




 本文详细介绍了Convolutional Pose Machines的工作原理,它是一种序列预测框架,利用深度卷积网络学习图像特征和空间上下文,解决关节定位问题。论文通过端到端训练避免梯度消失,并在各个阶段对网络进行局部监督,提升预测准确性。
本文详细介绍了Convolutional Pose Machines的工作原理,它是一种序列预测框架,利用深度卷积网络学习图像特征和空间上下文,解决关节定位问题。论文通过端到端训练避免梯度消失,并在各个阶段对网络进行局部监督,提升预测准确性。
1. 网络结构
这篇论文是著名的openpose的前身。openpose的关节点 confidence maps就是用了这篇论文的思想。跟这篇论文展示的是不是很像呢。

论文采用了卷积神经网络对输入的图像特征信息进行卷积计算,在stage1(第一阶段)得出特征点位置的置信图用于判断该特征点为目标关节的可能性的小。经过stage1的初始预测之后,进入到重复的stage(2~T),在接下来的stage循环中,需要接收图像特征和上一阶段产生的置信图的空间内容信息从而不断优化预测结果。
文章的网络结构如下:
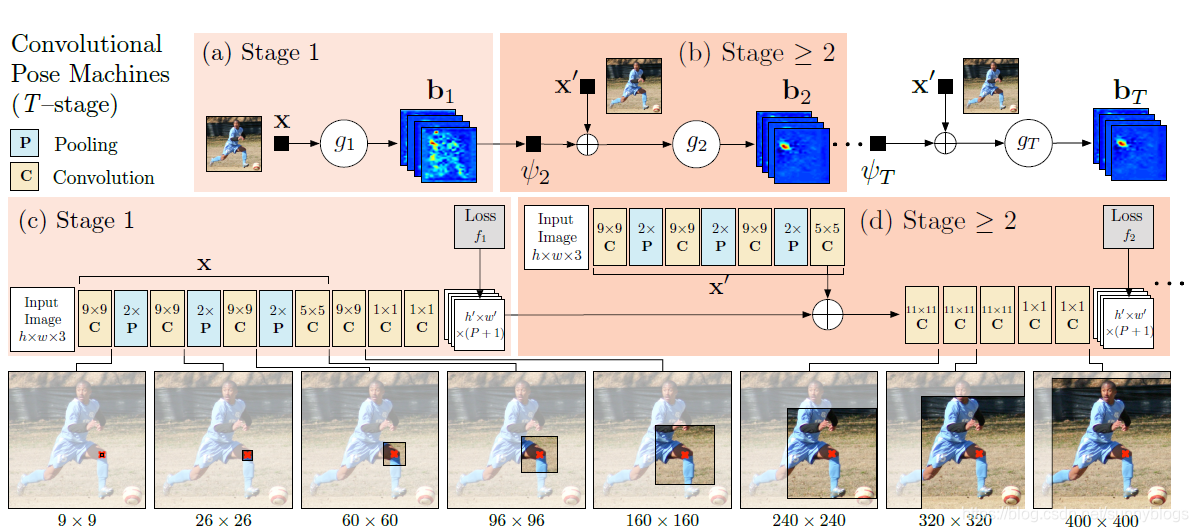
图(a)和(b)所示是姿态机(pose machine )的工作原理,相应的卷积网络如图(c)和(d)所示。
图(a)和(c)展示了在第一阶段(stage 1)只对图像特征进行操作的结构。图(b)和(d)显示了后续stage(2~T)的结构,这两个stage同时对图像features和前一阶段的belief map(信念图)进行操作。(b)和(d)中的架构在所有后续阶段(2到T)中重复。在每个阶段之后,使用中间损耗层对网络进行局部监督,以防止在训练期间梯度消失。在下面的插图(e)中,我们展示了建筑图像(以左膝为中心)上的有效感受野,其中大的感受野使模型能够捕捉到长距离的空间依赖关系,例如头部和膝盖之间的空间依赖关系。
咱们先不看具体的卷积参数,先把主干网络扒出来:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









