







文章目录
最小二乘估计与最大似然估计
最小二乘估计
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
在机器学习中:
假设函数为:
h
θ
h_θ
hθ
(
x
)
(x)
(x) =
θ
0
θ_0
θ0 +
θ
1
x
θ_1 x
θ1x
损失函数为:

在上边的公式中,运用最小二乘法,要求损失函数得到的结果最小,即得到最优的
θ
0
θ_0
θ0,
θ
1
θ_1
θ1。
最大似然估计
最大似然估计认为,我们多次观察到的结果就是最可能发生的结果,也就是让我们的观察样本概率最大的参数就是整体分布的参数。
说的通俗一点,最大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
最大似然估计:现在已经拿到了很多个样本(你的数据集中所有因变量),这些样本值已经实现,最大似然估计就是去找到那个(组)参数估计值,使得前面已经实现的样本值发生概率最大。因为你手头上的样本已经实现了,其发生概率最大才符合逻辑。这时是求样本所有观测的联合概率最大化,是个连乘积,只要取对数,就变成了线性加和。此时通过对参数求导数,并令一阶导数为零,就可以通过解方程(组),得到最大似然估计值。
例如:一个麻袋里有白球与黑球,但是我不知道它们之间的比例,那我就有放回的抽取10次,结果我发现我抽到了8次黑球2次白球,我要求最有可能的黑白球之间的比例时,就采取最大似然估计法: 我假设我抽到黑球的概率为p,那得出8次黑球2次白球这个结果的概率为: P ( 黑 = 8 ) P(黑=8) P(黑=8)= p 8 p^8 p8 * ( 1 − p ) 2 (1-p)^2 (1−p)2,现在我想要得出p是多少,很简单,使得P(黑=8)最大的p就是我要求的结果,接下来求导的的过程就是求极值的过程。
二者关系
从概率论的角度:
a、最小二乘(Least Square)的解析解可以用Gaussian分布以及最大似然估计求得
b、Ridge回归可以用Gaussian分布和最大后验估计解释
c、LASSO回归可以用Lapace分布和最大后验估计解释
最小二乘法以估计值与观测值的差的平方和作为损失函数,极大似然法则是以最大化目标值的似然概率函数为目标函数,从概率统计的角度处理线性回归并在似然概率函数为高斯函数的假设下同最小二乘建立了的联系。
极大似然估计是根据数据估计模型参数的一种方法,这种方法的原理就是如何确定模型参数最有可能得到当前事件,当数据误差项服从标准正态分布时,其结果和最小二乘法一致
最大后验与最大似然估计
最大后验概率估计(MAP)
-她是贝叶斯派模型参数估计的常用方法。
-顾名思义:就是最大化在给定数据样本的情况下模型参数的后验概率
-她依然是根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例(万一数据量少或者数据不靠谱呢)。
-在这里举个掷硬币的例子:抛一枚硬币10次,有10次正面朝上,0次反面朝上。问正面朝上的概率p。
在频率学派来看,利用极大似然估计可以得到 p= 10 / 10 = 1.0。显然当缺乏数据时MLE可能会产生严重的偏差。
如果我们利用极大后验概率估计来看这件事,先验认为大概率下这个硬币是均匀的 (例如最大值取在0.5处的Beta分布),那么P(p|X),是一个分布,最大值会介于0.5~1之间,而不是武断的给出p= 1。
显然,随着数据量的增加,参数分布会更倾向于向数据靠拢,先验假设的影响会越来越小。
误差度量
例如我们希望用算法来预测癌症是否是恶性的,在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有0.5%。然而我们通过训练而得到的神经网络算法却有1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。

我们将算法预测的结果分成四种情况:
- 真阳性(True Positive,TP):预测为真,实际为真
- 真阴性(True Negative,TN):预测为假,实际为假
- 假阳性(False Positive,FP):预测为真,实际为假
- 假阴性(False Negative,FN):预测为假,实际为真

准确率(Accuracy)
准确率(Acc)= 真 阳 性 + 真 阴 性 t o t a l ( 真 阳 性 + 假 阳 性 + 真 阴 性 + 假 阴 性 ) \frac{真阳性 + 真阴性}{total(真阳性 + 假阳性 + 真阴性 + 假阴性)} total(真阳性+假阳性+真阴性+假阴性)真阳性+真阴性
也就是预测正确的结果比上所有的结果就是算法预测的准确率
精确率(Precision)
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)
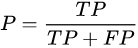
召回率(Recall)
而召回率是针对我们原来的正样本而言的,它表示的是正例样本中有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
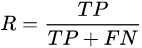
用一个 F 1 F_1 F1值来综合评估精确率和召回率,它是精确率和召回率的调和均值。当精确率和召回率都高时, F 1 F_1 F1值也会很高
2
F
1
\frac{2}{F_1}
F12 =
1
P
\frac{1}{P}
P1 +
1
R
\frac{1}{R}
R1
有时候我们对精确率和召回率并不是一视同仁,我们用一个参数β来度量两者之间关系。
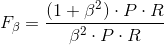
当
β
=
1
β=1
β=1时
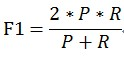
总结:
- 如果 β > 1 β>1 β>1,召回率有更大影响;
- 如果 β < 1 β<1 β<1,精确率有更大影响;
- 如果 β = 1 β=1 β=1,影响力相同,和 F 1 F_1 F1形式一样;
灵敏度和特异度
灵敏度(真阳率,召回率)识别的正例占所有实际正例的比例。
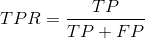
特异度(假阳率)识别的假阳率占所有实际负例的比例。
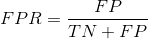
ROC曲线
ROC曲线(receiver operating characteristic curve,简称ROC曲线),以TPR为y轴,以FPR为x轴,我们就直接得到了RoC曲线。从FPR和TPR的定义可以理解,TPR越高,FPR越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。

PR曲线
以精确率(precision)为y轴,以召回率(recall)为x轴,我们就得到了PR曲线。精准率和召回率是互相影响的,理想情况下肯定是希望做到两者都高,这样我们的模型和算法就越高效。但是一般情况下准确率高、召回率就低,召回率低、准确率高。
如果一个分类器的性能比较好,会让Recall值增长的同时保持Precision的值在一个很高的水平;而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡
















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









