







转自:http://www.kuqin.com/shuoit/20150213/344838.html
背景
本文不打算从源码分析的角度看standalone如何实现,甚至有的模块和类在分析中都是忽略掉的。
本文目的是透过spark的standalone模式,看类似spark这种执行模式的系统,在设计和考虑与下次资源管理系统对接的时候,有什么值得参考和同通用的地方,比如说接口和类体系,比如说各个执行层次的划分:面向资源的部分 vs 面向摆放的部分;面向资源里面进程的部分 vs 线程的部分等。对这些部分谈谈体会。
执行流程
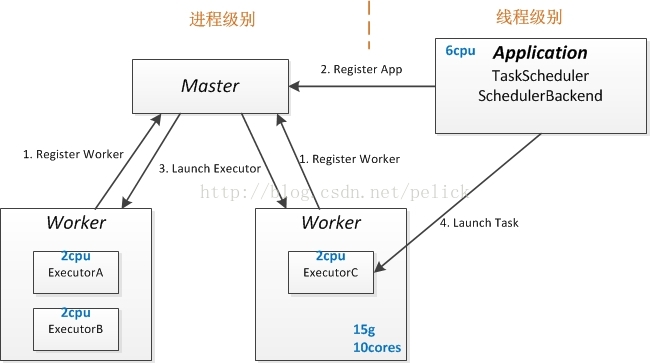
解释standalone执行原理可以抛开Driver和Client。
首先,简单说明下Master、Worker、App三种角色。
Application:带有自己需要的mem和cpu资源量,会在master里排队,最后被分发到worker上执行。app的启动是去各个worker遍历,获取可用的cpu,然后去各个worker launch executor。
Worker:每台slave起一个,默认或被设置cpu和mem数,并在内存里做加减维护资源剩余量。Worker同时负责拉起本地的executor backend,即执行进程。
Master:接受Worker、app的注册,为app执行资源分配。Master和Worker本质上都是一个带Actor的进程。
接下来分析下图中的四个步骤。
第一步,register worker是一个启动集群和搜集初始资源的过程。在standalone模式下,预先在机器上使用脚本start master和slave。在这个过程中,worker的启动cpu和内存是设置好的,起来后把自己注册给master,从而master维护worker上的资源量和worker本身host、port等的信息。master的HA抛开不谈。
第二步,master接收新app的注册。app也好,driver也好,都是通过输入一个spark url提交的,最终在master内存里排队。当master有新的app进来,或资源可用性发生变化时,会触发资源分配的逻辑:
首先,将可用的alive workers进行洗牌打乱,遍历等待的drivers,为每个driver轮询遍历alive workers,只要worker的剩余mem和cpu满足该driver,那么就向那个worker通过actor sender发送一个LaunchDriver的消息,里面会包含driver的信息。
接着,遍历所有的waiting apps,同样为每个app遍历可用的worker,为其分配cpu。默认是spread out的策略,即一个app的cpus可以分布在不同的worker上。app会添加自己的executor,然后向Worker的actor传递LaunchExecutor的消息,并传递给这个app的driver一个ExecutorAdded的消息。
第三步,launch executor是一个重点。master在资源分配的逻辑里,为app分配了落在若干worker上的executors,然后对于每一个executor,master都会通知其worker去启动。standalone模式下,每个worker通过command命令行的方式启动CoarseGrainedExecutorBackend。CoarseGrainedExecutorBackend本质上也是一个Actor,里面最重要的是有一个线程池,可以执行真正的task。所以CoarseGrainedExecutorBackend具备了launchTask,killTask等方法,其TaskRunner的run()方法,调用的就是ShuffleMapTask或ResultTask的run()逻辑。
第四步,app自己来launch task。上面三步都是集群资源的准备过程,在这个过程里,app得到了属于自己的资源,包括cpu、内存、起起来的进程及其分布。在我看来,前三个过程是面向资源的调度过程,接在mesos、yarn上也可以,而第四个过程则是面向摆放的。App内的TaskScheduler和SchedulerBackend是我们熟悉的与task切分、task分配、task管理相关的内容。在之前spark任务调度的文章里也啰啰嗦嗦讲了一些。
模型分层
spark在这一块的设计是优秀的。图中,app内的SchedulerBackend是可以针对不同资源管理系统实现的,包括没有画出来的ExecutorBackend。这俩兄弟是典型的面向资源的层次上的抽象。另一方面,app内的TaskScheduler是与Task的分配和执行、管理相关的,这部分与下层面向资源的部分是隔离开的,所谓是面向摆放的。
换句话说,SchedulerBackend在1,2,3步之后,已经从集群里,获得了本身app的executors资源。通过它,TaskScheduler可以根据自己的策略,把Task与Executor对应起来,启动起来,管理起来。原本,TaskScheduler是个逻辑上的任务调度者,加上SchedulerBackend之后,其具备了操纵实际物理资源的能力,当然主要指的就是task locality与task在进程上的start和kill。
我对standalone的感受是,spark的资源索取和执行,其实是偏向于一个在线系统的。spark要跑一个app之前,也是先申请好资源量的,且资源都保证的情况下,app会一下被分配到所有资源,并得到了使用这些资源的能力。无论是mesos上还是yarn上,实现上无非主要是SchedulerBackend和Executor相关类的区别,上层逻辑上的任务调度,即TaskScheduler是不变的。
今天,我对于standalone的重看和理解,最受益的就是在线系统与资源管理衔接上的分层理解。其实资源管理系统很容易从双层,三层,划分到逻辑上四、五层。至少,我看spark在这件事情上的设计还是很清晰,有借鉴意义的。甚至standalone这套东西,也是可以单独拎出来支持其他系统的。















 4732
4732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









