







1. PerSAM:PERSONALIZE SEGMENT ANYTHING MODEL WITH ONE SHOT
1.1 面临问题
应用场景:
(1)分割多个相似物体中的一个对象
(2)同时分割同一图像中的多个相同物体
(3)沿视频跟踪不同的物体
SAM模型:
(1)SAM缺少分割特定视觉概念的能力。即对于每一幅图像,都需要在复杂的场景中准确地找到目标物体,然后使用适当的提示激活 SAM 进行分割。
1.2 应用技术
PerSAM采用了一种无需训练的个性化方法,允许用户通过仅提供单次数据(即一张带有参考遮罩的图像)来个性化定制通用的SAM,使得SAM能够专注于目标对象的前景区域,从而提高分割的准确性。以自动识别和分割其他相关图像中特定的视觉概念,如用户的宠物狗。
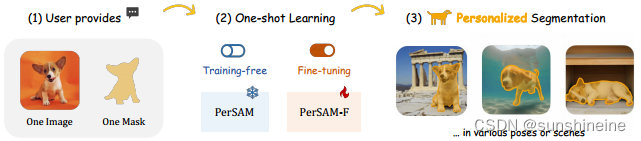
论文的创新点如下:
对SAM架构的改进如下:
(1)正-负位置先验:我们根据所有局部部分的外观计算出新测试图像中目标物体的位置置信度图。然后,我们选择先前的位置作为PerSAM的点提示符。
(2)目标引导注意力:我们通过位置置信图来引导 SAM 解码器中的每个令牌到图像的交叉注意力层。这明确地迫使提示符主要集中于前景目标区域进行密集的特征聚合。
(3)目标语义提示:为了明确地为 SAM 提供高级目标语义,我们将原始的提示符与目标对象的嵌入融合在一起,为低级的位置提示符提供额外的视觉线索以进行个性化分割。
(4)级联后处理:通过迭代地将预测的遮罩反馈到解码器中进行两步后处理,以改善边缘粗糙度和背景噪声。
其他创新点如下:
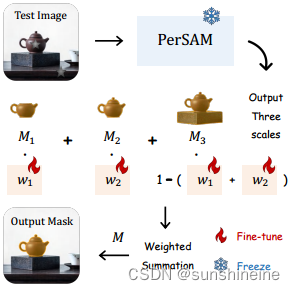
(4)PerSAM-F:为了解决分割尺度的歧义问题,进一步提出了PerSAM的一个微调变体,称为PerSAM-F。该变体冻结了整个SAM模型,只对两个参数进行微调,以适应不同对象的最佳尺度。
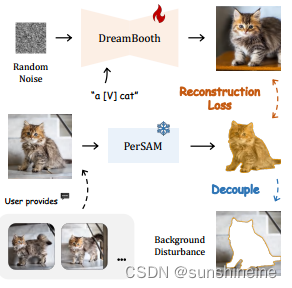
(5)DreamBooth辅助:论文还提出利用PerSAM来改进DreamBooth,这是一种用于个性化文本到图像合成的方法。通过在训练期间减少背景干扰,PerSAM可以帮助生成更高质量的目标外观,并更忠实于输入的文本提示。
(6)新数据集PerSeg:为了评估个性化对象分割的效果,研究者们构建了一个新的数据集PerSeg,并在多种单次图像和视频分割基准测试中测试了他们的方法。
1.3 模型结构
(1)正负位置先验
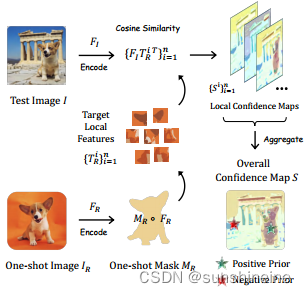
用户提供包含感兴趣目标对象的参考图像,以及与参考图像
相对应的一次性掩码
,它标识了参考图像
中目标对象的位置。从参考图像
中提取目标对象的局部特征
,Encode 编码器提取参考图像
和测试图像
的特征,生成特征图
和
。使用余弦相似性Cosine Similarity来计算测试图像
中的每个局部特征与参考图像
中的局部特征之间的相似度。对于测试图像
中的每个局部特征,根据与参考图像
的相似度计算一个局部置信度图Local Confidence Maps。这个图表示了测试图像中每个像素属于目标对象的概率。通过聚合所有局部置信度图,生成一个整体置信度图Overall Confidence Map S。这个图提供了目标对象在整个测试图像中的分布概率。根据整体置信度图 S,选择置信度最高的点作为正先验(Positive Prior),这代表了目标对象最可能的中心位置。选择置信度最低的点作为负先验(Negative Prior),这代表了背景或非目标区域。
(2)目标引导注意(左)和目标语义提示(右)
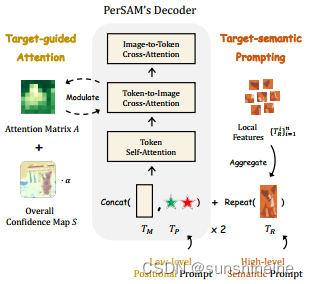
将从参考图像提取的目标对象的局部特征Local Features进行聚合aggregate,形成一个统一的、关于目标对象的表示,生成高层次语义提示,提供了目标对象的额外视觉线索或语义信息。
是模型中用于生成分割掩码的可学习令牌,
是基于用户提示的原始令牌,提供目标对象位置信息的低层次位置提示。目标语义提示Target-semantic Prompting将
与
结合,增强模型对目标对象的识别能力,共同传送到掩码解码器中。
在Image-to-Token Cross-Attention (图像到令牌的交叉注意力)中,图像的特征与提示令牌
进行交互,帮助模型理解图像内容与用户指定的目标之间的关系。Token-to-Image Cross-Attention (令牌到图像的交叉注意力)反向操作,将处理后的令牌特征重新映射到图像特征上,以细化模型对目标对象的理解。Target-guided Attention (目标引导注意力)在令牌到图像的交叉注意力阶段利用目标对象的位置信息来引导解码器的注意力,使用整体置信度图 S 来调制注意力矩阵 A,通过引入一个平衡因子 α,来调整注意力分布,使得模型更加关注目标区域。
整个流程的目的是通过结合低层次的位置信息和高层次的语义信息,以及通过注意力机制对目标区域进行聚焦,来实现对用户指定目标对象的精确分割。这种方法特别适用于只有少量标注数据或需要快速适应新目标的场景。
2. VRP-SAM: SAM with Visual Reference Prompt
2.1 面对问题
SAM模型:
(1)SAM依赖于用户提示,要求用户对目标物体有全面的了解。用户对目标对象的熟悉程度会显著影响提供特定提示的有效性。
(2)不同图像中目标对象的位置、大小和数量的变化需要为每个图像定制提示,这大大降低了 SAM 的效率。
(3)一些方法引入了语义相关模型,建立参考 – 目标的关联,以此获得目标物体的伪掩码。然后,设计一种采样策略,从伪掩码中提取一组点和边界框提供为SAM进行分割。这些方法忽略了伪掩码中的误报,并且对超参数非常敏感。泛用性很差。比PerSAM强
提出集成可视参考提示来克服上述问题并增强 SAM 的适应性。可视参考提示指的是带注释的参考图像,这些注释可以是点、框、涂鸦和掩码。
2.2 应用技术
(1)提出了一个由特征增强器和提示生成器组成的视觉参考提示(VRP)编码器,它接受多种格式的视觉参考,并将其编码为提示嵌入,而不是几何提示。
(2)特征增强器受元学习启发,能够将参考图像的注释信息编码到参考图像和目标图像的特征中,从而在两个图像之间建立语义关联。
(3)提示生成器的目的是为SAM掩码解码器生成一组富含语义信息的视觉参考提示嵌入(embeddings),这些嵌入能够有效地指导目标图像中的前景对象分割,以实现目标图像中特定对象的精确分割。
(4)通过结合BCE损失和Dice损失,VRP-SAM在生成精确分割结果方面表现出色。
2.3 模型结构
VRP编码器由特征增强器和提示生成器组成。
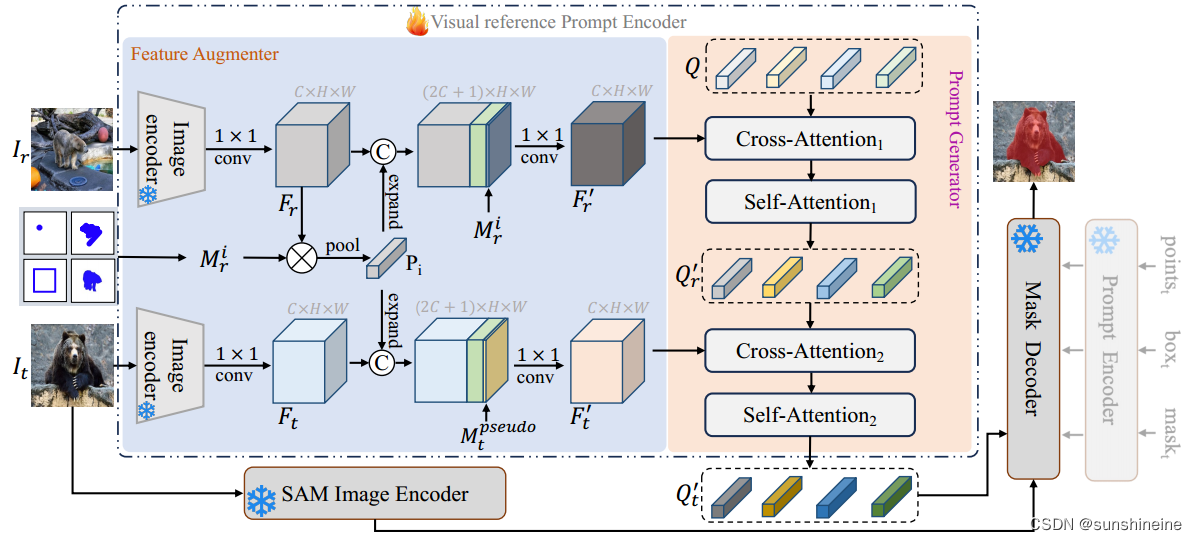
(1)特征增强器
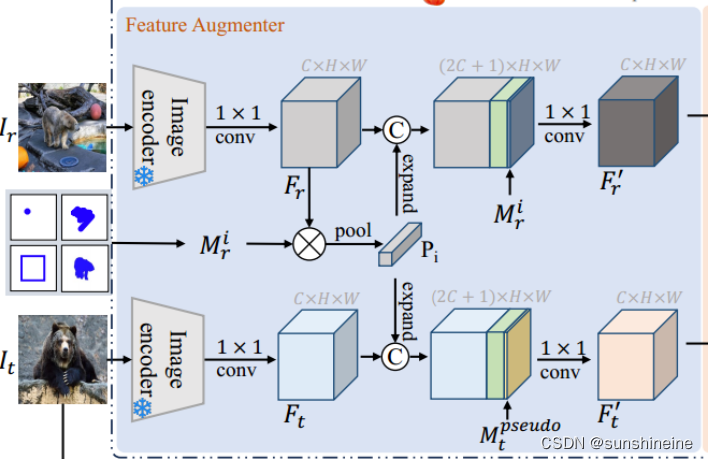
(1)初始编码:使用语义感知图像编码器(例如ResNet-50)分别对参考图像和目标图像
进行编码,得到特征图
和
。
(2)提取原型特征:使用参考图像的掩码(表示以下注释格式之一:点、涂鸦、框或掩码)从参考图像的特征图
中提取与特定类别
相关的原型特征
。
(3)特征增强:将原型特征与参考图像和目标图像的特征图
和
进行拼接,增强特征图中关于类别
的上下文信息。
与掩码
连接,
与伪掩码
连接。
(4)降维处理:通过共享的1×1卷积层减少增强特征的维度,得到降维后的特征图(和
),这些特征图包含了类别
的前景表示和其他类别的背景表示。
(5)特征图输出:最终,特征增强器输出增强后的参考图像和目标图像特征(和
),这些特征随后被送入提示生成器(Prompt Generator)以获取一组视觉参考提示。
(2)提示生成器
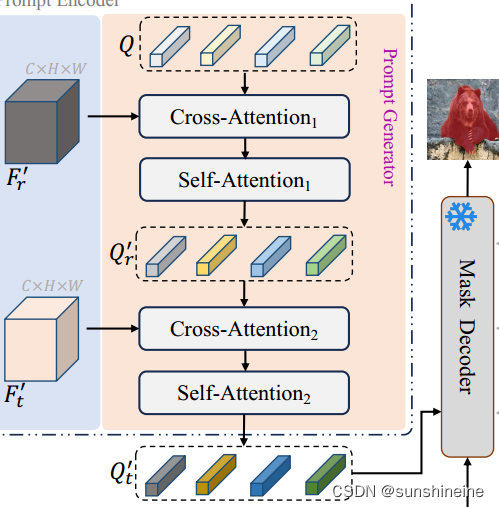
(1)引入可学习查询(queries):提示生成器首先引入一组可学习的查询向量,这些查询向量用于从参考图像中提取与目标对象相关的语义信息。
(2)交互参考图像特征:这些查询向量通过交叉注意力(cross-attention)和自注意力(self-attention)层与参考图像特征进行交互,从而获得关于待分割对象的类别特定信息。
(3)生成目标图像提示:接着,这些查询向量通过交叉注意力与目标图像特征
进行交互,以获取目标图像中的前景信息。之后,使用自注意力层更新这些查询向量,生成一组与SAM表示对齐的提示
。
(4)产生提示嵌入:最终生成的作为视觉参考提示嵌入,它们具备指导目标图像中特定语义对象分割的能力。将这些视觉参考提示嵌入输入到掩码解码器中,可以生成目标图像中类别
的掩码
。
3. AI-SAM: Automatic and Interactive Segment Anything Model
3.1 面临问题
(1)SAM 模型完全依赖用户交互,而且“交互式适配”在过程交互上产生了限制;
(2)SAM 对类别语义粒度理解不足,导致任务域一旦转移性能就会下降;
(3)除了SAM,当前模型的适配策略往往偏向自动或交互式方法之一。 模型如何无缝结合自动和交互功能?什么能够构成有效的自动和交互式模型提示?
3.2 应用技术
(1)引入了开创性的自动+交互式提示器 (AI-Prompter),能够实现自动分割+交互式分割的任意分割,它可以自动生成初始点提示,同时接受额外的用户输入。
3.3 模型结构
(1)整体流程
整个流程是一个迭代的过程,它结合了自动化的高效性和交互式灵活性。这种设计使得模型能够适应各种不同的图像分割任务,同时减少对大量标注数据的依赖。
流程如下:输入一张图片。经过图像编码器提取特征,送入到AI-Prompter中自动生成初始的点提示,送入到提示编码器将它们转换成一种编码格式,掩码解码器使用编码后的图像特征和点提示自动生成一个初始的分割掩码。在交互式模式下,用户可以查看自动生成的分割结果,并根据需要添加、移动或删除点提示,以此来改善分割效果,将用户调整后的点提示再次编码,以生成更新后的分割掩码。
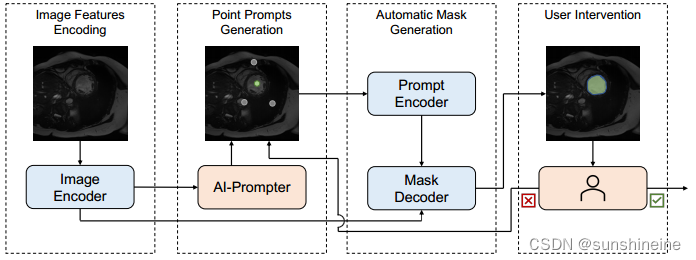
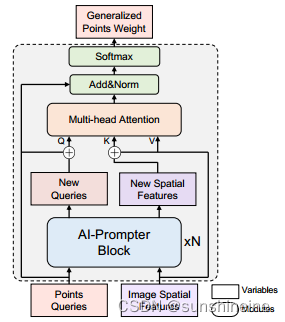
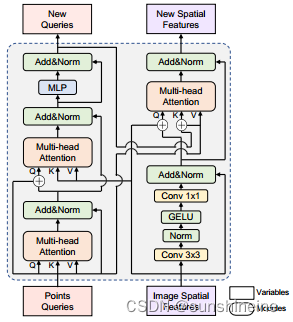
(2)AI-Prompter
AI-Prompter模块通过一系列的注意力机制和归一化步骤来提炼图像特征,并生成用于指导分割的点提示。这个过程结合了自动化和交互式的特点,允许模型在没有人类干预的情况下生成初始分割结果,同时也可以结合用户的输入来提高分割的准确性。
4. ClipSAM: CLIP and SAM Collaboration for Zero-Shot Anomaly Segmentation
4.1 面临问题
(1)CLIP 主要关注不同输入间的全局特征匹配,对局部异常区域分割不准确
(2)SAM 倾向于生成大量冗余掩码,没有适当提示约束,需要后处理
4.2 应用技术
(1)创新性地提出了一种名为 ClipSAM 的 CLIP 和 SAM 协作框架用于零样本异常分割(ZSAS),即首先利用 CLIP 的语义理解能力进行异常定位和粗分割,将其作为 SAM 细化异常分割结果的提示约束。
(2)引入了一个模块(UMCI:统一多尺度跨模态交互模块),用于在 CLIP 的多个尺度上进行语言与视觉特征的交互,推理异常的位置,实现预期定义和粗分割。
(3)设计了一个新颖的多级掩码细化(MMR)模块,它从 CLIP 的定位信息中提取点和边界框提示,让 SAM 获取分层级的掩码并进行融合。
4.3 模型结构
ClipSAM框架利用CLIP模型的语义理解能力进行异常区域的定位和粗略分割,然后通过UMCI模块中的跨模态交互进一步提升定位精度,最后使用SAM模型和从UMCI获得的空间提示来生成精确的分割掩码。UMCI模块是ClipSAM中用于处理跨模态交互的核心部分,通过结合行、列和多尺度的视觉特征与语言特征,以增强异常区域的定位和分割。
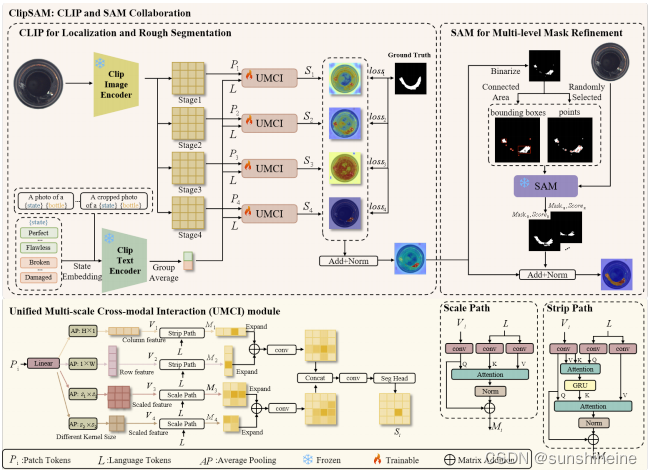
(1) CLIP for Localization and Rough Segmentation
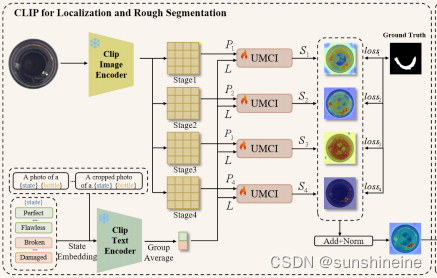
这部分表明整个模块的目标是利用CLIP模型进行异常区域的定位和粗略分割。输入一张图像后,经过图像编码器提取特征,将特征图分割成几个小块/区域(~
),分别与文本编码器将输入的文本描述转换成的特征表示相结合,共同传送到UMCI模块中进行处理,生成每一块融合了语义信息和视觉信息的特征图。最终通过Add+Norm来整合不同来源的特征,生成一个粗略的分割图,这个分割图能够标识出图像中可能的异常区域。
(2)UMCI(统一多尺度跨模态交互模块)
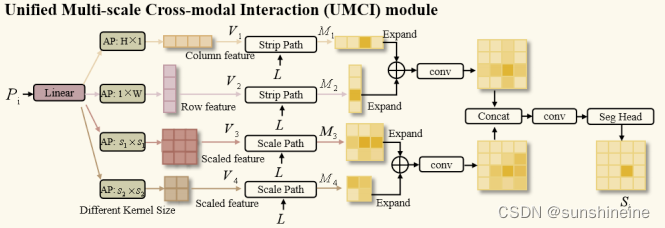
UMCI模块通过Strip Path(专注于提取图像的行和列级别的特征,这些特征有助于精确定位异常区域,生成一个编码了图像中每个像素点的语义信息的特征图)和Scale Path(处理不同尺度的视觉特征,以获得全局的视觉理解。通过使用不同核大小的平均池化层,Scale Path生成包含了多尺度的视觉信息的特征图)来处理和融合图像特征和文本特征。 最终输出标记了图像中每个像素属于异常区域还是正常区域的分割图(segmentation map)。
(3)MMR(多级掩码细化模块)
这个模块使用 SAM 模型的注意力机制来精细化 CLIP 模型生成的粗略分割结果,对异常区域进行更精细的分割,生成高质量的分割掩码,这些掩码可以更准确地标识出图像中的异常部分。通过结合 CLIP 的语义理解和 SAM 的精细分割能力,ClipSAM 能够实现零样本异常分割任务中的优异性能。
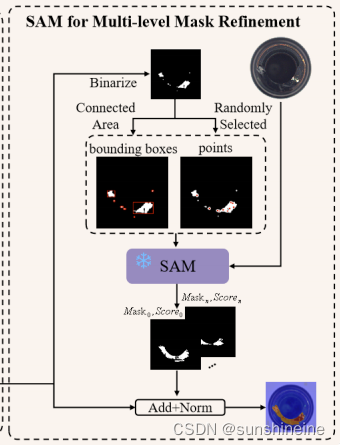
通过Binarize将 CLIP 生成的粗略分割图转换为二进制掩码。在二进制化之后,会识别出图像中的连通区域。从连通区域中随机选择一些点,这些点将作为 SAM 模型的输入提示,帮助模型识别和细化异常区域。除了随机选择的点,还可能从连通区域中生成边界框(bounding boxes),这些边界框标记了异常区域的位置和范围。
SAM 模块接收来自 CLIP 的粗略分割结果和从该结果中提取的点或边界框作为提示。SAM 利用这些提示来生成更精细的分割掩码。最后通过Add+Norm将生成的分割掩码与原始的粗略分割结果进行融合。整个流程的目的是通过 SAM 模块对 CLIP 生成的粗略分割进行多层次的细化,以提高分割掩码的精确度和质量。
5. SAMAUG: POINT PROMPT AUGMENTATION FOR SEGMENT ANYTHING MODEL
5.1 面对问题
简单的提示(例如单个点)会导致 SAM 模型出现歧义。我们认为可以通过自动生成额外的点提示来进一步提升 SAM 的性能。
5.2 应用技术
SAMAug是一种用于增强图像分割性能的方法,它通过生成增强的点提示(point prompts)来提供更多关于用户意图的信息。
(1)初始点提示(Initial Point Prompt):用户给出一个点提示,SAM使用这个提示生成初始的分割掩码(initial mask)。
(2)点提示增强(Point Prompt Augmentation):基于初始分割结果,SAMAug自动生成额外的点提示。这些额外的点提示可以通过随机采样、最大熵准则、最大距离准则或显著性、五种框提示等不同策略来选择。
(3)增强分割掩码(Augmented Segmentation Masks):将增强的点提示与初始点提示结合,SAM可以生成改进的分割掩码。
5.3 模型结构
从一个初始点提示开始,SAM首先产生一个初始分割掩码,这个掩码被用作SAMAug生成增强点提示的基础。然后通过不同的方法(随机采样、基于最大差异熵的采样、最大距离采样和基于显著性的采样)生成增强点。这些增强点作为额外的提示输入到SAM模型中。SAM模型结合初始点和增强点,生成更准确的分割结果。SAMAug通过自动生成额外的点提示,减少了用户在分割任务中的输入需求,同时提高了模型性能。
6. Influence of Prompting Strategies on Segment Anything Model (SAM) for Short-axis Cardiac MRI segmentation
6.1 面临问题
应用场景:
(1)精确分割:医学成像要求非常精确的分割,以区分心脏的不同结构,如左心室(LV)、心肌和右心室(RV)。
(2)处理精细结构:心脏MRI分割任务可能需要识别和分割心脏内的小结构,如肺结节或其他细微特征。
(3)边界清晰度:分割掩模(mask)的边界需要清晰,这对于诊断和后续的医学分析至关重要。 SAM模型:
(1)尽管 SAM 旨在泛化处理多种分割任务,但在处理需要精细结构分割或精确边界的特定医学成像任务时,它存在局限性。
6.2 应用技术
(1)不同的提示策略:研究了包括边界框、正样本点、负样本点及其组合在内的不同提示策略对SAM分割性能的影响。
(2)有限标注数据的微调:评估了使用不同数量的标注数据对SAM模型进行微调的效果,从有限的体量到完整标注的数据集。
(3)微调与提示策略的结合:探讨了微调SAM模型时结合使用边界框的提示策略对分割性能的积极影响,以及在没有边界框的情况下微调可能导致性能下降的问题。
6.3 模型结构
作者考察了以下组合:正样本点与边界框的组合;正样本点与负样本点的组合;边界框与负样本点的组合;同时使用所有三种提示策略的组合。
实验结果表明,不同的提示策略对分割性能有显著影响。
(1)使用负样本点可以在所有配置中提高性能。
(2)当同时使用边界框和负样本点时,性能提升的效果减少。
(3)通过增加正样本点的数量,只有在不使用边界框或负样本点的情况下,性能才有轻微提升。(4)微调模型时,使用边界框作为提示可以提高性能,而没有使用边界框的微调则导致性能下降。
7. Learnable Ophthalmology SAM
7.1 面临问题
应用场景:
(1)分割的重要性:在眼科诊断和治疗中,分割是至关重要的步骤,因为眼科部门拥有超过10种不同类型的成像方式。
(2)多模态图像的挑战:多模态图像之间的差异带来了不同的分割目标,例如从彩色眼底图像中分割血管,以及从光学相干断层扫描(OCT)中分割视网膜层。这些差异阻碍了单一模型在眼科的应用,因为大多数现有的分割算法依赖于专家的标签或具有较弱的泛化能力。
(3)微调方法的不足:在医学领域,全参数微调或仅优化模型头部的微调通常无法提供可用的结果。
SAM模型:
(1)现有计算机视觉模型的局限性:如Segment Anything (SAM) 虽然在自然场景中证明了有希望的分割能力,但它们无法从医学图像中分割血管或病变,这些对于医生的诊断或治疗计划是有帮助的。
(2)SAM的不足:SAM可以从OCTA图像中找到一些血管,但它无法从彩色眼底图像中分割血管或病变。可能的原因是血管或病变与视网膜之间的边缘差异不明显。对于视网膜OCT图像,SAM也不能产生层信息。
7.2 应用技术
(1)一次性机制 (One-shot Mechanism):在训练过程中,仅基于一次性机制训练提示层和任务头部,而不是对整个网络进行全面微调。
(2)变换器层 (Transformer Layers):在ViT模型中,输入图像首先通过分块嵌入层处理,然后通过多个变换器层进行编码,最后由任务头部生成特定任务的输出。
(3)提出了一个新的可学习提示层,用于从每个变换器层学习医学先验知识,并作为任务特定的提示。
7.3 模型结构
在SAM的基础上,作者将一个新型的学习型提示层Learnable Prompt Layer插入到每个变换器层之间,该层能够从每个变换器层中学习医学图像的目标分割任务的先验知识,以提高分割的准确性。并且仅对提示层和任务头部进行微调,这样可以减少训练资源的消耗,同时保持模型对特定任务的适应性,提高模型在特定任务上的效率和性能。通过学习型提示层,模型不仅能够在不同模态的图像(彩色眼底图像和OCT图像)中自动学习感兴趣的目标,还能在不同的数据集之间保持泛化能力。

Conv 1x1: 这是提示层的主要部分,使用1x1的卷积核来调整特征的通道数。
LayerNorm: 在提示层中,层归一化用于稳定训练过程。
GELU: 激活函数,为模型引入非线性。
DW-Conv3x3: 3x3的深度可分离卷积用于捕获输入特征的局部模式。
LayerNorm: 第二层归一化。
Conv 1x1: 另一个1x1卷积层,可能用于进一步的特征转换。
GELU: 第二层的GELU激活函数。
8. SAM-OCTA: Prompting Segment-Anything for OCTA Image Segmentation
8.1 面临问题
应用场景:
(1)在研究中,特定视网膜结构(如视网膜血管RV和黄斑无血管区FAZ)的分割对于检测和监测视网膜疾病至关重要。尽管先前的方法在准确性和精确度上表现良好,但OCTA分析通常需要关注图像中的局部信息,这尚未得到充分满足。
SAM模型:
(1)SAM模型的挑战:将SAM(Segment Anything Model)应用于医学图像分割面临着一系列挑战,因为医学图像在质量、噪声、分辨率等方面与自然图像有显著差异,这影响了SAM的分割性能。
8.2 应用技术
(1)低秩适应(LoRA)技术:论文采用了 LoRA 技术对 SAM 进行微调,这种方法在每个变换器块中引入了额外的线性网络层,有助于保留 SAM 在图像理解方面的强能力,同时提高其在 OCTA 格式图像上的性能。
(2)生成提示点的策略:这些提示点用于在 OCTA 图像中进行局部视网膜血管(RVs)、动脉和静脉的分割。
(3)研究设置了全局和局部两种分割模式,并采用了两种提示点生成策略,即随机选择和特殊注释,以探索提示点的效果和机制。
8.3 模型结构
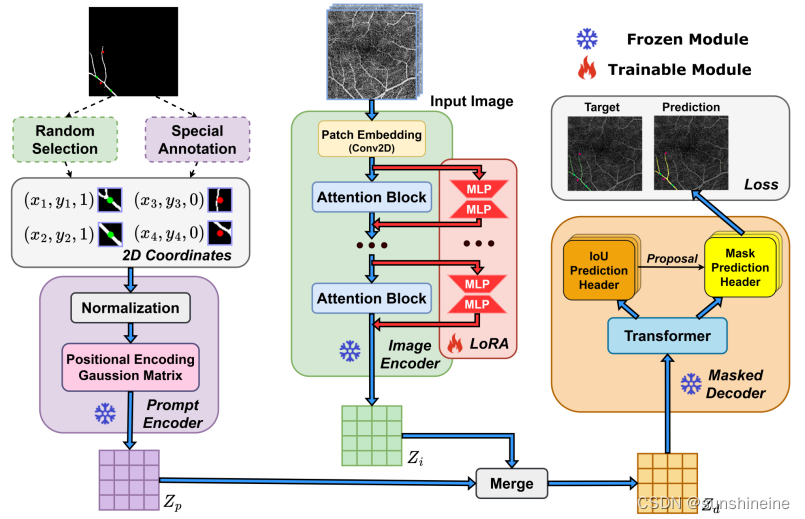
(1)图像编码器
输入一张图片传送到图像编码器中,在图像编码器中引入LORA,即低秩适应(Low-Rank Adaptation)微调技术 。用于调整和优化预训练模型以适应特定的任务或数据集。在深度学习领域,尤其是在自然语言处理(NLP)和计算机视觉(CV)中,预训练模型(如BERT在NLP中,或在CV中的图像识别模型)已经在大规模数据集上进行了训练,并能够捕捉到丰富的特征表示。然而,这些通用的预训练模型可能需要针对特定任务进行调整以获得最佳性能。 LORA的核心思想是在模型的特定部分引入低秩矩阵,以最小的参数改动实现对模型的调整。这样做的好处是可以保留预训练模型的大部分权重,同时只对模型的一小部分进行微调,从而减少了计算资源和时间的消耗。以下是LORA方法的一些关键点:
低秩矩阵是具有较少非零元素的矩阵,它们以更紧凑的形式捕获数据的重要特征。在微调过程中,只有低秩矩阵的参数会被更新,而预训练模型的主体部分权重保持不变(冻结)。这样可以快速适应新任务,同时保留预训练模型的强大特征提取能力。由于只有少量参数被更新,LORA还有助于减少过拟合的风险,特别是在数据量较小的情况下。
(2)提示编码器
提示编码器接收稀疏提示(如点、框、文本)和密集提示(如掩码)。在这项工作中,选择点作为提示,并提出了两种提示点的生成策略:随机选择(Random Selection,提示点是随机生成的,这有助于模型的泛化能力)和特殊注释(Special Annotation,侧重于选择具有医学意义的点,如血管的分叉点、交叉点和端点这些特殊点)。还将分割这些提示点作为输入,指导模型关注OCTA图像中特定的局部区域。提示编码器对坐标输入进行嵌入,并将这些信息与图像编码器的特征相结合。
(3)全局与局部模式
论文中还提到了全局模式和局部模式两种分割任务。在全局模式下,图像中的所有目标都需要被分割;而在局部模式下,只有提示点指定的单个对象会被分割。
9. Segment Anything Model (SAM) for Radiation Oncology
9.1 面临问题
应用场景:
(1)手动分割的局限性:目前,OARs(在治疗过程中特别关注以尽量减少辐射暴露的器官)的划分过程是手动进行的,由放射肿瘤学家或剂量师执行。这个过程需要对CT图像进行逐层深入分析,既耗时又费力。
(2)现有自动分割方法的局限性:尽管已有多种自动分割方法被提出,包括可变形图像配准、基于图谱的自动分割和基于深度学习的分割,但它们的准确性和效率存在局限性。
SAM模型:
(1)SAM模型的潜力:Segment Anything Model (SAM) 展示了作为通用模型的潜力,但它在医学图像上的性能,尤其是在放射治疗案例中的表现尚不清楚。
9.2 应用技术
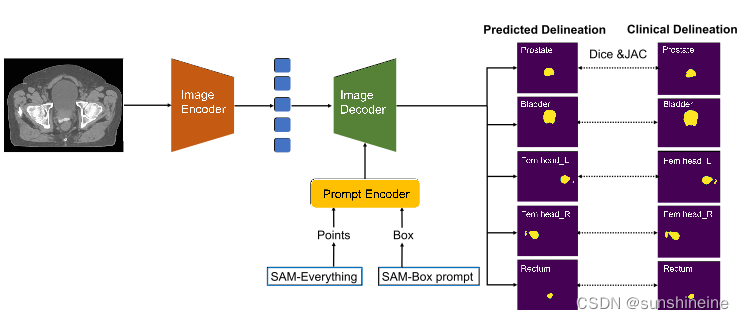
评估了SAM的两种模式:“segment anything”模式和“box prompt”模式。前者生成图像中所有对象的分割掩码,而后者需要用户指出感兴趣的区域。评估这两种模式的性能使用了Dice系数和Jaccard指数,这两个指标用于衡量SAM预测结果与临床手动勾画(ground truth)之间的空间重叠程度。
结果表明,SAM的“segment anything”模式在大多数OARs中都能达到临床可接受的分割结果,Dice分数高于0.7,而“box prompt”模式进一步提高了Dice分数0.1至0.5,显示了在手动框选提示的帮助下,SAM的性能有所提升。
9.3 模型结构



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









