







Global Locality in Biomedical Relation and Event Extraction
论文
Abstract
随着生物医学文献的迅猛发展,事件和关系的抽取成为生物医学文本挖掘中的重要任务。大多数工作只关注关系抽取,并检测在短文本中提及的单个实体对,这是不理想的,因为长句子出现在生物医学语境中。我们提出了一种关系抽取和事件抽取的方法,用于同时预测文本中所有提及对之间的关系。为此我们也进行了实证研究来讨论不同的网络设置。性能比较好的模型是由一组多注意力和卷积构成,它是对transformer架构的一种适应,它提供了self-attention的能力,以加强相关元素之间的依赖性,并对多个注意力头提取的特征之间的交互建模。实验结果表明,我们的方法在一组基准生物医学语料库(包括BioNLP 2009、2011、2013和BioCreative 2017共享任务)上的性能优于最新水平。
Introduction
事件和关系抽取在生物医学领域被用于从科学文献和患者记录等海量文档集中提取信息。这些信息包含蛋白质、药物-药物、化学-疾病等命名实体之间的相互作用,以及更复杂的事件。
关系通常被描述为定义的命名实体之间的类型化的、有时是定向的、成对的链接。事件抽取与关系抽取的不同之处在于,事件具有带标注的触发词(例如:动词),并且是可以连接两个以上实体的其他事件的参数。与关系抽取相比,事件抽取更加复杂,因为其更倾向于捕捉文本的语义。
下图是一个来自Ge11共享任务语料库的示例,其中包括两个嵌套事件。

近年来,深度神经网络模型在事件和关系抽取方面获得了最先进的性能。两种主要的神经网络结构包括卷积神经网络(CNNS)和递归神经网络(RNNs)。CNN能够捕捉基于卷积运算的局部特征,更适合处理短句子序列,但RNN擅长学习长期依存特征,更适合处理长句子。因此,结合两种模型的优点是提高生物医学事件和关系抽取性能的关键。然而,在RNN中,结合上下文对长序列编码由于依赖序列的长度计算量非常大,而且计算不能并行化,因为每个token的表示需要前一个token的表示作为输入。相反,CNN可以再整个序列中并行执行,且性能良好,但在单个token表示的上下文的数量收到网络深度的限制,并且非常深的网络很难学习。
为了解决上述问题,产生了self-attention,不仅计算可以高度并行化,而且具有通过显示地关注所有元素来不分距离地对依赖项进行建模的灵活性,除此之外,它的性能还可以通过多头注意力来提高,多头注意将输入投影到多个子空间,并将注意力应用于每个子空间的表示。
本文提出了一种新的神经网络模型,该模型将多头注意机制与一组卷积相结合,在生物医学事件和关系抽取中提供全局、局部性。卷积捕捉文本的局部结构,而自我注意则学习每对单词之间的全局互动。因此,我们的方法对self-attention的局部性进行建模,而特征之间的交互是通过多头注意来学习的。在生物医学基准语料库上的实验结果表明,提供全球局部性比现有的生物医学事件和关系提取技术要好。模型的体系结构如下图所示。

Data
我们在一些事件和关系抽取语料库上开发并评估了我们的方法。这些语料库来自BioNLP 2009、2011和2013以及BioCreative 2017关系抽取任务。BioNLP语料库涵盖了分子生物学的各个领域,并提供了最复杂的事件标注(由于没有提供BioNLP共享任务语料库的测试集的标注,我们将测试集上传到任务组织者的服务器进行评估。)。BioCreative语料库使用成对关系标注。下表显示了有关这些语料库的信息,关于与生物医学共享任务的语料库相关的域、事件和实体类型的数量(E)、事件参数和关系类型的数量(I)、以及句子的数量(S)的信息。

为了进一步的分析和实验,我们还使用了AMIA基因突变语料库。训练/测试集包含2656/385个突变,2799/280个基因或蛋白质,1617/130个基因与突变之间的关系。我们提取了约30%的训练集作为验证集。
Model
我们提出了一种新的生物医学事件提取模型,该模型主要建立在多头注意力的基础上,学习每对token之间的全局交互,并通过卷积来提供局部性。提出的神经网络结构由4个并行的多头关注点和一组窗口大小为1、3、5和7的一维卷积组成(我们为每个任务/数据集选择不同的embedding,以符合TES)。我们的模型关注了输入特征中最重要的标志,并增强了多个头上相关元素的特征提取,而不考虑它们之间的距离。此外,我们通过卷积将参与的token限制在局部区域,从而为多头注意的局部性建模。
关系和事件提取任务被建模为事件和关系的图形表示如下(Bj¨ orne and Salakoski, 2018)。




实体和事件触发器是节点,关系和事件参数是连接它们的边。事件被建模为触发器节点及其传出边集合。
关系和事件抽取通过以下分类任务来执行:
(1)实体和触发器检测,这是命名实体识别任务,其中检测句子跨度中的实体和事件触发器以生成图节点;
(2)关系和事件检测,其中预测所有有效的实体和触发器节点对的关系和事件参数以创建图的边;
(3)事件重复,其中每个事件被分类为事件或否定,其导致图中的解合(由于事件是n元关系,因此事件节点可能会重叠。);
(4)修饰语检测,其中事件模态(推测或否定)是。
在给定实体的关系抽取任务中,仅部分使用第二分类任务。所有四个分类任务都使用相同的网络体系结构,不同任务之间的预测标签数量不同。
Input
输入在以目标实体、关系或事件为中心的句子窗口的上下文中建模。句子被建模为单词token的线性序列。在中的工作之后,我们使用一组embedding向量作为输入特征,其中每个唯一的单词token被映射到相关的embedding向量空间。我们使用预先训练的200维Word2vec向量,这些向量是在英文维基百科和数百万篇来自PubMed和PubMed Central的生物医学研究文章的组合上归纳出来的,以及从输入语料库中学习的相对位置和距离的8维embedding。我们使用距离特征,其中到关注token的相对距离被映射到它们自己的向量。我们还考虑了相对位置特征来识别标记在分类结构中的位置和作用。最后,将这些embedding与它们的学习权重连接在一起,以形成每个单词token的n维向量ei。然后,该合并的输入序列由一组并行的多头关注处理,随后是卷积层。
Multi-head Attention
self-attention网络通过对输入序列中的每一对token应用注意力来产生表示,而不考虑它们的距离。根据之前的研究,多头注意使用单独的归一化参数(attention heads)对相同的输入应用多次self-attention,并合并结果,作为使用多个参数的一次注意的替代。这个建模决策背后的直觉是,将注意力分成多个头部使模型更容易学会用每个头部处理不同类型的相关信息。
self-attention通过对序列中的所有token执行加权求和来更新输入embedding ei,加权是通过它们对建模token i的重要性来进行的(唯一的例外是单词向量,其中原始权重用于为任务训练语料库之外的单词提供泛化。)。给定输入序列E = {e1,…,eI}∈ R(I×d),该模型首先将每个输入投影到key k、value v和query q,使用带有ReLU激活的独立仿射transform,这里k,v,q各在R d H中,其中d表示隐藏层大小,H表示head数。标记i和j之间的头部h的注意力权重ahij是使用缩放的点积注意力来计算的:

其中ohi是注意力头的输出,⊙表示元素乘法,σ表示第j维度的softmax值,缩放的注意力是为了通过扁平化Softmax和更好地分布梯度来帮助优化。每个注意头的输出被连接成oi,表示如下:
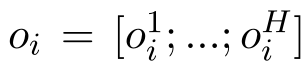
在这里,所有层都使用了多头注意的输出和输入之间的残差连接。然后将层归一化LN(.)应用到输出:mi= LN(ei+oi)。multi-head attention layer使用softmax激活函数。
Convolutions
多头注意之后是一组并行的一维卷积,窗口大小分别为1、3、5和7。添加这些显式n-gram建模有助于模型学习注意局部特征。我们的卷积使用RELU激活函数。我们使用C(.)表示卷积运算符。该模型的卷积部分由下式给出:
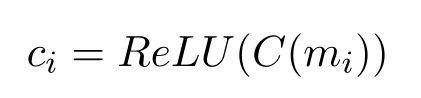
然后将全局最大池化应用于每个1D卷积,并将所得到的特征合并到输出向量中。
Classification
最后,输出层进行分类,每个标签用一个神经元表示。分类层使用Sigmoid激活函数。分类作为多标签分类来执行,其中每个示例可以具有零个、一个或多个正标签。我们使用具有二进制交叉熵和学习率为0.001的Adam优化器。在合并输入特征和全局max pooling两个步骤中还应用了Dropout为0.1进行泛化。
Experiments and Results
我们已经在基准生物医学语料库上进行了一系列实验来评估我们提出的方法。除了评估我们的主要模型(4MHA-4CNN)外,我们还评估了我们提出的方法的三个变体的性能:
(1)4MHA:4个并行多头注意对输入特征进行多次self-attention;
(2)1MHA:只有1个多头注意对输入特征应用self-attention;
(3)4CNN-4MHA:通过一组一维卷积将多个self-attention应用于输入特征。4CNN架构与TEE使用的最佳性能配置(4CNN-MIXED 5 X ensemble)相匹配,该配置由四个一维卷积组成,窗口大小分别为1、3、5和7。
在我们的模型和TEES中,我们将卷积的滤波器数量设置为64。多头注意力的头数也被设置为8个。TEES的报告结果是通过对不同任务运行out-of-the-box system来实现的。
如果验证集太小,训练单个模型可能容易过拟合,因此我们使用混合5个模型集成,该集成采用5个最佳模型(20个),在随机划分的训练/验证集上使用micro-averaged F-score 进行排序,并考虑它们的平均预测。这些集成整体预测是为每个标签计算的,作为所有模型的预测置信度得分的平均值。我们的模型(4MHA-4CNN)在不同的共享任务:BioNLP(GE09,Ge11,EPI11,ID11,REL11,GE13,CG13,PC13),BioCreative(CP17),以及AMIA数据集,获得了比性能最好的系统(TEES)更最先进的结果。
通过对结果进行分析,我们发现除了EPI11,ID11和CG13之外,我们的模型4MHA-4CNN在大多数数据集的F值和召回率都是最好的(例如:1MHA-4CNN)。
在精度方面,对合并的输入特征应用4CNN和4MHA的优势取决于数据集。在PC13上,在合并的输入特征上使用4CNN的精度比其他配置要高得多,但召回率却明显较低。
除了EPI11、ID11和CG13之外,提出的4MHA-4CNN模型也有很好的召回率,其中4MHA更好。如前所述,在多头攻击之后添加卷积在这三个数据集中可能用处较小,因为这些主题中的句子描述了存在长上下文依赖关系的交互。
总的来说,我们的观察支持这样一种假设:在4MHA首先应用于合并输入特征的配置中,可以获得更高的召回率/F-score,而在处理长依赖性时,cnn不像MHAs那样方便。
在我们的模型中,通过各种共享任务的语料库得到Precision,Recall和F-score。每个任务的最佳分数分别用粗体和高亮显示。所有的结果(CP17和AMIA除外)都使用每个任务的官方评估程序/服务器进行评估。结果如下图所示:


Discussion
除了改善以前的技术水平外,研究结果还表明,与单独的组件相比,将多头注意与卷积相结合提供了有效的性能。在我们模型的变体中,4MHA在结果中显示地所有共享任务上也优于TEE。尽管卷积本身相当有效,但多头注意提高了它们的性能,能够处理更长的依赖关系。

上图显示了“关系和事件检测”分类任务在不同的网络结构(4MHA-4CNN、1MHA和4MHA)下对一个例句“The presence of activating TSH-R mutations has also been demonstrated in differentiated thyroid carcinomas.”的多头注意力(所有的注意力总和)。在4MHA和4MHA-4CNN模型中,四个多头注意层对注意的贡献各不相同。这使得4MHA和4MHA-4CNN模型能够独立地利用比1MHA模型更多的token之间的关系。此外,卷积使得4MHA-4CNN模型比4MHA模型更关注某些重要的token。
考虑到计算复杂性,根据之前的研究成果,self-attention的成本是序列的长度的平方,而卷积成本是数据表示维度的平方。与单个句子的长度相比,数据的表示维度通常更高。在计算复杂度和F分数方面,多头注意机制更适合这种机制。虽然在多头之后增加卷积使得模型更昂贵,但滤波器的较低表示维度降低了成本。
Error Analysis
我们在基线系统(TEES)上进行了误差分析,并在AMIA和CP17数据集上采用了我们的方法,并观察到了以下误差来源。

Relations involving multiple entities(a):
涉及多个实体的关系是TEES误判的一个主要来源,而我们的方法性能更好,并实现了完全Recall。这可能是因为多头注意能够在不同的位置共同注意来自不同代表子空间的信息。在AMIA数据集的一个示例(a)中,“mutations”与“MLH1”、“MSH2”和“MSH6”这三个基因蛋白质实体之间存在“has mutations”关系。虽然最新的方法只发现“mutations”与第一个基因-蛋白质(MLH1)之间的关系,而忽略了其他两个关系,但我们的方法捕获了突变与所有三个实体(MLH1、MSH2,and MSH6)之间的关系。
Long-distance dependencies(b):
TEES似乎也很难标注远距离关系,例如(b)在AMIA数据集的一个例子中“deletions”和“TGF-β”之间缺失关系,但我们的方法捕获了这一关系。我们进一步探讨了这个问题,绘制了不同建议结构的性能和不同距离TEES的性能图。我们依赖于CP17数据集,因为测试集比AMIA大得多。我们对所提出的最佳性能网络架构(4MHA-4CNN)以及作为单独组件的4MHA和4CNN架构进行了分析,以研究这些架构在捕捉远距离关系时的表现。通过使用TEES预处理工具进行的标记,我们将关系中涉及的最远实体之间的标记数作为距离度量。

上图提供了结果。不管使用何种评估指标,我们观察到分数在较远距离时会下降,并且4MHA性能优于其他两种架构,这取决于多头注意力捕捉远距离依赖关系的能力。这个实验展示了4MHA是如何在4MHA-4CNN中提供全局性的,它在较远距离上的性能略优于4CNN。
Negative or speculative contexts(c):
TEES对于推测性或负面语言的标注有问题,但我们的系统可以解决这一问题。例如(c)TEES在负面提示“inactivating”情况下错误地捕捉到了“mutation”和“SMAD2”之间的关系。即使我们的方法在短距离内正确地忽略了这种假阳性,它仍然捕捉到推测的的长期依赖,这激发了我们未来工作的自然扩展。
Conclusion
我们提出了一种基于多头注意力和卷积的新型结构,以解决生物医学文献中典型的长依赖性问题。结果表明,该体系结构优于现有的生物医学信息提取语料库。虽然多头注意力在抽取关系和事件时识别出长期依赖关系,但卷积提供了捕捉更多局部关系的额外好处,这提高了现有方法的性能。CNN-MHA的性能优于MHA-CNN。
正在进行的工作包括将这一发现推广到其他非生物医学信息提取任务。目前的工作重点是从单个短句/长句中提取事件和关系;我们想要试验额外的内容,以研究这些模型跨越句子边界的行为。最后,我们打算将我们的方法扩展到处理推测语境,考虑更多的语义语言学特征,例如生物医学文献上的意义嵌入。

















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











