







 本文介绍了一种新的视频分割模型SAM-Track,结合SAM的关键帧分割和DeAOT的跟踪技术,提供交互式和自动两种模式,实现多目标跟踪并在DAVIS-2016和DAVIS-2017上展示了优秀性能。
本文介绍了一种新的视频分割模型SAM-Track,结合SAM的关键帧分割和DeAOT的跟踪技术,提供交互式和自动两种模式,实现多目标跟踪并在DAVIS-2016和DAVIS-2017上展示了优秀性能。
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2023年5月11日
论文:
[2305.06558] Segment and Track Anything (arxiv.org) https://arxiv.org/abs/2305.06558代码:
https://arxiv.org/abs/2305.06558代码:
2. 摘要
作者提出了一种支持多模态交互的统一视频分割模型SAM-Track,SAM-Track具有出色的跟踪和分割能力以及两种用户友好的交互模式,以适应不同应用的不同需求。
对于跟踪和分割能力,SAM-Track将交互式关键帧分割模型(SAM)与作者提出的基于AOT的跟踪模型(DeAOT)结合在一起,利用高效的DeAOT跟踪模式,SAM-Track可以快速跟踪多个目标速度。还集成了Grounding-DINO,这使得该框架能够支持基于文本的交互。
对于交互模式,SAM-Track可以使用多模态交互方法(如点击、绘图和文本输入)跟踪和分割视频中的任何对象。这些交互方法为用户提供了灵活的选项,可以在视频的第一帧中选择感兴趣的对象。然而,自动模式允许SAMTrack跟踪出现在视频任何帧中的任何新对象。
通过实验在DAVIS-2016测试(92.0%)和DAVIS-2017测试(79.2%)上证明了SAM-Track的卓越性能及其在各种应用中的实用性。SAM-Track的高效性和通用性使其适用于各种不同要求的领域。
3. 前言
视频分割在现实世界的广泛应用中具有巨大的潜力,包括无人机行业、自动驾驶、医疗图像处理、增强现实和生物分析等。由于不同领域的需求不同,视频分割模型需要支持多种交互方式。
因此,它被分为几个子任务,即无监督(自动)视频分割,半监督(掩码引导半自动)视频分割,交互式(基于涂鸦或点击)视频分割和语言诱导视频分割。每个子任务都有相应的分段模式,并关注特定的字段。然而,开发一个统一的视频分割框架,有效地满足每个领域的不同需求,还没有得到充分的探索。
SAM能够从灵活的提示(包括点、框和文本)生成高质量的对象掩码,这大大增强了它的用户友好性。此外,SAM在一系列分割任务上表现出了较强的零射击性能,进一步扩大了其适用性。尽管有上述优点,但将基于图像的SAM直接应用于视频分割会产生次优结果,因为帧之间的时间相干性没有考虑在内。此外,SAM不输出语义标签,文本提示不够高效,无法支持引用对象分割和其他需要语义级理解的高级任务。因此,SAM不适合强调跨帧对象相关性的视频分割任务,特别是语言引导的视频分割任务,从而限制了SAM在AR和自动驾驶等应用中的效用。考虑到SAM的优缺点,我们对SAM进行了重大修改,提出了SAM-Track,将其应用于视频分割领域。
4. 贡献
(1)我们提出了一个统一的视频分割框架SAM- track,将SAM应用并进一步扩展到视频分割中,而不是用SAM单独处理每帧。SAM-Track使用户能够在考虑时间相干性的情况下准确有效地跟踪和分割视频中的任何内容。
(2)通过结合SAM, DeAOT和Grounding-DINO, SAM- track支持两种跟踪模式:交互式模式,用于用户友好的多模态选择对象,将在整个视频中跟踪,以及自动模式,用于自动跟踪视频后续帧中出现的任何新对象。
(3)令人鼓舞的结果证明了我们提出的方法的卓越性能及其在实际应用中的巨大潜力。
二、模型结构
SAM-Track允许用户通过多模态交互方法或自动方法在视频中进行对象跟踪和分割。具体而言,SAM- track使用SAM交互式获取关键帧片段作为DeAOT的参考,这是一种高效的多目标跟踪模式,可提供与其他用于跟踪单个目标的VOS模型相当的多目标跟踪速度。然后,DeAOT传播参考帧来跟踪视频后续帧中的多个对象。为了增强SAMTrack的语言理解能力,我们将Grounding-DINO集成到系统中。利用Grounding-DINO强大的开集目标检测能力,SAM-Track可以通过自然语言交互选择视频中的目标进行跟踪和分割。
1. DeAOT
DeAOT是一种基于AOT的半监督视频目标分割VOS模型,该模型采用一种识别机制将同一高维嵌入空间中的多个目标关联起来,使其能够以与跟踪单个目标相同的速度跟踪多个目标。此外,DeAOT使用分层门控传播模块(GPM)将对象不可知和对象特定的嵌入从过去的帧分别传播到当前帧,以在深度传播层中保留对象不可知的视觉信息。
2.SAM
SAM通过专门设计的训练方法和大规模训练数据SA-1B,它不仅支持交互式分割方法,而且在广泛的分割任务上提供了出色的零射击性能。这两个关键特征显著增强了SAM的适用性,使其成为各种计算机视觉应用的有前途的解决方案。
3. Grounding-DINO
Grounding-DINO是一种开集对象检测器,它在多个阶段将语言集成到闭集检测器中。它具有良好的语言理解能力,能够完成引用对象检测任务。给定文本类别或目标对象的详细引用,它可以检测目标对象并返回每个目标的最小外部矩形。
4. 三种跟踪模式
SAM-Track统一视频分割框架如下图所示。交互式跟踪模式(Interactive Track Mode)仅在视频的第一帧中使用,以获取注释,而自动跟踪模式(AutomaticTracking Mode)则在之后的每n帧中调用一次。其中,
,
,
分别表示SAM标注结果、DeAOT跟踪结果、细化的DeAOT跟踪结果和细化的新目标掩码。需要注意的是,如果n大于视频帧数,则在跟踪过程中不会调用自动跟踪模式。我们将在4.1节中介绍交互式跟踪模式,在4.2节中介绍自动跟踪模式。最后,我们将在4.3节介绍融合跟踪模式,它可以同时和选择性地利用交互式和自动跟踪模式。
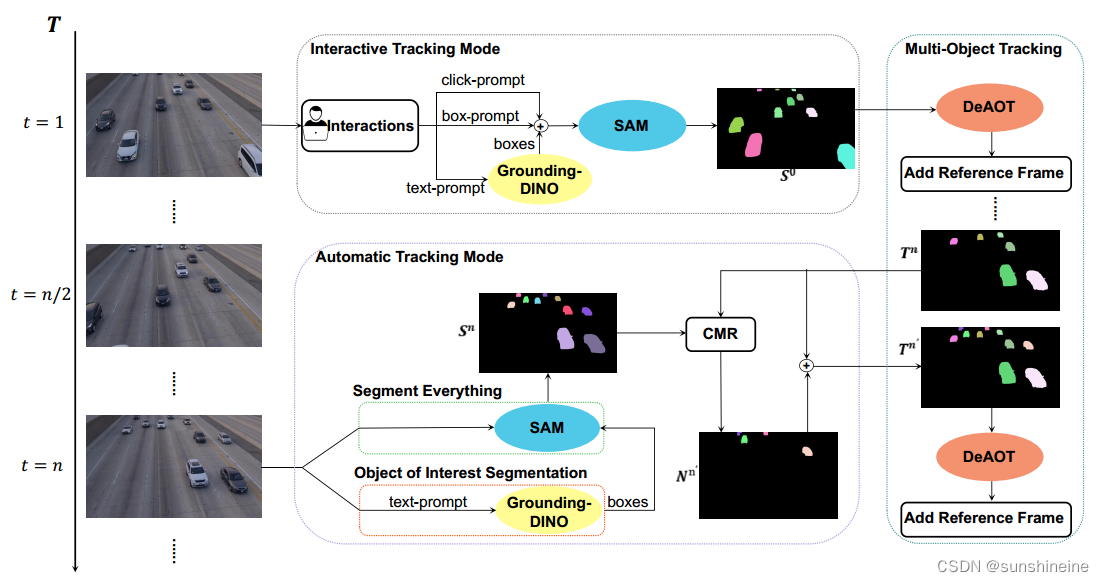
4.1 交互式跟踪模式
本小节将介绍SAM- track交互式跟踪模式的流程,以及它如何与Grounding-DINO、SAM、DeAOT集成进行目标检测、标注和跟踪的细节。
DeAOT在初始化时需要参考帧注释,这限制了其应用,因而利用SAM的高交互性分割方法,可以准确高效地获得任何视频的注释。具体地说,我们使用SAM的交互方法-点击和框-来分割参考框架中感兴趣的对象。然后,DeAOT将分割结果作为注释,使用门控传播模块(GPM)分层地将视觉嵌入和ID嵌入从过去的帧传播到当前帧用于逐帧跟踪对象。
但SAM也有一定的局限性,它没有提供足够的语义信息,并且文本提示可能无法有效地支持需要更细致地理解对象分割的任务,例如那些涉及语义级理解的任务。为了减轻这种限制,我们将Grounding-DINO集成到SAM-Track中作为侦听器。这种集成使SAM-Track能够利用Grounding-DINO强大的开放集对象检测功能,该功能允许使用自然语言命令在参考框架中交互式选择对象。特别地,Grounding-DINO将文本类别或不同对象的详细描述作为输入,并为每个目标输出最小的外部矩形。SAM随后利用这些矩形作为框提示来预测每个对象的掩码。然后,DeAOT使用生成的对象掩码来跟踪视频中的对象。结合Grounding-DINO、SAM和DeAOT, SAM- track支持多模态交互方式。
4.2 自动跟踪模式
本小节将介绍SAM-Track的自动跟踪模式,包括SAM-Track如何跟踪视频中出现的新对象以及新对象的定义。
由于缺少注释,交互式跟踪模式无法处理视频中出现的新感兴趣对象。为了跟踪视频中出现的新对象,我们提出了两种方法:分割一切(Segment Everything)和兴趣对象分割(Object of Interest Segmentation),以获得每n帧新对象的注释。
在分割一切方法中,我们使用SAM的Segment - Everything函数来获取关键参考帧中每个对象的对象掩码。然后,DeAOT根据合并的注释跟踪新出现的对象和原始对象。
在兴趣对象分割方法中,我们利用Grounding-DINO和SAM来获取视频中出现的新对象的注释。Grounding-DINO将根据预先确定的文本提示,即“人”和“车”,每n帧检测物体。然后,SAM和DeAOT将处理新对象的注释和跟踪, 定义新对象对于自动跟踪模式来说是一个棘手的问题,因为每个对象都有一个唯一的ID, DeAOT使用该ID来区分对象。如果我们直接给所有在关键帧中标注的对象分配新的ID,会导致跟踪过程中ID交换(跟踪不成功)。我们使用比较掩码结果(CMR)来确定新的对象。在CMR中,我们在每个关键帧中比较来自DeAOT的跟踪结果和来自SAM的注释结果,并从SAM注释中选择不被DeAOT跟踪的对象。通过使用CMR,我们可以显著减轻新检测到的对象影响已经跟踪的对象的ID跟踪的问题。
4.3 融合跟踪模式
SAM-Track是一个统一的视频分割框架,支持多种跟踪方法的组合。具体来说,SAM-Track中的每一种交互方法都可以与自动跟踪模式相结合。交互式跟踪模式获取视频第一帧的注释,自动跟踪模式跟踪视频中出现的在第一帧中未被选中的新对象。跟踪方法的不同组合扩展了SAM-Track的应用范围。
三、实验
1. 定量结果
为了证明SAM-Track的卓越性能,在两个流行的VOS基准(DAVIS-2016 Val和DAVIS-2017 Test)上进行了实验。结果如下表所示。值得注意的是,参考帧注释是通过鼠标点击获得的,这是SAM-Track的一种交互式注释方法。这凸显了SAM-Track交互注释生成的有效性和出色的鲁棒性。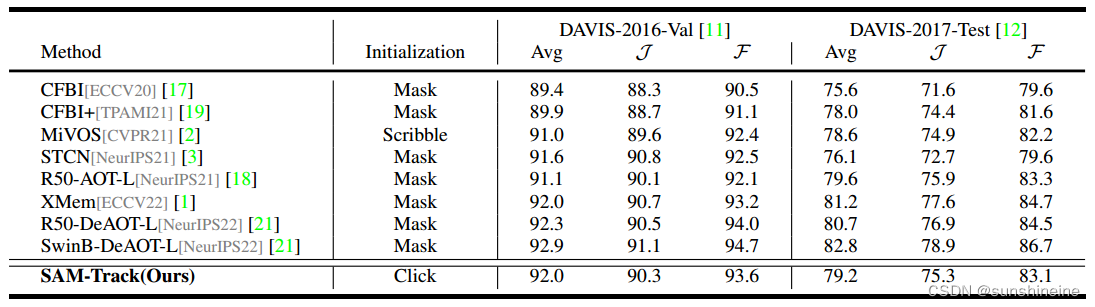
2. 定性结果
我们在下图中给出了SAM-Track在DAVIS-2016 Val和DAVIS-2017 Test视频上的定性结果,结果表明,即使在复杂的跟踪场景中,SAM-Track也能够有效地同时跟踪多个目标。
四、应用
SAM-Track作为一个统一的视频分割框架,提供了两种跟踪模式和多种交互方式,可以轻松满足不同领域的需求。此外,在SAM-Track中使用DeAOT作为跟踪模式,可以在复杂的应用场景中取得很好的效果。下图演示了SAM-Track在各种领域的应用,包括交互式跟踪、自动跟踪和融合跟踪模式。
1. 医学领域
在医学领域,许多细胞和器官的样本是稀缺的,很难训练一个特定的跟踪器来跟踪这些罕见的物体。然而,SAM-Track通过点击轻松跟踪零射击目标的能力使其非常有用。这使得SAM-Track可以在不需要专门培训的情况下处理这些对象的跟踪。
2. 智能城市
由于视频中不断有新车出现,VOS模型在智慧城市领域的应用具有挑战性。传统的VOS模型可能无法有效地处理这种情况。但是,SAM-Track提供了完全满足这些要求的自动跟踪模式。
3. 自主驾驶
自动驾驶的要求与智能城市类似,但它们也包括跟踪行人、宠物和其他精确物体的需求。这需要一个能够同时跟踪大量对象的VOS模型。SAM-Track具有跟踪众多物体的能力,使其成为自动驾驶领域应用的合适选择。
4. 运动分析
SAM-Track的自动跟踪模式可用于运动分析。文本提示“足球运动员”是预先设置的。此外,根据文本提示,SAM-Track还可以通过点击获得足球场的注释。然后,SAM-Track会持续跟踪视频中的足球运动员和足球场。


















 2205
2205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









