







A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
论文
Abstract
从非结构化文本中提取关系三元组是构建大规模知识图的关键。然而,在解决同一句子中的多个关系三元组共享相同实体的重叠三元组问题方面,已有的研究成果寥寥无几。
针对这项工作,本文引入了一个新的视角来重新审视关系三元组抽取任务,并提出了一个新的级联二分标注框架(CASREL),该框架源于一个原则性的问题描述。
新框架不像以前的工作那样将关系视为离散的标签,而是将关系建模为将句子中的主语映射到宾语的函数,这自然地处理了重叠问题。
实验表明,若其编码器模块使用随机初始化的BERT编码器,CASREL框架的性能也已经超过了最先进的方法,显示了新标记框架的强大功能。当采用预先训练的BERT编码器时,它的性能进一步提高,在两个公共数据集NYT和WebNLG上的F1值分别比最强的baseline高出17.5%和30.2%。
对重叠三元组的不同场景的深入分析表明,该方法在所有这些场景中的性能得到了一致性的提升。
Introduction
信息抽取是构建大规模知识图谱的必备关键,先来说一下图谱的三元组形式,在以往常常将三元组以 (head,relation, tail) 的形式表示,在这里以(subject, relation, object)的形式表示,即(S, R,O)。
关系三元组提取最早采用pipeline方法,它首先识别句子中所有实体,再对每个实体对进行关系分类,但会受到错误传播的影响,因早期阶段的错误不能在后期校正。为了解决此问题提出了联合学习,包括基于特征的模型和基于神经网络的模型,后者取得了相当的的成功。
大多数现有方法不能有效解决句子中包含相互重叠的多个关系三元组。
重叠的三元组问题直接挑战了传统假设每个token只带有一个标签的序列标注方案。这也给关系分类方法带来了很大的困难,2016年Miwa等人提出的在方法中,一个实体对被假定至多持有一个关系。2018年Zeng等人是最早考虑关系三元组抽取中重叠三元组问题,他们引入了不同重叠模式的类别(如图所示正常(normal)、两个实体重叠(EPO)、单个实体重叠(SEO)的示例),并提出了一个具有复制机制的序列到序列(Seq2Seq)模型来提取三元组。

2019年Zeng等人,基于Seq2Seq模型进一步研究了提取顺序的影响,并通过强化学习获得了相当大的改进。2019Fu等人还研究了重叠三元组问题,通过使用基于图卷积网络(GCNS)的模型将文本建模为关系图。
虽然取得了成功,但还存在不足。他们都将关系视为要分配给实体对的离散标签。这种形式使得关系分类成为一个困难的机器学习问题。①阶级分布高度不平衡。在所有提取的实体对中,大多数没有形成有效的关系,从而产生了过多的反例。②当同一实体参与多个有效关系(重叠的三元组)时,分类器可能会被混淆。在没有足够的训练实例的情况下,分类器很难分辨出实体参与的是哪种关系。因此,提取的三元组通常是不完整和不准确的。
本文从关系三元组的原则性公式开始提出一个通用的算法框架,核心是将关系建模为将Subject映射到Object的函数,更准确的说,学习的不是关系分类器f(s,o)→r,而是特定于关系的标记器fr(s)→o,识别每个给定特定关系下给定Subject的可能object,若不返回object表示给定关系和subject没有三元组。
本文主要贡献:①从新视角提出了一个解决重叠三元组问题的通用算法框架。②将上述框架实例化为基于Transformer编码器的级联二分类标注框架,使得模型可以将框架的功能和预训练语言模型的先验知识相结合。③实验表明效果远优于当前模型。
The CASREL Framework
以前的工作都是单独定义关系和实体,而没有在三元组层面上建模。形式上,给定来自训练集D的已标注句子xj和xj中可能存在的重叠三元组Tj={(s,r,o)},目标是最大化训练集D的数据可能性(如下图公式所示):
其中,s∈Tj表示Tj中由s引导的三元组的集合;(r,o)∈Tj|s表示由Tj中s引导的三元组中的(r,o)对;R是所有可能关系的集合;R\Tj|s表示除Tj中除了s引导的关系之外的所有关系;O∅表示“null”object。公式(2)应用了概率链式法则,公式(3)利用了一个事实,所有与s相关的关系必然有o,其他关系则无o。
优点:①由于数据似然在三元组层次开始,因此优化此似然相当于直接优化三元组层次的最终评价标准。②不假设重叠三元组在一个句子中如何共享实体,通过设计处理重叠三元组。③公式(3)的分解启发了一种新的抽取三元组的标注方案:学习了一个Subject标注器,可识别句子中的subject实体;对每个关系r,学习一个object标注器,可识别给定S的关系特定object。这种标记模式语序一次提取多个三元组。

1.BERT Encoder
这部分是对句子编码,获取每个词的隐层表示,可以采用 BERT 的任意一层,且这部分是可以替换的,例如用 LSTM 替换 BERT。
2.Cascade Decoder
对级联二分类标注框架进行实例化,基本思想是在两个级联步骤中提取三元组。首先,从输入的句子中检测subject,然后,对于每个候选subject检查所有可能的关系,看看一个关系是否可以将句子中的object与那个subject联系起来。级联解码器对应于所述两个步骤,由两个模块组成:Subject Tagger;Relation-specific Object Taggers。
Subject Tagger
这部分主要是对BERT Encoder获取得到的词的吟曾表示解码,构建两个二分类分类器预测subject的start和end索引位置,对每一个词计算其作为start和end的概率,并根据某个阈值,大于则标记1,否则标记0。公式如下:
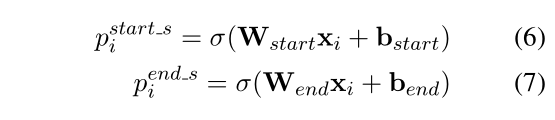
如框架图中所示,Jackie 被标记为 start,R 既不是 start 也不是 end, Brown 被标记为 end,其他的类似。在这里采用了最近匹配的原则,即与 jackie 最近的一个 end 词是 Brown, 所以 Jackie R. Brown 被识别为一个subject。文中并未考虑前面位置的情况。
Relation-specific Object Taggers
这部分会同时识别出 subject 的 relation 和相关的 object。
解码的时候比 Subject Tagger 不仅仅考虑了 BERT 编码的隐层向量, 还考虑了识别出来的 subject 特征,即下图。vsub 代表 subject 特征向量,若存在多个词,将其取向量平均,hn 代表 BERT 编码向量。
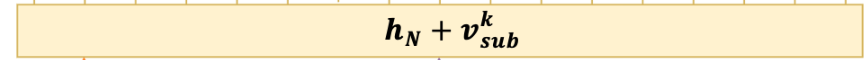
对于识别出来的每一个 subject, 对应的每一种关系会解码出其 object 的 start 和 end 索引位置,与 Subject Tagger 类似,公式如下:
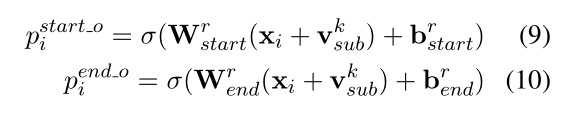
以图中的例子详细说明一下,图中的例子仅仅画出了第一个 subject 的过程,即 Jackie R. Brown,对于这个,在关系 Birth_place 中识别出了两个 object,即 Washington 和 United States Of America,而在其他的关系中未曾识别出相应的 object。当对 Washington 这个 subject 解码时,仅仅在 Capital_of 的关系中识别出 对应的 object: United States Of America。
以上便可以得到抽取到的三个三元组如下:
(Jackie R. Brown, Birth_place, Washington)
(Jackie R. Brown, Birth_place, United States Of America)
(Washington, Capital_of, United States Of America)
从以上抽取出来的三元组,确实解决了最开始提到的 SEO 和 EPO 的重叠问题。
Data Log-likelihood Objective
优化目标及模型损失函数:目标是较大化三元组抽取概率,subject和object的抽取都是采用span(跨度)方式,可采用二分交叉熵计算损失。优化目标公式如下:

Experiments
验证CASREL框架效果采用的是两个公开的数据集,NYT 和 WebNLG。


具体的实验效果如上图所示,其中 CASREL 分别采用了 随机初始化参数的BERT编码端、 LSTM 编码端以及预训练 BERT 编码端,实验结果主要说明以下结论:
①CASREL 框架确实有效,三种编码结构的效果都是要远高于其他的模型性能。
②采用预训练 BERT 之后,CASREL 框架更是逆天。

















 7453
7453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











