







 EdgeSAM是一种基于CNN的优化版本,针对智能手机优化,实现与原始SAM相当的性能,但速度提升40倍。文章介绍了EdgeSAM的设计、动态提示循环知识蒸馏方法,以及在边缘设备上的部署效果。
EdgeSAM是一种基于CNN的优化版本,针对智能手机优化,实现与原始SAM相当的性能,但速度提升40倍。文章介绍了EdgeSAM的设计、动态提示循环知识蒸馏方法,以及在边缘设备上的部署效果。
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2023年12月11日
论文:[2312.06660] EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM (arxiv.org) https://arxiv.org/abs/2312.06660代码:chongzhou96/EdgeSAM: Official PyTorch implementation of "EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM" (github.com)https://github.com/chongzhou96/EdgeSAM
https://arxiv.org/abs/2312.06660代码:chongzhou96/EdgeSAM: Official PyTorch implementation of "EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM" (github.com)https://github.com/chongzhou96/EdgeSAM
2. 摘要
EdgeSAM是SAM的加速变体,将原始的基于ViT的SAM图像编码器提炼成纯粹的基于CNN的架构,针对智能手机等边缘设备上的高效执行进行优化,以实现实时交互式分割,促进其在各种下游任务中的集成,并在性能上的妥协最小。
现有的蒸馏方案只涉及图像编码器,因此是任务不可知的,不能向学生模型揭示SAM的完整知识谱。因此,本文对各种蒸馏策略进行基准测试,提出了一种同时考虑SAM的编码器和解码器并提供特定任务监督信号的提示循环知识蒸馏方法,以便蒸馏模型能够准确捕获用户输入和掩码生成之间的复杂动态。为了减轻由点提示蒸馏产生的数据集偏差问题,在编码器中加入了一个轻量级模块。
在2080Ti上,相比SAM,EdgeSAM推理速度快40倍,在边缘设备上部署时速度提高了14倍,同时在COCO和LVIS上的mIoUs分别提高了2.3和3.2。这也是首款能够在iPhone 14上以超过30FPS的速度运行的SAM变体。
EdgeSAM仍然有几个研究方向可以提供潜在的提升,有待调查,包括量化,模型修剪,设备上优化,混合精度推理等。另外,在训练过程中没有使用任何增强技术,所以适当的数据或者及时的增强技术也可能是有希望的方向。
3. 前言
由于SAM计算量和内存消耗很大,很难实现在智能手机等边缘设备上部署。一个可行的解决方案是用一个更轻量化的版本取代SAM的巨大的基于vit的图像编码器来提高速度,例如MobileSAM,速度提高约26倍,但也大大降低了性能,且部署在边缘设备上时,速度远远不够实时,例如在iPhone 14上其吞吐量仅为每秒5张图像。为了减轻性能下降且达到实时,提出了EdgeSAM,它在iPhone 14上运行超过30 FPS,精度与原始SAM相当。
本研究方向主要是设计高效的CNN,变压器,以及它们的混合架构,目标是视觉表征学习。实验发现,基于CNN的架构比基于ViT的骨干网络更有利于实现最佳权衡。这归因于当前设备上的人工智能加速器,如苹果神经引擎(ANE),主要针对CNN而不是ViT架构进行了优化。采用高效模型作为图像编码器,但它与这些作品是正交的,因为它可以应用于各种高效的骨干。
知识蒸馏的大部分研究都集中在分类任务上。一些研究将知识蒸馏技术应用于语义分割和目标检测等密集预测任务。FastSAM使用SA-1B数据集训练基于 YOLACT的实例分割模型,并采用启发式规则进行后处理对象选择,这种方法与SAM原则大致一致。MobileSAM在SAM编码器和紧凑主干之间实现了像素级特征蒸馏,然而,它没有处理提示编码器和掩码解码器,导致与原始SAM相比有很大的性能差异。
EdgeSAM的关键是在知识提炼过程中考虑提示,以便学生模型接受特定于任务的指导,并专注于更困难的训练目标,例如更精细的边界。知识蒸馏的关键因素并不是专门为密集任务量身定制的损失或基于查询的检测器。更确切地说,在蒸馏过程中对提示进行战略性选择才是最重要的。为了解决这个问题,引入了动态提示循环策略。
二、EdgeSAM模型结构
EdgeSAM由编码器蒸馏、提示循环蒸馏和嵌入粒度首选项的轻量级模块组成。EdgeSAM的目标是将SAM的功能转换为更紧凑的模型,从而使部署在边缘设备上变得可行。首先在SAM和EdgeSAM的图像编码器的输出特征之间应用仅编码的知识蒸馏,然后采用提示循环蒸馏,从错误分割的区域中交互采样点提示,初始提示符也可以是一个框。如下图所示,EdgeSAM保留了SAM的编码器-解码器架构,旨在保留带有框和点提示的零镜头交互式分割的性能。仅使用SA-1B数据集1%的数据来训练EdgeSAM,并评估其在COCO和LVIS数据集上的零射击可移植性。
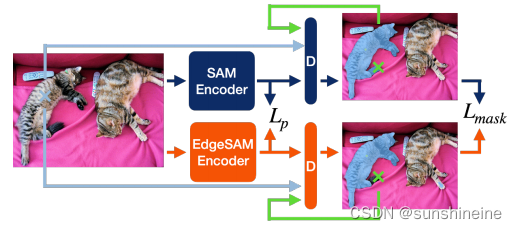
1. 编码器蒸馏
受MobileSAM启发,我们在SAM的图像编码器Tenc和高效网络Senc之间采用逐像素特征蒸馏损失Lp,由于学生模型和SAM图像编码器的下采样步幅和特征通道没有对齐,因此MobileSAM删除了学生模型最后两个阶段的下采样操作,并使用投影层来对齐通道维度。我们使用投影层进行通道对齐,但通过构建一个微小的FPN,该FPN将特征采样到所需的分辨率,并对先前阶段的特征执行元素相加,可以保持下采样层不变。
我们探索了遵循这种范式的各种高效骨干网络,包括基于ViT的、基于CNN的和混合网络。然而,我们发现始终存在相当大的性能差距。使用更长的训练时间或使用蒸馏损失进行密集预测任务的训练并没有显示出明显的改进。因此,我们进一步建议在蒸馏过程中考虑提示,以提供特定任务的指导。引入了动态提示循环策略。
2. 提示循环知识蒸馏
为了提高蒸馏过程的效率,我们引入了动态提示采样策略。该方法旨在实现三个关键目标:(1)从初始提示(无论是框还是点)动态生成一组不同的提示组合,(2)准确识别掩模中学生模型显示不准确的区域,从而将其重点引导到这些特定部分,(3)迫使教师模型(即SAM)生成高质量的掩模以进行更精确的指导。
具体过程如下:从一个初始提示开始,SA-1B数据集提供的框或点提示以相同的概率输入到教师和学生模型的解码器中。随后,我们确定了教师和学生的掩码预测出现分歧的区域。如下图所示,以老师的输出为参考,我们从FN/FP区域中随机抽取新的正/负点提示:在被标记为假阴性的区域出现正点,或者在被识别为假阳性的区域出现负点。然后将这些新采样的点与现有的提示合并,用于后续的解码迭代。需要
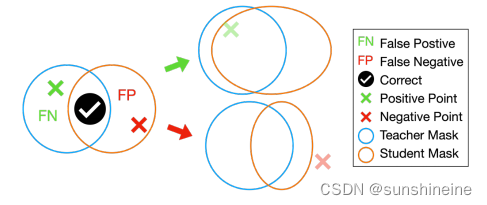
有效地使学生模型能够吸收复杂的知识边缘封装在SAM内,包括主动地将学生模型与SAM的多粒度输出掩码对齐,并在学生模型显示不准确的区域迭代地引入新的提示,这些定制的提示引导掩码解码器,强调不正确分割的区域,从而增强学习过程。还研究了各种训练配置,检查了不同类型的提示,冻结编码器/解码器组件的影响,以及蒸馏目标的选择。
3. 粒度先验
由于SA-1B是一个与类别无关的、多粒度的、自动标记的数据集,它的注释分布可能与那些由人工密集标记的数据集(如COCO)非常不同。因此,面对模糊提示(如单点)时,SAM很难确定所需的输出粒度。如下图所示,通过框提示,SAM可以很容易地确定目标粒度。此外,与反复点击或与方框交互相比,智能手机上的许多情况和应用更倾向于一次点击,比如点击-拖动。因此,我们提出了一个简单而有效的模块,该模块显式嵌入某些数据集的粒度先验,如果首选SAM的原始行为,则可以选择关闭该模块,旨在明确地识别和适应特定于给定测试集或应用程序场景的粒度先验。
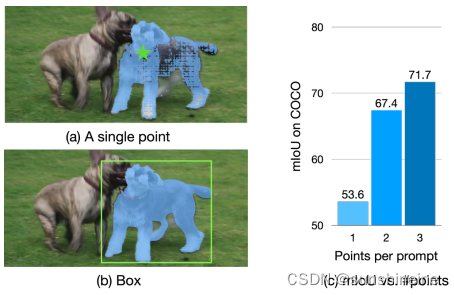
在图像编码器处于冻结状态的情况下,我们在其基础上构建轻量级区域建议网络(RPN),该网络由特征金字塔网络(FPN)和共享检测头组成。在效率方面,我们遵循了EfficientDet提出的设计。RPN在特定的数据集上进行训练,例如COCO,以提前捕获其粒度。在推理过程中,我们合并建议框,这些建议框的中心是点提示的K个最近邻居,它们的置信度分数加权。最后,我们将合并后的框与点输入组合在一起,作为输入到掩码解码器的提示符。
三、实验
1. 数据集
仅使用SA-1B数据集1%的数据来训练EdgeSAM,构建了一个名为SA-1K的测试集,特别地,从SA-1B中随机选择1000张图像,这些图像在训练中不使用。并评估其在COCO和LVIS数据集上的zero-shot可移植性。对于每个映像,随机采样64个实例以避免内存溢出。对于COCO和LVIS,使用它们的默认验证集。
2. 实现细节
把训练分为以下三个阶段:
第一阶段:对1% SA-1B图像仅使用编码器蒸馏损失Lp。训练模型10次,批大小设置为64。采用AdamW优化器,初始学习率设置为1.25e-2。采用余弦衰减调度,逐渐将学习率降低到6.25e-7。第二阶段:在相同的图像集上应用提示循环蒸馏,但使用点和框提示作为输入的一部分。加载在第一阶段训练的编码器权重,并从SAM继承解码器权重。然后,在1% SA-1B上用提示循环蒸馏损失Ld进行了5次训练。批大小为16,学习率从1e-4衰减到1e-5。设置允许的最大实例每个图像为16,提示采样的循环次数为1。在RPN训练的最后可选阶段,在COCO上遵循MMDetection的1x时间表。
第三阶段:这是可选的,我们冻结除轻量级RPN之外的模块,并使用具有常用focal loss和Huber loss的类别不可知的真实框进行训练。
3. 定量结果
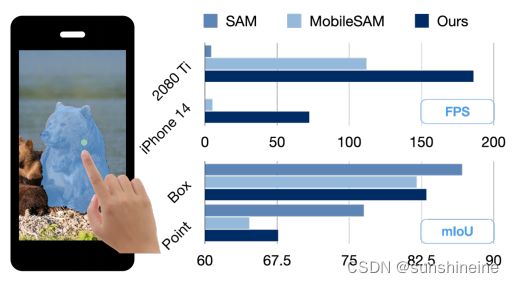
3.1 效率
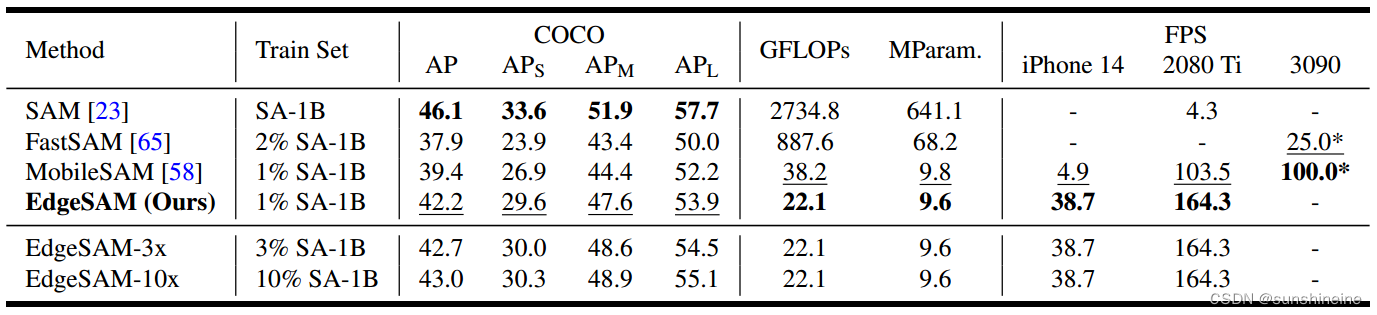
如下图所示,展示了EdgeSAM与SAM和MobileSAM的每秒吞吐量来比较衡量模型效率,以及在SA-1K数据集上使用框和点提示的mIoU性能。在单个NVIDIA 2080 Ti上EdgeSAM运行速度比SAM快40倍,比MobileSAM快1.6倍。在iPhone 14上,EdgeSAM每张图像仅为14毫秒,比MobileSAM快了14倍。
如下表所示,比较了SAM、FastSAM、MobileSAM和EdgeSAM在COCO数据集上测量平均精度(AP),EdgeSAM持续超过FastSAM和MobileSAM,但仍落后于原始SAM。GFLOPs按1024 × 1024的输入分辨率计算。比较了在桌面和移动平台上的编码器FPS,*表示复制自MobileSAM,EdgeSAM比SAM和MobileSAM明显快。3x和10x表示使用更多数据进行训练,训练数据越多,EdgeSAM性能越好,特别是对于大目标。
3.2 准确性
根据提示类型和来源将准确度测量分为三种场景, 对于(1)和(2),计算所有实例的mIoU,对于(3),报告mAP和边界IoU。对于所有求值,将第一个掩码token的输出作为预测:
(1)使用真实框作为初始提示,并迭代增加更多的点提示进行细化。
(2)使用真实掩码的中心点作为初始提示。
(3)使用外部对象检测器提供框提示。
EdgeSAM在SA-1B、COCO和LVIS数据集上的框提示性能与原始SAM非常相似,在这些数据集的点提示性能上比MobileSAM平均高出2 mAP和2-3 mIoU。
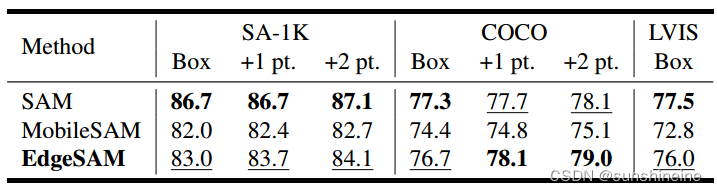
3.2.1 真实框提示
尽管非常轻量级,但EdgeSAM可以生成准确的分割掩码。如下表所示,报告了测试集中所有实例的mIoU,EdgeSAM在各种提示组合和数据集上始终优于MobileSAM,+1 pt.表示追加一个额外的细化点作为提示符,在COCO数据集上,使用一个或两个细化点,EdgeSAM甚超过了SAM。
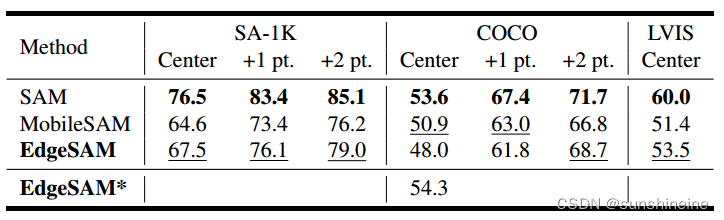
3.2.2 中心点提示
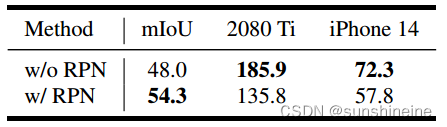
如下表所示,对于模棱两可的提示,例如单点,原始SAM并不总是产生所需粒度的掩码。此外,EdgeSAM是在SA-1B数据集上训练的,SA-1B数据集的粒度分布与COCO的粒度分布有很大的不同。因此,通过提出的任务感知蒸馏,EdgeSAM在处理模糊提示时比MobileSAM更有可能符合SAM粒度分布。为了显式地提前捕获这样的粒度,提出了一个轻量级RPN,使其在COCO数据集上的单点性能从48.0提高到54.3。
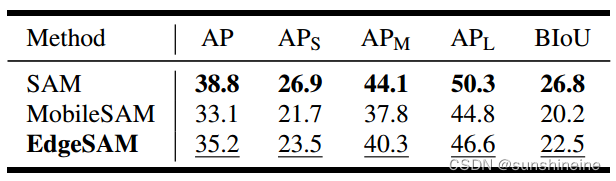
3.2.3 外部对象检测器提示
将所有SAM变体与外部目标检测器(使用来自MMDetection的Detic)结合起来,并评估它们在COCO上的mAP性能。还报告了边界IoU,以反映边界的准确性。如下表所示,虽然EdgeSAM的性能明显优于MobileSAM,但落后于SAM。这种性能差距可能不仅反映了模型能力的固有局限性,而且还反映了用真实框专门训练的结果,这可能导致推理过程中的差异。
4. 烧蚀研究
4.1 提示循环蒸馏prompt-KD
如下表所示,与仅使用编码器的知识蒸馏相比,prompt-KD在性能上有显著提高,尤其是在补充了额外的精化点之后。Prompt-KD的优势在于它提供了针对特定任务的监督,这比仅编码的KD提供的一般指导更明确、更有针对性。此外,它在不准确分割的区域动态生成新提示的策略更加关注这些区域,在此过程中创造了多样化的提示组合。

4.2 轻量级区域建议网络RPN
如下表所示,展示了粒度优先级的RPN的速度-性能权衡。在RPN的训练阶段冻结了其他组件,包括骨干网络,这种方法允许在推理期间动态停用RPN,确保模型的泛化能力保持不变。以中心点为提示符对COCO进行评价,还报告了在NVIDIA 2080 Ti和iPhone 14上的FPS。
4.3 主干的选择
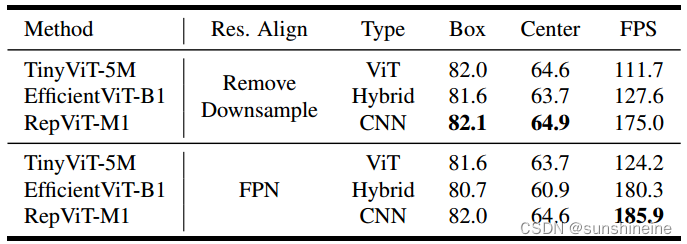
如下表所示,使用仅编码的KD进行消融,比较了基于ViT、基于CNN和混合设计的高效骨干网的性能-速度权衡,FPS是在单个NVIDIA 2080 Ti上测量的,不包括解码器。纯基于CNN的RepViT-M1采用FPN进行分辨率对准,达到最佳平衡。由于许多设备上的AI加速器(如ANE)都针对CNN进行了高度优化,因此部署在边缘设备上时,速度差距会变得更大。例如,在iPhone 14上,使用FPN进行分辨率校准,RepViT-M1编码1024×1024输入只需要14毫秒,分别比 TinyViT-5M和EfficientViT-B1快14倍和4倍。因此,我们的EdgeSAM采用RepViT-M1作为图像编码器。
4.4 训练数据集
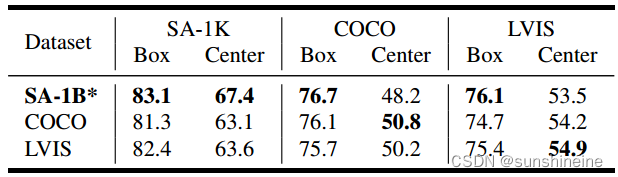
在默认设置中,使用SA-1B数据集的1%图像训练EdgeSAM。在表7a中,我们研究了训练数据集对可转移性的影响。具体来说,我们保持模型和训练管道相同,同时在1% SA-1B、COCO和LVIS之间切换训练数据集。请注意,所有数据集包含相似数量的图像(大约110K).
结果表明,使用SA-1B进行训练在使用框提示的所有测试集上的表现最好,而使用点提示时,在同一域中进行训练和测试的结果最好。
4.5 解码器的训练损失
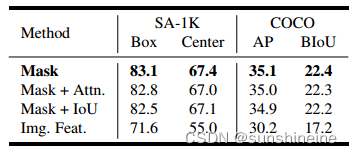
用教师掩码输出作为真实值来监督学生是对解码器损失最有效的方法。我们比较了各种配置,包括(1)将掩码损失与教师和学生解码器的注意力图对齐相结合;(2)将掩码损失与师生IoU预测相结合;(3)对齐师生解码器之间的输出特征映射。如下表所示,纯掩码损失监督的性能最好。因此,我们不再探索不同的损失组合,而是转向研究在蒸馏过程中选择适当提示的策略,并进一步提出提示在环蒸馏。
4.6 提示数
考虑到SA-1B的每个样本包含大约100个实例,在单个批处理中训练所有这些实例会导致VRAM溢出。因此,对每个迭代随机抽取一个子集。在这次消融中,我们冻结了EdgeSAM的掩码解码器。在下表中,我们研究了采样提示数量的影响,发现16个提示达到了最佳权衡。因此,我们将其设置为默认值。
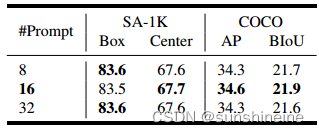
4.7 其他替代品
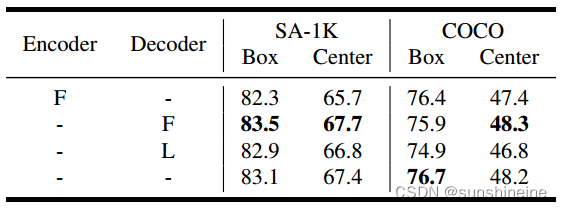
如下表所示,我们测试了模块冻结和LoRA的几种配置。特别地,将LoRA应用于解码器中注意块的查询层和值投影层。结果表明,在蒸馏过程中冻结解码器可以获得最佳的域内精度,而微调所有模块可以更好地推广到其他数据集。为了获得更实用的设置,我们选择对编码器和解码器进行微调。此外,我们在蒸馏过程中改变提示采样循环的数量。
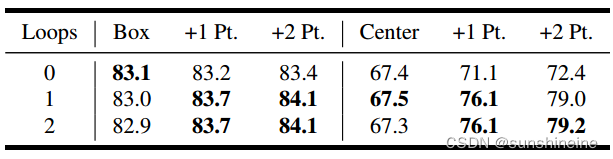
如下表所示,发现一个额外的循环就足够了,因此将循环数默认设置为1。
如下表所示,由于最优仅编码蒸馏和提示循环蒸馏的优化设置不同,发现联合训练与两个阶段的训练相比产生了次优结果。因此,我们建议对它们进行顺序训练。

如下表所示,我们探索了几种提高纯编码器蒸馏性能的方法,包括为更长的时间表进行训练和应用为密集预测任务设计的知识蒸馏损失。提高了点提示的性能,但框提示的性能略有下降,这表明仅编码蒸馏的性能上限。

5. 可视化结果
本文实现了在设备上的一个演示应用程序,如下两图所示,展示了EdgeSAM和SAM在点、框和一切模式下的可视化结果,绿星和红星分别表示正负点,其中没有一张图像来自EdgeSAM训练的SA-1B数据集,证明了泛化能力。EdgeSAM的整体掩码质量不如SAM,但它们是可以比较的,特别是对于框提示。EdgeSAM的一个常见失败案例是错误分割对象内的孔,例如2图中的甜甜圈,这可能是由于缺乏训练样本,但在实际使用中,可以在孔区域中添加一个负值,以明确地强制EdgeSAM排除这些区域。此外,在一切模式下,只有信心得分超过一定阈值的掩码才会被保留。



















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









