







1、实体名识别方法
命名实体识别方法:基于规则的方法、基于统计的方法。
基于统计的方法—基本思想是利用训练语料中的语言信息作为先验概率,来对测试语料的标注概率作估计。标注语料时不需要渊博的专业知识,
并且可以在较短时间内完成。这类系统在移植到新的领域时可以不做或少做改动,只要利用新的语料训练一遍即可。
从目前来看,基于统计的方法在整个自然语言处理领域中用的最多,与基于规则的方法相比,基于统计的方法不是靠人工编写规则来识别实体
名,而是依靠大规模的语料库,通过对标注语料的训练来实现自我学习的过程,自动获取语言学知识,与编写规则相比,带标注的语料库的构建要相对容易些,对构建者的语言学知识要求也比较低.
库的规 模和标注质量对模型的最终训练结果影响也很大。用于实体名识别的统计方法主要有N-gram语言模型、HMM、最大熵模型、决策树方法、基于转换的学习方法、推进方法、表决感知器方法以及条件马尔可夫模型等。其中评价较好的是N-gram语言模型和HMM,而最大熵模型因其自身的特点仍然是当前的主要研究方向。对于基于统计的实体名识别方法来说,建立一个合适的统计模型是其关键所在,然后利用大规模的语料对识别模型中的参数进行训练,另外语料
则的方法那样具有很强的主观性。一般来说,基于统计的方法效率要高于基于规则的方法,而且基于统计的方法是机器从语料库中自我学习获取知识因而一致性较好,不像基于规
N-gram 语言模型是用来计算一个词串或者是一句话W=w1w2...wn出现概率的统计模型。N-gram 模型假设某词的出现概率只与该词前面的 n-1 个
词有关。即:词wi 出现的概率为 P(wi|wi-n+1...wi-1)。而整个词串出现的概率为
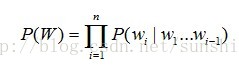
按照相关历史长度的不同,n-gram 语言模型可以根据 n 的不同取值分为不同的文法模型。
当n=1时,即出现在第 i 位上的词wi独立于历史时,称为一元文法模型,也被称为一阶马尔可夫链,词串概率表示为
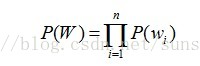
当n=2时,即出现在第 i 位上的词wi仅与它前面的一个历史词wi-1有关,称为二元文法模型,也被称为二阶马尔可夫链,词串概率表示为

为计算某个词串或一个句子的概率,根据 n 的不同,应选择不同的参数。假设一种语言的词表中有| V |个单词,当 n=1 时,每个单词的出现概率
和它的历史没有任何关系,则总共需要确定| V | − 1个概率参数P (wi );当 n=2 时,每个单词的出现概率和它前一个单词有关,则总共需要确定| V |*(| V | −1 )个概率参数P(wi|wj)。
2、参数 N 的选择及最大似然估计
对于 N-gram 语言模型,在参数估计方面一般采取最大似然估计。利用语料数据中词汇同现的相对频率就可以得到条件概率的极大似然估计,如
下式:
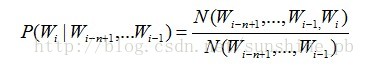 (*)
(*)其中N(wi-n+1,wi-n+2,...,wi-1,wi)是在训练语料中词串Wi-n+1,...,Wi-1,Wi的出现频率。
对于1-gram语言模型,每个单词的出现的概率的计算如下:
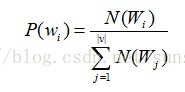
对于2-gram语言模型,其计算如下:

模型中参数n的选择要兼顾有效性和描述能力。一般情况下,模型的描述能力随n值的增大而增强,然而估计的有效性却反而降低。但是过小的n
值又不能包含长距离的词法信息,所以目前常用的n值一般取2或3
不同的N-gram模型中参数n划分计算出来的词概率是不一样的。对分词结果中的每一个词,通过公式(*)计算得到该词的出现概率,根据设定的
阀值,判断是否接受该词,若计算结果大于阀值,则将该词接受为实体,然后分词窗口后移,继续下一词的实体识别。
命名实体识别是基于统计的模型以及条件随机场算法的框架下的N-Gram模型进行的,与编写规则的实体识别方法相比,带标注的语料库的构建
要相对容易些,对构建者的语言学知识要求也比较低。















 1120
1120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









