







1. Auto SAM(Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation)
1.1 面临问题
医学背景:
(1)与自然图像相比,医学图像的尺寸更小,形状不规则,对比度更低。(注意力模块)
(2)2D变3D对硬件的要求高。(Spatial Adapter)
SAM自身:
(1)SAM对劳动密集型手动生成提示的依赖。(APG自动提示生成器)
(2)解决SAM在3D医学图像分割任务上表现出低于标准的性能。
(3)强大的GPU服务器施加的大量计算负担。(Knowledge Distillation)
1.2 应用技术
(1)在输入级为图像编码器设计了复杂的修改,使原始的2D Transformer能够熟练地适应体积输入。
(2)同时使用参数高效的微调方法优化预训练权重的可重用性。我们将所有三个维度都视为各向同性,并直接调整经过训练的Transformer块来捕获3D图案。
(3)在提示编码器级别,设计了一个自动提示生成器(APG)模块,该模块将从先前的图像编码器中提取的特征图作为输入,并自动学习以下掩码编码器所需的提示。该设计有效地消除了耗时的手动提示生成过程,特别是对于多器官医学图像分割任务。
(4)优先考虑在输出级的掩码解码器的轻量级设计,强调多层聚合。采用知识蒸馏来促进学习从AutoSAM Adapter转移到更小、资源高效的模型,弥合复杂模型和实际医学成像需求之间的差距,使其更适合于移动设备和实时应用场景。
1.3 模型结构
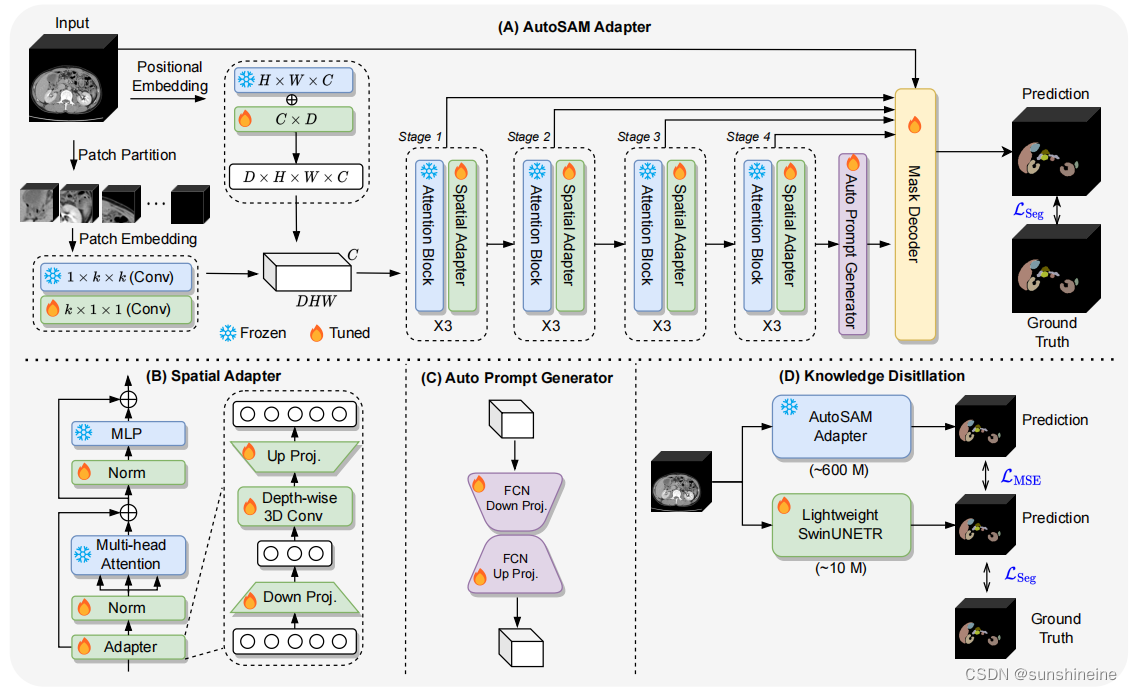
(A) AutoSAM Adapter
输入3D医学图像,通过Patch Partition模块,该模块将3D图像分割成小块(patch)生成patch Embedding,通过1xkxk的卷积核有效地提取3D图像中的局部特征,再通过k x 1 x 1卷积在不改变空间维度的情况下调整特征的通道数,整合通道间的信息。例如,它可以用于降维,减少模型的参数数量和计算量,或者用于升维,增加模型的表征能力。Positional Embedding为模型提供输入数据中每个点的空间位置信息。将经过两次卷积后的patch Embedding与Positional Embedding相结合生成3D数据。将3D数据经过多次Attention Block 注意力机制模块(使模型动态地关注图像中的关键区域,整合图像的全局上下文信息,以灵活的方式处理不同大小和形状的图像块。)和Spatial Adapter 空间适配器(确保模型能够有效地处理3D数据,捕捉到深度方向上的细节和模式)生成特征图。从图像编码器提取的特征图输入到Auto Prompt Generator自动提示生成器(APG)模块中生成提示,减少了手动生成提示的需要,提高了效率。将图像编码器每个阶段生成的特征图和APG生成的提示输入到掩码解码器Mask Decoder中,生成最终的分割掩码,预测每个像素的类别。
(B)Spatial Adapter
空间适配器专门设计来处理3D空间数据,能够捕捉和提取图像中的深度和空间特征。 通过空间适配器,模型能够学习到更细粒度的局部特征,这种设计还有助于模型在有限的计算资源下运行,使其适用于移动设备和实时应用场景。
通过Depth-wise 3D Conv(沿着图像深度方向的3D卷积),用于提取3D空间特征,通过Up Proj., Down Proj.调整特征图的维度,将特征图传入到Norm归一化层调整和稳定特征的分布。Multi-head Attention多头注意力机制捕捉更丰富的上下文信息,MLP (多层感知器)用于从提取的特征中学习更高层次的表示。
(C)Auto Prompt Generator
APG自动提示生成器自动生成用于指导图像分割过程的提示。APG接收来自图像编码器的特征图作为输入,然后通过内部网络结构(FCN)处理这些特征图,以生成用于分割的提示。FCN通过使用卷积层替代传统卷积神经网络(CNN)中最后一层全连接层(Fully Connected Layer)。通过自动化这一过程,减少了手动干预,提高了效率。
(D)Knowledge Distillation
在AutoSAM Adapter中,知识蒸馏用于将从大型AutoSAM Adapter模型(约600M参数)中学到的知识转移到更小的SwinUNETR模型(如小型版本约15.7M参数或微型版本约4.0M参数)。均方误差损失 用于衡量学生模型的预测与教师模型的预测之间的差异,
用于训练AutoSAM Adapter模型的损失函数,它结合了
和交叉熵损失
,用于评估模型预测的分割掩码与真实掩码之间的一致性。
衡量预测分割掩码和真实分割掩码之间的重叠程度。
衡量预测概率分布和真实标签之间的差异。
2. Group-Mix SAM(Group-Mix SAM: Lightweight Solution for Industrial Assembly Line Applications)
2.1 面临问题
(1)SAM在实际装配线场景中的部署尚未实现,因为其大型图像编码器的大小高达632 M,在实际部署中使用SAM执行分段任务会导致无法承受的计算和内存成本。
(2)在实际的装配线上,负责运行算法的是边缘计算机。这些边缘计算机的购买通常受到价格的限制,因此存在内存低和计算能力弱等问题。
2.2 应用技术
(1)Groupmixformer:提出了群体混合注意力(GMA)作为传统自注意力的高级替代方案,分组计算混合注意力权重。
(2)知识蒸馏: 知识蒸馏(Knowledge Distillation)是一种模型压缩技术,用小型的学生模型(student model)学习模仿大型的教师模型(teacher model)的行为,提高小型模型的性能,使其在推理时的性能更接近于大型模型。 学生模型不仅学习模仿教师模型的输出(即预测类别的概率分布),还可能学习模仿其中间层的表示(特征图)。这通常通过比较学生和教师模型在不同层次上的输出来实现。直接用小型图像编码器训练,费时费力,效果也不一定好。
2.3 模型结构
Group-Mix SAM用一种更小的图像编码器结构Groupmixformer替换MobileSAM编码器中的原始ViT-Tiny结构。MobileSAM中的解耦蒸馏是直接从原始SAM的ViT-H中提取小型图像编码器,而不依赖于组合解码器,与半耦合(冻结掩码解码器并从掩码层优化图像编码器)和耦合蒸馏(直接从掩码层优化图像编码器)相比,解耦蒸馏在时间和效率方面都优于上述。因此,Group-Mix SAM依然用解耦蒸馏方法将基于ViT-Tiny的MobileSAM知识转移到具有较小图像编码器的Groupmixformer。与MobileSAM相比,参数减少了37.63%(2.16 M),浮点运算减少了42.5%(15614.7 M)。
3. STLM:A SAM-guided Two-stream Lightweight Model for Anomaly Detection
3.1 面临问题
(1)模型效率:在实际应用中,尤其是在资源受限的环境下,模型需要有较高的效率,能够实时处理数据并快速给出检测结果,即需要较少的计算资源和时间,模型的复杂性和内存占用也是一个重要考虑因素。
(2)移动友好性:随着移动设备的普及,模型需要能够在这些设备上运行,这要求模型必须足够轻量,以适应移动设备的计算能力和能耗限制。
(3)数据稀少:在实际的工业应用中,正常样本通常容易获得,而异常样本可能较为稀少,导致数据集不平衡。且异常可能包括从微小的变化到大的缺陷,具有多样性。
3.2 应用技术
(1)双流轻量级模块:采用了由SAM知识指导的两个轻量级的图像编码器,一个流被训练成在正常和异常区域生成判别和通用的特征表示,而另一个流在没有异常的情况下重建相同的图像。
(2)共享掩码解码器:采用共享掩码解码器和特征聚合模块来生成异常映射。
3.3 模型结构
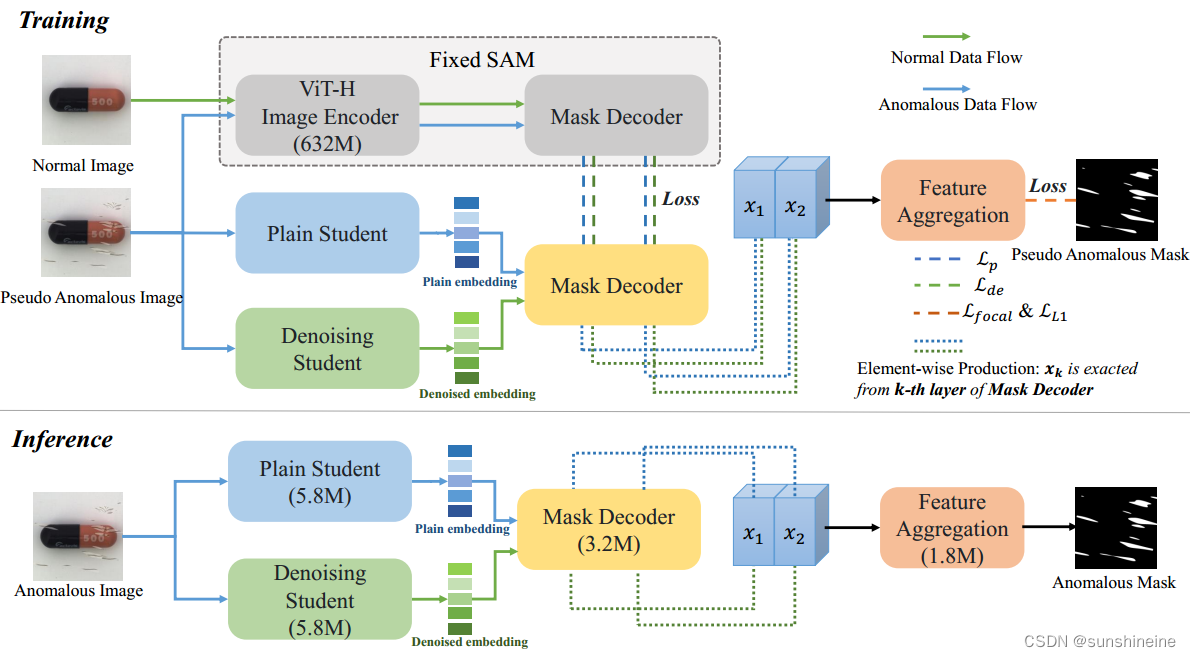
训练阶段:首先输入正常图像和由数据增强技术生成的伪异常图像,使用知识蒸馏技术从SAM的图像编码器中提取知识,转移到Two-stream Lightweight Model (TLM)双流轻量级模块中,TLM模型采用了ViT-Tiny作为图像编码器的骨干网络,分别包括Plain Student和Denoising Student两个图像编码器,Plain Student 被训练用来生成正常和异常区域的有区分性和泛化的特征表示,生成直接嵌入;Denoising Student 被训练用来重建没有异常的图像特征,从而增强两路特征表示在面对异常区域时的差异性,生成异常嵌入。将两种嵌入传送到一个共享的掩码解码器,用于从学生网络生成的特征中提取信息,生成异常掩码。将两路学生网络的特征传送到Feature Aggregation (FA) Module,该模块由两个残差块和一个空洞空间金字塔池化模块组成,通过特征聚合模块融合特征,生成异常图,以提高异常检测的准确性。
推理阶段:训练阶段训练TLM和FA模块。在推理阶段,丢弃固定的SAM教师网络,只使用TLM和FA模块生成像素级异常分割图和图像级异常分数。


















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









