








Abstract
本文提出了关系三元组重叠的问题(一个sentence中有多个三元组,其中三元组中有的实体是同一个)。本文将其建模为级联二级制框架,从原来的
f
(
s
,
o
)
→
r
f(s,o) \rightarrow r
f(s,o)→r从实体对找关系的过程,变成
f
r
(
s
)
→
o
f_r(s) \rightarrow o
fr(s)→o给定头实体,针对头实体可能的关系,预测尾实体。即头实体不一定是subject,与multi-QA思想相似。
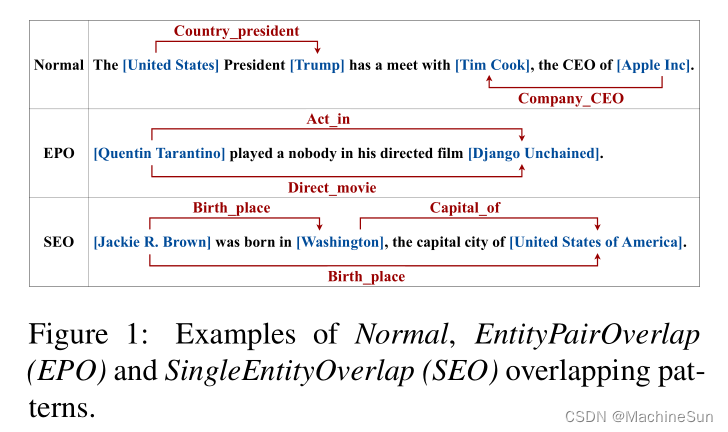
Model
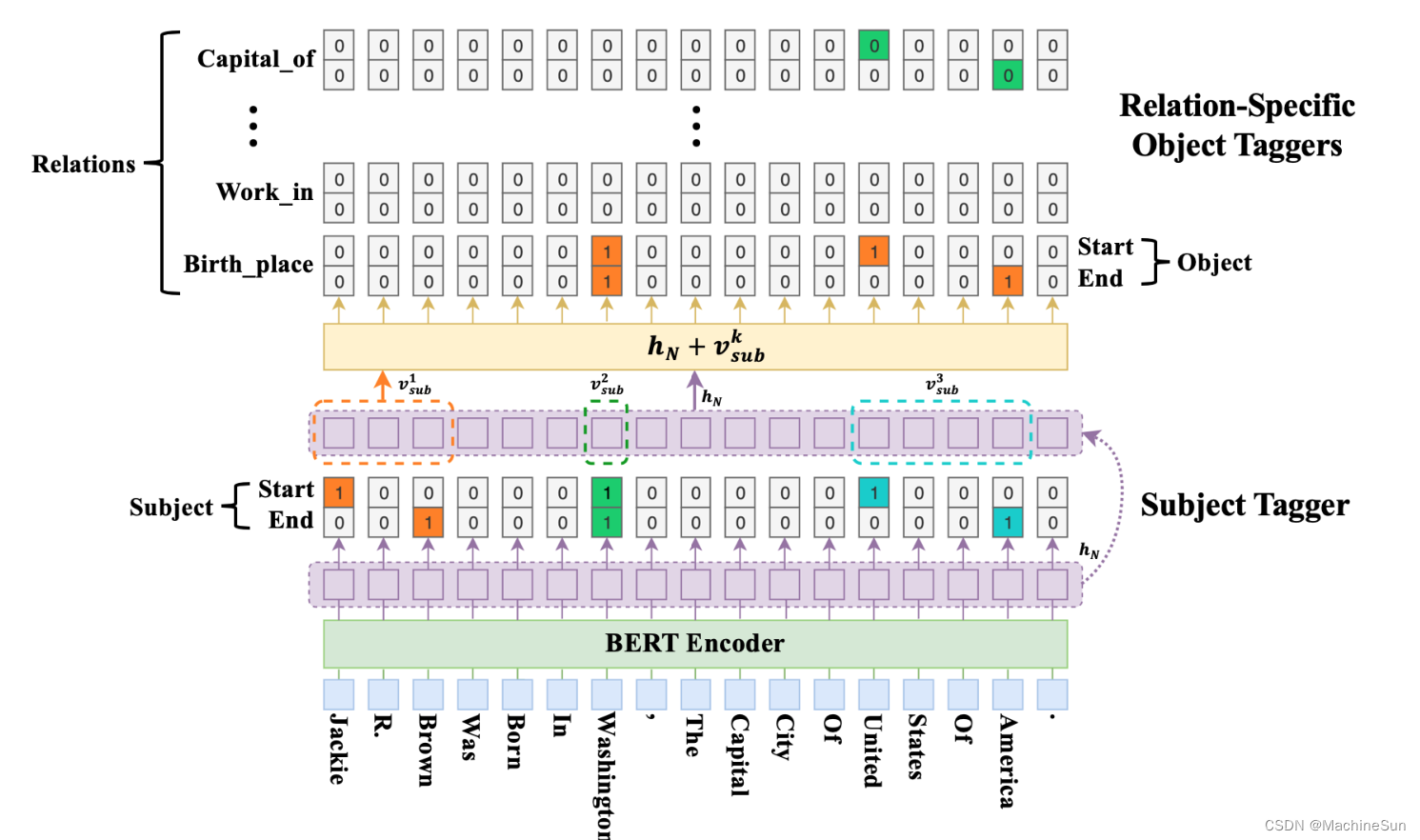
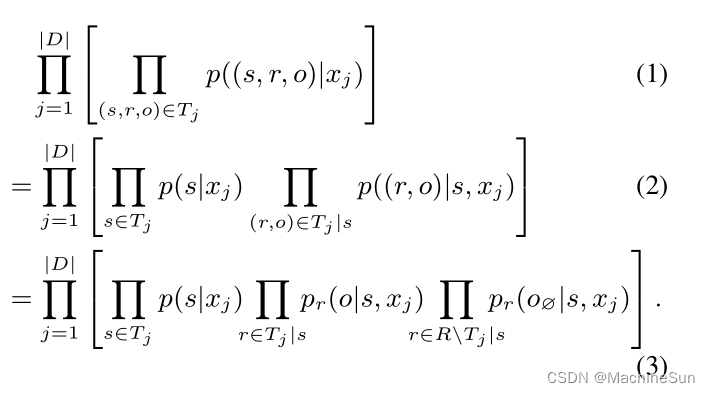
给定标记好的句子 x j x_j xj,和 x j x_j xj中潜在的重叠实体三元组集 T j = { ( s , r , o ) } T_j=\{(s,r,o)\} Tj={(s,r,o)}。先找到 s s s,再对关系 r r r,找到其对应的 o o o
Subject Tagger
本文中的subject和object只需找到边界,无需确定类型,首先找到句子中所有的subject,用0,1类别判定,不识边界的用零表示,对于句子中的多个subject会出现多个间隔的1,此时用就进原则,这里并不能解决关系重叠问题啊
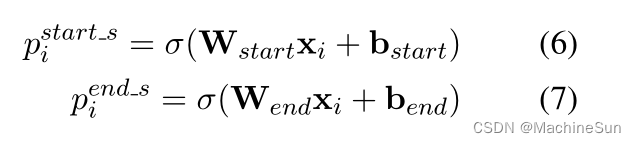
Relation-specific Object Taggers
针对每一个subject,遍历多有关系r,为每个关系确定一个object,如果object不存在,则用None表示。与头实体标记器直接解码BERT输出的向量不同,关系特定object标记器也考了头实体的特征

v
s
u
b
k
v_{sub}^k
vsubk表示低层模块中的头实体表示向量,为了保持
x
i
x_i
xi和
v
s
u
b
k
v_{sub}^k
vsubk保持维度一致,如果头实体有多个词语组成,则选择使用
v
s
u
b
k
v_{sub}^k
vsubk的平均向量。
Result
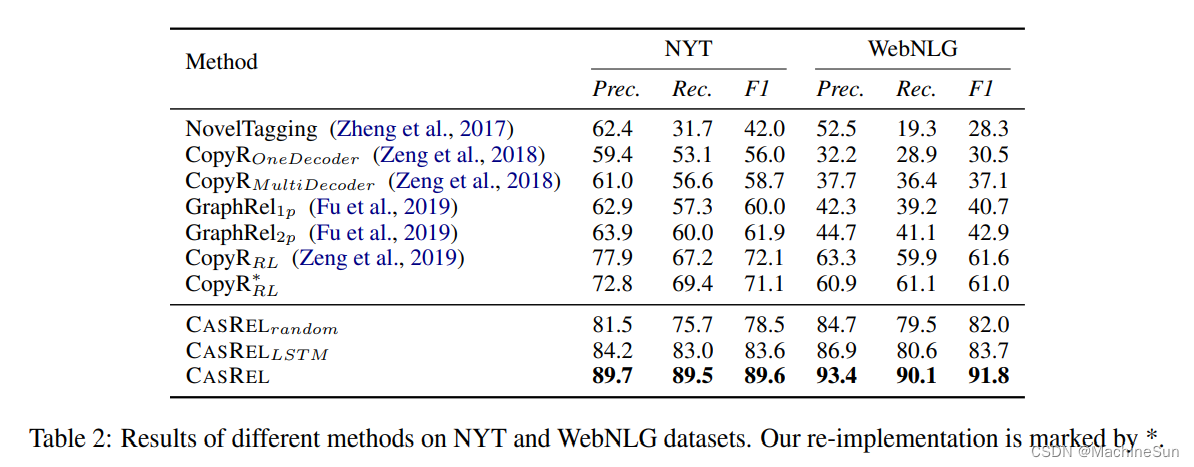
启示
- 对于NYT数据集来说,每一个头实体对应20多种关系,要遍历20多遍,想想这个复杂度就让人头疼

















 7453
7453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











