









作者:yyy
目录
一、场景介绍
大数据时代来临,人们对于空间大数据处理的自动化与性能需求也越来越迫切。为此,SuperMap提供了处理自动化服务,通过处理自动化工具(以下简称工具)构建处理自动化模型(以下简称模型)并运行,可实现空间数据处理与分析过程的自动化。除此之外,也可以通过使用自定义工具构建模型进行空间数据处理与分析。
二、操作使用
SuperMap iServer内置了处理建模器,用于可视化构建处理自动化模型。通过建模器您可以:
- 可视化拖拽和连接工具,构建符合您工作需求的模型。
- 分步运行模型,运行至您所选的工具,以检验处理自动化流程的正确性。
- 运行整个模型实现空间数据的自动化处理与分析流程。
处理建模器页面地址可通过处理自动化服务管理的基本信息页面进行查看,如图,您可通过该链接进入处理建模器页面:

处理建模器页面界面如下:

图 处理建模器页面
处理建模器页面的左侧为处理自动化工具列表,中间为可视化建模画布,右侧为参数设置与输出窗口。

图 功能按钮
通过页面上方的文件下拉框,可以导入和导出处理自动化建模的模板。而点击清除按钮可以清空画布上的模型。右上角的执行模型按钮可以运行构建好的模型,发布模型按钮则可以将构建好的模型发布为处理自动化工具。
点击执行模型按钮后,模型会提交为处理自动化任务。
在iServer服务列表中通过处理自动化服务下的geoprocessing/restjsr可以进入处理自动化服务的根资源,处理自动化服务根资源页面提供了地理工具列表和任务列表,通过工具列表可以查看处理自动化服务提供的所有工具以及您置入的自定义工具描述;通过任务列表进入处理自动化任务列表资源页面,即通过任务ID可查看对应的处理自动化任务信息。
三、实际应用
通过GPA模型实现导入shp数据,保存到本地工作空间中,制作地图,切矢量瓦片并存储到MongoDB数据库中,最后将其发布为服务。
1、制作GPA模型
要想实现上述的功能,我们需要知道在GPA模型中需要用到哪些算子才能完成操作,按照iDesktop和iServer中的实现流程,我们可以将其分为三部分:①导入shp数据、②制作地图保存工作空间、③切MongoDB瓦片、④发布MongoDB瓦片;在GPA模型中这些功能我们都能找到对应的算子,如:
①导入shp数据:导入.SHP数据
②制作地图保存工作空间:自动制图
③切MongoDB瓦片:生成矢量瓦片配置文件、拆分切图任务、多进程生成地图瓦片
④发布MongoDB瓦片:MongoDB瓦片发布
注:在GPA模型中,切瓦片总共要分为三步:生成矢量瓦片配置文件、拆分切图任务、多进程生成地图瓦片;在GPA模型中的地图瓦片工具提供了多进程生成地图瓦片的能力,根据地图的比例尺和地理范围等需要先将切图任务拆分成多个子任务;所以这里需要先进行拆分切图任务,然后再进行多进程生成矢量瓦片。
按照上述的分析,我们就可以在iServer的处理自动化界面中手动构建出完整的流程图,构建的效果图如下:

然后我们就可以在右侧的边栏中填写输入每个算子对应的参数信息;最后我们点击“执行模型”就可以实现整个功能了。
如何判断当前模型是否执行成功呢?我们可以通过以下两种方式来判断:①当模型中算子执行成功后,会在算子模块的右上角出现绿勾,说明当前算子执行完成,如果算子模块的右上角出现红叉,则说明当前算子执行失败,这个时候我们就需要去排查是否是因为参数填写错误导致的;②在iServer处理自动化的任务列表中找到对应的任务,查看当前的任务执行进程以及结果。
2、发布模型
当我们通过上一步中执行完成整个流程后会发现整个模型中包含的算子太多,并且各个算子之间的连接关系也很复杂,那么这个时候我们就可以通过另一种方法将其进行简化:将其发布为自定义模型工具。

这里的参数“保存参数值”如果勾选上,那么我们发布的自定义模型工具中就会默认包含刚才输入填写的参数,一般为了保障模型的重复使用,我们这里不再勾选。
发布完成后,在左侧边栏的“自定义模型工具”中就会包含我们刚才发布的模型,我们将其拖拽到界面中,发现当前的这个模型算子中参数是将之前所有算子进行了汇总,我们不用再考虑算子与算子之间的链接关系,只需要填写其对应的参数即可。

参考第一步中的全模型参数,我们填写了这个自定义的模型,执行后发现其结果与全流程结果一致。
3、通过post请求实现GPA模型自动化处理
为了实现自动化处理执行GPA模型,我们可以通过POST请求来实现这种过程,在POST请求中主要包含两个部分:POST请求头和POST请求体。其中POST请求头我们可以通过在iServer的处理自动化工具列表中获取到,根据第二步中发布的自定义模型工具中我们可以得到相应的服务地址
这里我们就可以获取到一个完整的POST请求头http://localhost:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:demo0210/jobs?token=qdPwJ4EGBaRDs_PFRYiy1xnwqFspiLJQCT-HXoKdzY1A2rHeRWmL0SMtA-krdUmZWqx_kdJQ2U_NL1iuvDFhfQ..
其中“sps.WorkflowProcessFactory.models:demo0210”为当前自定义模型工具的工具ID;而POST请求体中具体的参数如何填写,我们可以根据下面“输入参数”的内容来设置。

通过上述的内容,这里设置了具体的POST请求内容:
| POST请求头 | POST请求体 |
| http://localhost:8090/iserver/services/geoprocessing/restjsr/gp/v2/sps.WorkflowProcessFactory.models:demo0210/jobs?token=qdPwJ4EGBaRDs_PFRYiy1xnwqFspiLJQCT-HXoKdzY1A2rHeRWmL0SMtA-krdUmZWqx_kdJQ2U_NL1iuvDFhfQ.. | { "parameter": { "importshp-sourceFilePath":"D:\\SuperMap\\data\\202202\\0210\\test\\world.shp", "importshp-sourceFileCharset":"ANSI", "importshp-targetDatasource":"sdx --server=D:/SuperMap/data/202202/0210/test/test.udbx --alias=test --dbType=udbx", "importshp-targetDatasetName":"world", "importshp-targetEncodeType":"NONE", "importshp-importMode":"NONE", "importshp-isImportEmptyDataset":"false", "importshp-spatialIndexInfo":"ture", "importshp-isAttributeIgnored":"false", "importshp-isImportingAs3D":"false", "automapping-workspacePath":"D:\\SuperMap\\data\\202202\\0210\\test\\test.smwu", "automapping-mapName":"world", "automapping-templates":"", "buildvectorscifile-cacheName":"wp007", "buildvectorscifile-worksapcefile":"D:\\SuperMap\\data\\202202\\0210\\test\\test.smwu", "buildvectorscifile-mapName":"world", "buildvectorscifile-storageType":"MongoDB", "buildvectorscifile-levels":["1","2","3","4","5","6"], "buildvectorscifile-outputFolder":"D:\\SuperMap\\data\\202202\\0210\\wp007", "buildvectorscifile-cacheBounds":"-180.0,-90.0,180.0,83.62359619140625", "buildvectorscifile-tileStorageConnection":"--database=test0210 --server=localhost:27017", "buildvectorscifile-mvtStyleWithoutFont":"true", "buildvectorscifile-mvtWithAllField":"false", "buildvectorscifile-mvtTileBuffer":"16", "buildvectorscifile-mvtTileExtent":"4096", "buildvectorscifile-mvtWithoutFilter":"true", "buildvectorscifile-mvtSimplifyGeometry":"false", "buildcachemultiprocess-cpuPercentage":"50", "mongodbpublish-serverAdresses":"localhost:27017", "mongodbpublish-username":"", "mongodbpublish-password":"", "mongodbpublish-database":"test0210", "mongodbpublish-tilesetNames":["wp007"], "mongodbpublish-iserverPath":"http://localhost:8090", "mongodbpublish-token":"qdPwJ4EGBaRDs_PFRYiy1xnwqFspiLJQCT-HXoKdzY1A2rHeRWmL0SMtA-krdUmZWqx_kdJQ2U_NL1iuvDFhfQ..", "mongodbpublish-interfaceTypes":["地图服务","矢量瓦片服务"] }, "environment ": { "master":"spark://0.0.0.0:7077", "appName":"Geoprocessing", "settings":["spark.cores.max=8","spark.driver.host=192.168.29.252","spark.executor.memory=32g"] } } |
通过POST请求完成上述请求后,我们可以在iServer处理自动化的任务列表中看到具体的任务进程是否完成,以及执行结果等。
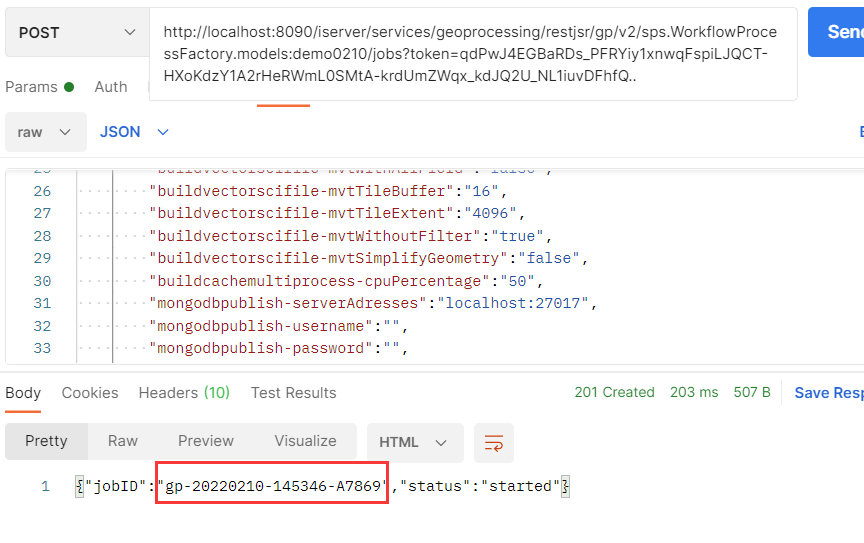
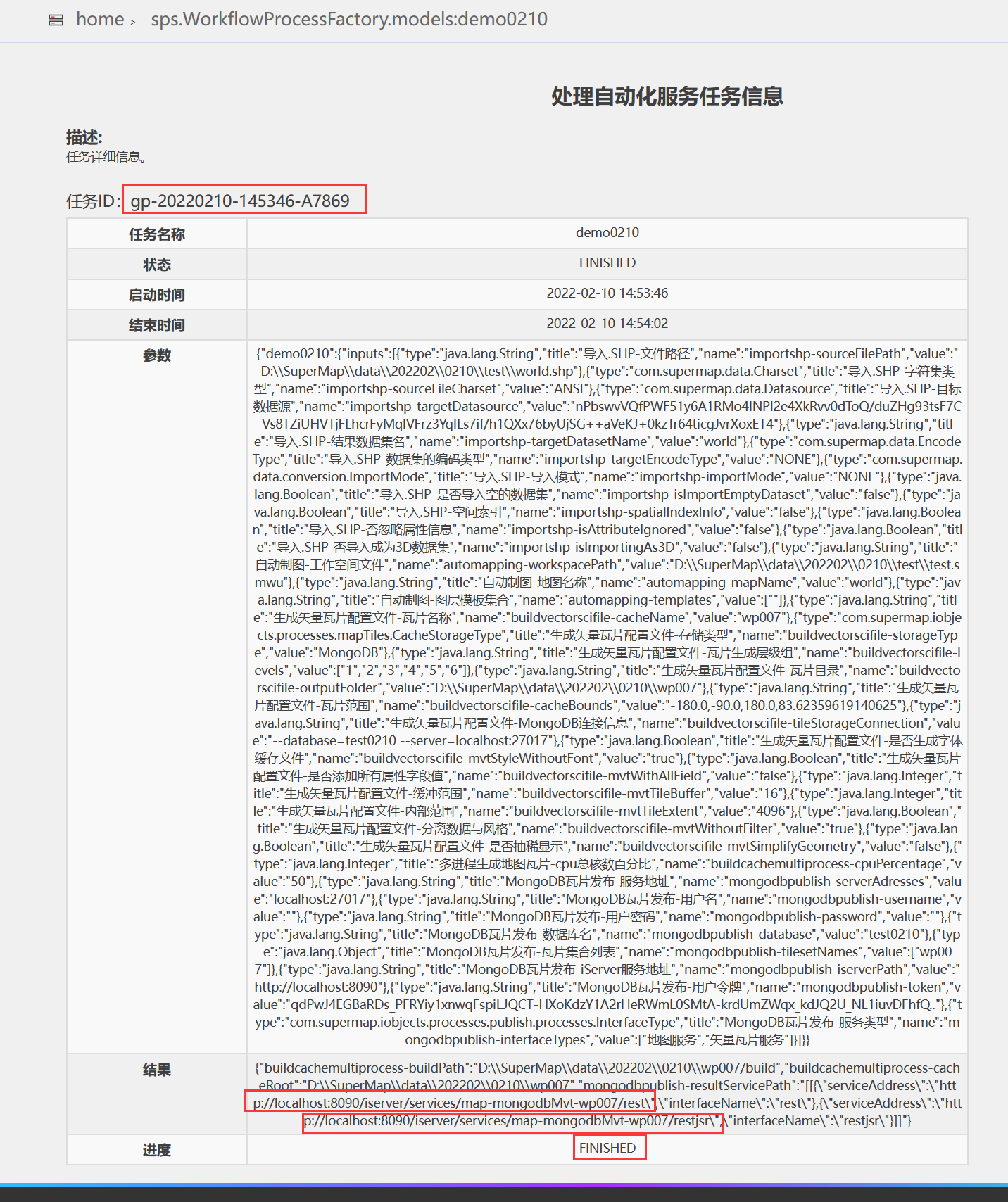
任务执行到这里后就说明当前的流程能够完整的走通,并且服务预览也都正常,说明通过POST请求完成GPA模型全流程自动化执行是能正常实现的。并且省去了手动输入参数,简化了操作过程。
四、注意事项
1、算子问题
由于目前官网发布的iServer版本中地理处理自动化算子中并不包含“MongoDB瓦片发布”,所以这里提供了替换的解决方法和步骤,具体请见附件“1、操作步骤.docx”;
2、模型算子问题
在制作GPA模型时,需要注意各个算子直接参数连接的前后关系,如在“生成矢量瓦片配置文件”与“拆分切图任务”两个算子之间,“生成矢量瓦片配置文件”的输出结果“瓦片目录”为“拆分切图任务”算子输入参数的“子任务目录”和“多进程生成地图瓦片”算子输入参数的“缓存目录”等。

3、POST请求参数问题
在POST请求中我们需要注意,post请求头中需要针对具体的模型工具来使用具体的url,其中地址中的token是在iServer中独自生成的http://localhost:8090/iserver/services/security/tokens,而post请求体中的参数则需要与当前模型工具的输入参数ID一致。为了进行区分,这里我们可以参考附件“2、post请求完成处理自动化流程.docx”,其中具体说明了post请求自动化模型全流程以及post请求单个算子模型的过程。














 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









