







自监督学习是近几年热门的话题,依据我目前所接触的知识,其主要有两种。一种是生成式,即GAN。我师兄在研究生阶段主要研究这一方面。另外一种就是对比式,注重对比,对比的思想在于,不要求过分注重像素级信息。红蓝两种颜色放在一起,你知道了什么是蓝色,自然你也就知道了什么是红色,这就是对比的魅力。
我目前所接触的关于对比式自监督的方法有:simclr、simsiam、byol。
simclr的思想很容易理解。输入的图片通过数据增强,得到x1和x2,将两者分别通过一个网络F得到h,在经过一个投影头得到z,两个z,通过NT- Xent损失函数计算损失,来更新参数,预训练好模型之后。将网络F用于下游任务。

最大的问题可能在于,不知道如何应用于下游的任务。
将模型参数保存好之后,可定义一个新的模型,但模型的前面层务必和F保持一致,后可直接接linear。用于softmax任务,或其他分类任务。
simsiam,跟simclr很相似,但是,后面多了一个predictor层。

其中encoder就是simclr的F+G,后面加一个mlp。
当然依分析来看byol是效果相对来说最好的。byol不需要负样本,跟simsiam一样,因此预训练的速度大大加快。
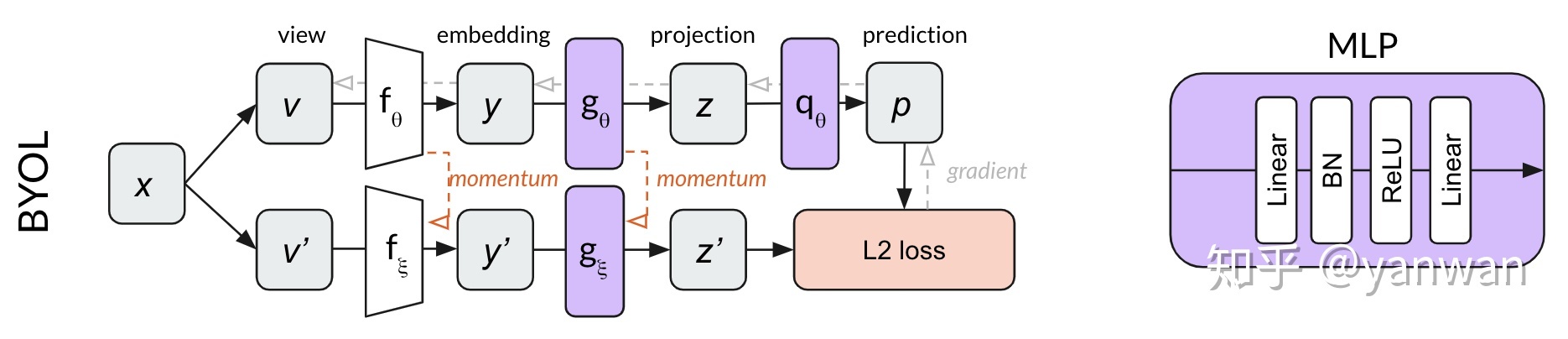
孪生网络结构很类似。F通常为resnet(resnet18,或其他的都可),G和Q的结构一模一样,都是一个MLP。
class MLP(nn.Module):
def __init__(self, in_dim): # 512
super(MLP, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, HPS['mlp_hidden_size']), # 512--4096
nn.BatchNorm1d(HPS['mlp_hidden_size'], eps=HPS['batchnorm_kwargs']['eps'], momentum=1-HPS['batchnorm_kwargs']['decay_rate']),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Linear(HPS['mlp_hidden_size'], HPS['projection_size']) # 4096--256
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
return x
此为G和Q的网络结构。
F我用的是resnet18
self.input_channels = input_channels
self.f = []
for name, module in resnet18(pretrained=False).named_children():
if name == 'conv1':
module = nn.Conv2d(self.input_channels, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear): # and not isinstance(module, nn.MaxPool2d)
self.f.append(module)
# encoder
self.f = nn.Sequential(*self.f)。。。。。。。。。。。。不想写了,后面补充吧














 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









