







在本周(2024.11.25)的一场科技对话中,谷歌前CEO Eric Schmidt的一番话让全世界为之震惊:“中国AI的发展速度已经让美国感到威胁!”是什么让这位曾在全球科技领域执掌多年的人感到如此不可思议?今天,我们将深入探讨中国AI如何用实力打破偏见,崛起为全球AI技术的焦点。
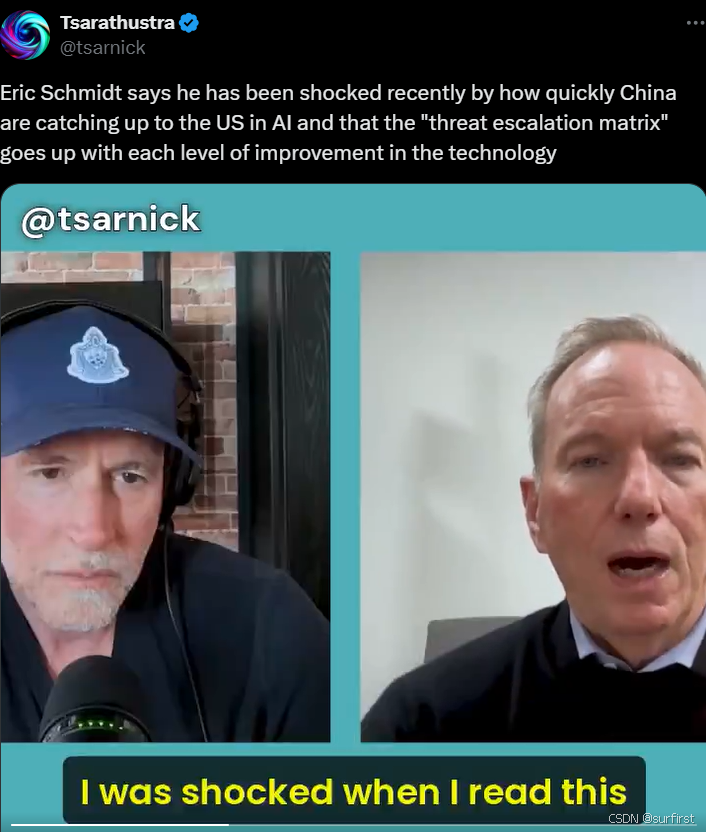
1. 是什么让谷歌前CEO Eric Schmidt感到震惊?
以下是Eric Schmidt在对话中的原话:
“This week there were two libraries from China that were released open source. One is a problem solver that’s very powerful, and another is a large language model that’s equal to and in some cases exceeds the one from Meta… I was shocked… I had assumed that… they were two to three years late. It looks to me like it’s within a year now.”
中文翻译为:
“本周中国发布了两个开源库,其中一个是功能强大的问题解决器,另一个是一个在某些情况下性能超越Meta的语言模型。我感到非常震惊,我本以为他们会落后两到三年,但现在看来差距已缩小到一年以内。”
从中我们不难看出,Eric Schmidt的震惊源于两方面:
- 技术实力的快速崛起:中国发布的模型不仅实现了性能赶超,还在部分领域展现出更强的潜力;
- 发展速度超出预期:原本以为中国还需两到三年才能追赶上美国,但如今,差距已经压缩到一年内!
这背后展现的是中国AI的全面逆袭,而两款让Schmidt感到不可思议的大模型,则是我们的骄傲。
2. 让谷歌前CEO感到震惊的两款中国大模型
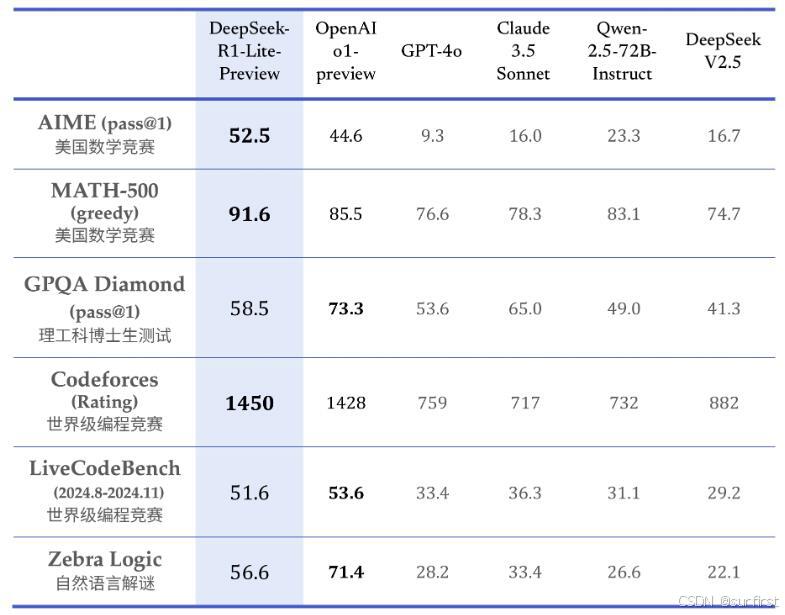
2.1 DeepSeek-R1-Lite 预览版
DeepSeek-R1-Lite 预览版是由 DeepSeek 公司全新研发的推理模型,专注于提供深度思维链推理能力。 该模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。 它在数学、代码以及各种复杂逻辑推理任务上展现出卓越的性能,能够媲美甚至超越 OpenAI 的 o1-preview 模型。
2.2 Qwen 2.5
作为阿里巴巴推出的旗舰大模型,Qwen 2.5的性能在许多任务中甚至超越Meta的Llama 3。更令人惊讶的是,它背后依赖的硬件资源受到显著限制,但依然展现了强大的算法优化能力。这款模型的发布,证明了中国AI不仅能在技术上站稳脚跟,更能在开源生态中发力,为全球开发者提供更多选择。
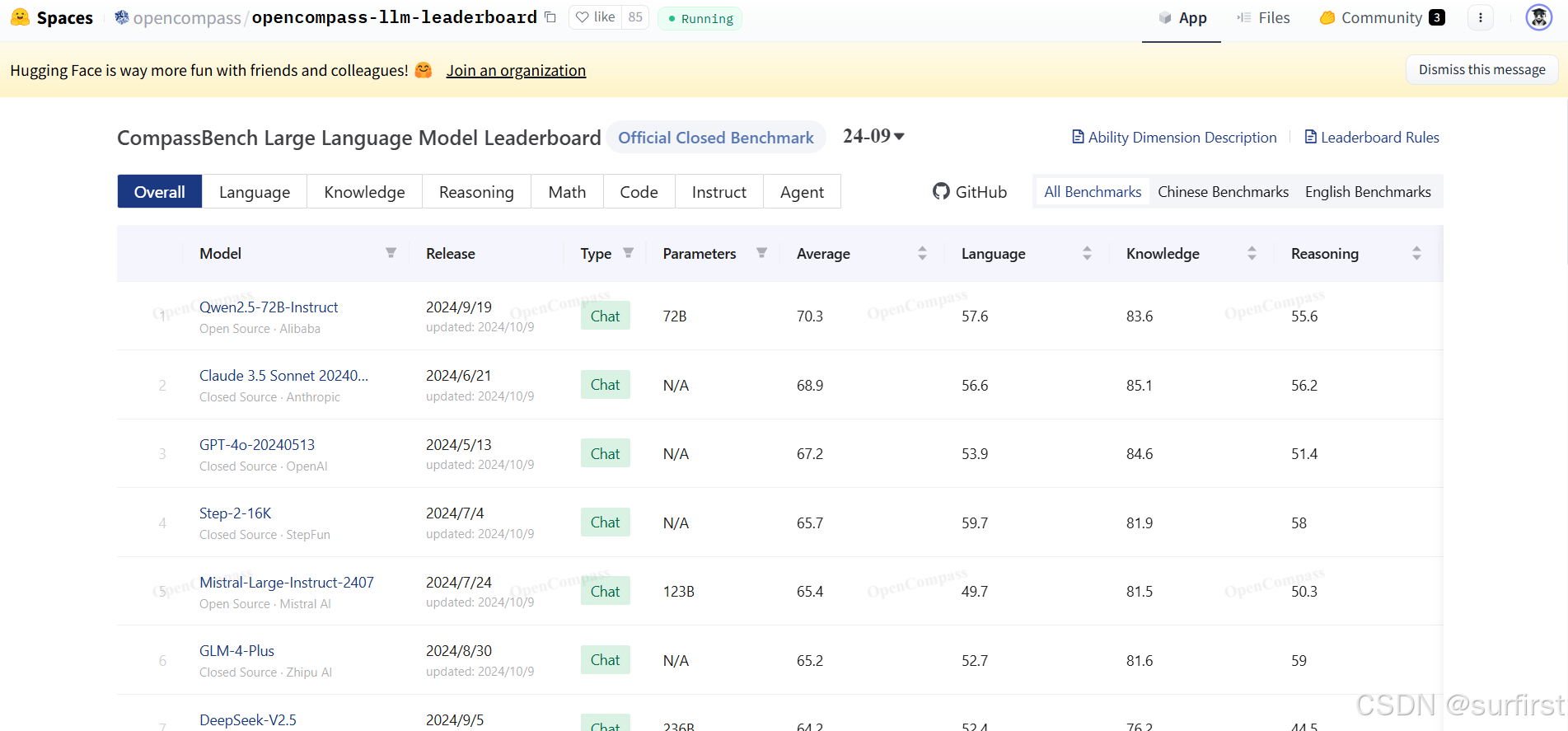
这两款模型的成功无疑宣告:中国AI不仅赶上了世界一流水平,更在部分领域超越了原有的领导者。
3. 为什么中国公司的进展让老外感到吃惊?
中国AI公司之所以让美国乃至全球感到震惊,归根结底在于外界长期以来对中国AI能力的低估。然而,这一次,中国AI用实际行动打破了偏见。
3.1 逆境中崛起
美国对高端AI芯片的出口限制一度让外界以为中国AI发展会停滞。然而,中国公司通过优化资源利用率和创新训练方法,顽强地在硬件受限的条件下实现了突破。

台积电7nm禁令

Nvidia禁令
3.2 成本与效率的极致平衡
相比GPT-4动辄花费8千万到1亿美元的训练费用,中国AI公司在更低的预算下达到了相同甚至更高的效果。这种“高性价比”的技术开发路径为全球AI行业提供了全新的思路。
3.3 技术突破引发错位认知
长久以来,国际社会对中国AI的评价往往停留在“追随者”的标签上。然而今天,中国AI技术的快速进步已经逼近甚至在某些领域超越了Meta和OpenAI的水准。这种认知的错位引发了巨大反响。
4. 中国公司是如何克服这些挑战的?
4.1 李开复的洞见:优秀工程文化驱动创新

以下是李开复关于01.AI的精彩发言:
“01 now has the third-best modeling company in the world ranking number six in models measured by LM CIS and UC Berkeley. But the most amazing thing—I think the thing that shocks my friends in Silicon Valley—is not just our performance but that we trained the model with only $3 million. GPT-4 was trained by $80 to $100 million, and GPT-5 is rumored to cost about a billion dollars.
It is not the case we believe in scaling law. But when you do excellent detailed engineering, it is not the case you have to spend a billion dollars to train a great M.
As a company in China, first, we have limited access to GPUs due to US regulations, and secondly, the Chinese companies are not valued like American companies. We are valued at a fraction of the equivalent American company. So, when we have less money and difficulty getting GPUs, I truly believe that necessity is the mother of innovation.
When we only have 2,000 GPUs, well, the team has to figure out how to use it. I, as the CEO, have to figure out how to prioritize it. And then, not only do we have to make training fast, we have to make inference fast.”
中文翻译如下:
“01.AI目前是世界排名第三的模型公司,在LM-CIS和UC Berkeley的榜单上排名第六。但最让硅谷的朋友震惊的,不仅是我们的性能,而是我们仅用300万美元完成了模型训练。而GPT-4的训练成本是8000万到1亿美元,GPT-5据说更是接近10亿美元。
我们并不认为规模定律是唯一的准则,但只要工程做得足够优秀,就不需要花费10亿美元去训练一个顶尖模型。
在中国,我们首先受到美国GPU出口限制的影响,其次,中国公司的估值远低于美国公司,仅为后者的一个零头。所以,当我们资源有限、获取GPU困难时,我坚信‘需求是创新之母’。
当我们只有2000块GPU时,团队需要想办法高效利用。我作为CEO,必须设定优先级。不仅训练速度要快,推理速度也同样重要。”
4.2 总结:如何在限制中实现突破
从李开复的发言中,我们可以总结出中国公司如何克服挑战的三大关键策略:
1. 高效资源利用
在GPU数量和计算资源受限的情况下,中国团队通过算法优化和资源调度,最大化利用现有资源。例如,01.AI仅用2000块GPU完成了顶尖模型的训练和推理优化,展现了卓越的工程能力。
2. 优先级管理与成本控制
中国AI公司在预算和硬件资源有限的情况下,精准确定研发方向,用300万美元完成了性能与GPT-4媲美的模型训练。相比之下,GPT-4的训练成本高达数十倍甚至上百倍。
3. 工程创新推动效率提升
李开复指出,“需求是创新之母。”面对硬件限制和资金压力,团队专注于细节,开发出高效的训练和推理流程,用实际成果证明大模型的成功不必依赖天价投入。
这种工程驱动的创新文化,让中国AI公司在逆境中实现了突破,也为全球AI行业提供了全新的发展思路。
5. 总结:中国AI崛起的全球意义
中国AI大模型的成功,向世界展示了面对资源限制时如何通过创新与高效实现突破。更重要的是,中国AI正在重新定义全球技术竞争的规则:不靠资源取胜,而是靠技术实力与成本效率双重驱动。
正如Eric Schmidt所言,如今中国AI的技术差距仅剩不到一年。这样的成就,不仅让中国AI行业倍感自豪,也让全球AI领域重新评估中国在技术创新上的潜力。
在这场激烈的技术竞赛中,中国AI公司已不再是跟随者,而是实至名归的全球竞争者!
参考链接:
- https://www.deepseek.com/
- https://x.com/tsarnick/status/1860787204660019313
- https://huggingface.co/spaces/opencompass/opencompass-llm-leaderboard



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











