







1. 概述
cat /proc/cpuinfo:查看CPU信息;
cat /proc/loadavg:查看cpu最近1/5/15分钟的平均负载:
计算CPU负载,可以让调度器更好的进行负载均衡处理,以便提高系统的运行效率。此外,内核中的其他子系统也可以参考这些CPU负载值来进行相应的调整,比如DVFS等。
目前内核中,有以下几种方式来跟踪CPU负载:
1.全局CPU平均负载;
2.运行队列CPU负载;
3.PELT(per entity load tracking);
这也是本文需要探讨的内容,开始吧。
2. 全局CPU平均负载
2.1 基础概念
先来明确两个与CPU负载计算相关的概念:
1.active task(活动任务):
只有知道活动任务数量,才能计算CPU负载,
而活动任务包括了TASK_RUNNING和TASK_UNINTERRUPTIBLE两类任务。
包含TASK_UNINTERRUPTIBLE任务的原因是,这类任务经常是在等待I/O请求,将其包含在内也合理;
2.NO_HZ
我们都知道Linux内核每隔固定时间发出timer interrupt,
而HZ是用来定义1秒中的timer interrupts次数,
HZ的倒数是tick,是系统的节拍器,每个tick会处理包括调度器、时间管理、定时器等事务。
周期性的时钟中断带来的问题是,不管CPU空闲或繁忙都会触发,会带来额外的系统损耗,因此引入了NO_HZ模式,可以在CPU空闲时将周期性时钟关掉。
在NO_HZ期间,活动任务数量的改变也需要考虑,而它的计算不如周期性时钟模式下直观。
2.2 流程
Linux内核中定义了三个全局变量值avenrun[3],用于存放最近1/5/15分钟的平均CPU负载。
看一下计算流程:

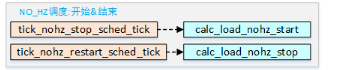
计算活动任务数,这个包括两部分:1)周期性调度中新增加的活动任务;2)在NO_HZ期间增加的活动任务数;
根据活动任务数值,再结合全局变量值avenrun[]中的old value,来计算新的CPU负载值,并最终替换掉avenrun[]中的值;
系统默认每隔5秒钟会计算一次负载
如果由于NO_HZ空闲而错过了下一个CPU负载的计算周期,则需要再次进行更新。
比如NO_HZ空闲20秒而无法更新CPU负载,前5秒负载已经更新,需要计算剩余的3个计算周期的负载来继续更新;
2.3 计算方法
Linux内核中,采用11位精度的定点化计算,CPU负载1.0由整数2048表示,宏定义如下:
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
计算公式如下:
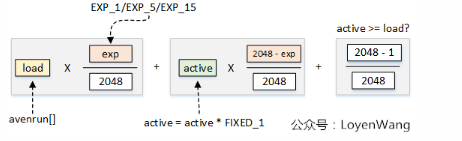
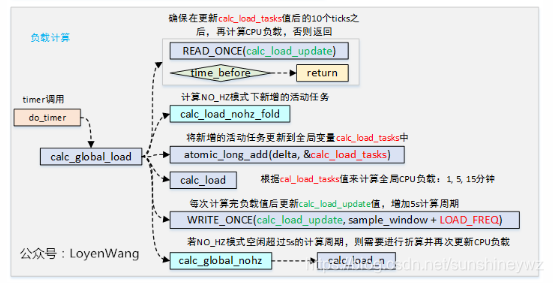
1.load值为旧的CPU负载值avenrun[],整个计算完成后得到新的负载值,再更新avenrun[];
2.EXP_1/EXP_5/EXP_15,分别代表最近1/5/15分钟的定点化值的指数因子;
3.active值,根据读取calc_load_tasks的值来判断,大于0则乘以FIXED_1(2048)传入;
4.根据active和load值的大小关系来决定是否需要加1,类似于四舍五入的机制;
关键代码如下:
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
NO_HZ模式下活动任务数量更改的计算
由于NO_HZ空闲效应而更改的CPU活动任务数量,存放在全局变量calc_load_nohz[2]中,
并且每5秒计算周期交替更换一次存储位置(calc_load_read_idx/calc_load_write_idx),其他程序可以去读取最近5秒内的活动任务变化的增量值。
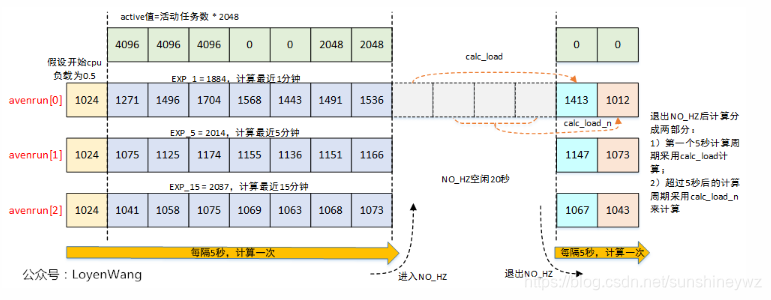
计算示例
假设在某个CPU上,开始计算时load=0.5,根据calc_load_tasks值获取不同的active,中间进入NO_HZ模式空闲了20秒,整个计算的值如下图:
3. 运行队列CPU负载
Linux系统会计算每个tick的平均CPU负载,并将其存储在运行队列中rq->cpu_load[5],用于负载均衡;
下图显示了计算运行队列的CPU负载的处理流程:
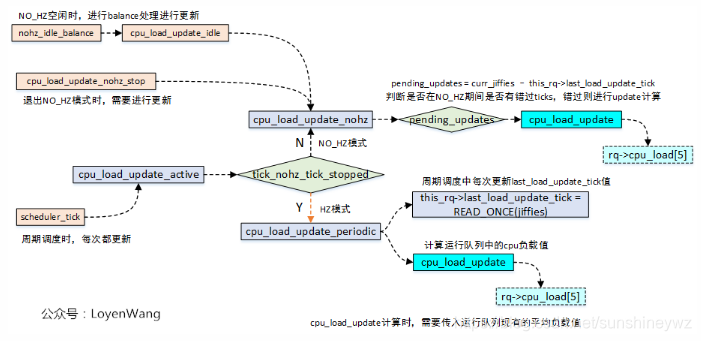
最终通过cpu_load_update来计算,逻辑如下:
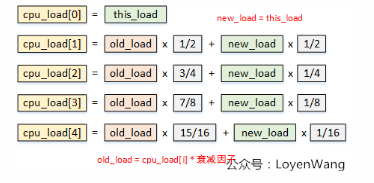
其中传入的this_load值,为运行队列现有的平均负载值。
上图中的衰减因子,是在NO_HZ模式下去进行计算的。在没有使用tick时,从预先计算的表中计算负载值。Linux内核中定义了两个全局变量:
#define DEGRADE_SHIFT 7
static const u8 degrade_zero_ticks[CPU_LOAD_IDX_MAX] = {0, 8, 32, 64, 128};
static const u8 degrade_factor[CPU_LOAD_IDX_MAX][DEGRADE_SHIFT + 1] = {
{ 0, 0, 0, 0, 0, 0, 0, 0 },
{ 64, 32, 8, 0, 0, 0, 0, 0 },
{ 96, 72, 40, 12, 1, 0, 0, 0 },
{ 112, 98, 75, 43, 15, 1, 0, 0 },
{ 120, 112, 98, 76, 45, 16, 2, 0 }
};
Linux中使用struct sched_avg来记录调度实体和CFS运行队列的负载信息,因此struct sched_entity和struct cfs_rq结构体中,都包含了struct sched_avg,字段介绍如下:
struct sched_avg {
u64 last_update_time; //上一次负载更新的时间,主要用于计算时间差;
u64 load_sum; //可运行时间带来的负载贡献总和,包括等待调度时间和正在运行时间;
u32 util_sum; //正在运行时间带来的负载贡献总和;
u32 period_contrib; //上一次负载更新时,对1024求余的值;
unsigned long load_avg; //可运行时间的平均负载贡献;
unsigned long util_avg; //正在运行时间的平均负载贡献;
};
4. PELT
PELT计算的发生时机如下图所示:
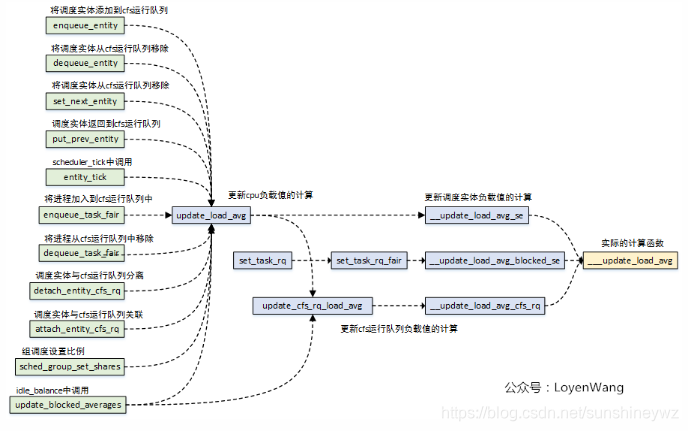
调度实体的相关操作,包括入列出列操作,都会进行负载贡献的计算;















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









