Transfer Learning。后者是训练一个属性提取的model,大量的Source data负责教会model提取特征,再从Target data中提取特征和数据库做对比或者投映到高维空间中,以此找到对应的label。
15、Life Long Learning(终生学习)
15.1 是什么
Life Long Learning是让机器可以和人一样,用同一个”脑子“做很多事情,且每件事都可以做好。具体细节上,Life-long Learning是希望机器做到在学习新知识时不能忘记旧知识,且学习的时候要像人一样,能够触类旁通,当学习任务比较复杂时,知道自动调用更多的神经元进行学习。
15.2 怎么做
Life-long Learning主要面临着以下3个方面的问题:
- Knowledge Retention:要求机器在学习的过程中既要学好又不能遗忘曾经学过的知识。
- Knowledge Transfer:希望模型可以用已经学过的知识帮助其学习新的知识,达到触类旁通的效果。
- Model Expansion:希望模型可以根据问题的复杂度来调整模型自己的复杂度,以此提高准确率及内存空间的利用效率。
Life-long Learning的方法有很多,有3个比较常用的方法对应着解决以上三个问题。
- EWC用的是调整损失函数来控制模型在学习新知识时不遗忘旧知识的方法,是用来解决Knowledge Retention的问题的。
- GEM是记住以前任务的一部分训练数据,在训练新任务更新参数时,不仅考虑该参数的导数,还考虑在以往的任务上该参数的导数,使得模型在学习新任务时,还会回顾旧任务,实现触类旁通,是用来解决Knowledge Transfer的问题的。
- Net2Net是将模型中一部分神经元一分为二或者分为多个,保持其输入参数不变,输出则由母体神经元和子体神经元平分,来实现自动扩展时不会忘记曾经学过的知识,它是用来解决Model Expansion的问题的。
16、Deep Reinforcemen Learning(深度强化学习)
16.1 是什么
它是一种更接近人类思维的人工智能的方法,是通过奖励机制来进行训练的模型,它可以让机器学会跳舞,下围棋等极具人类思维的行为。
16.2 怎么做
实现强化学习的方法有很多,以下三种是比较常用的:
-
Reinforcement Learning是通过奖励机制进行训练的,其中Actor负责接收Env中的信息做出行动,Critic负责给Actor打分从而得到Loss Function,用其更新Actor的参数,让Actor的行为越来越正确。

-
Imitation Learning中没有Critic,它是纯粹的从Env中接收信息,Actor做出判断反馈到Env中,循环往复,但是在training时,会给其一些老师做的示例,让其与示例越接近越好,以此达到训练的目的。

-
Inverse Reinforcement Learning是从老师做的示例中学习,找到一个合适的Reward Function,再和Reinforcement Learning一样进行训练。















 4955
4955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









