







本文是关于如何优化 RAG 技术的一系列文章之一。在之前的文章中,我们已经深入探讨了如何在 Chunking、Embedding 以及评估指标设计等环节优化 RAG 性能。这篇文章将重点关注如何准备评估 RAG 性能所需的数据集,为后续优化打下坚实基础。
1. 优化 RAG 不是“炼丹”,需要系统的方法
当涉及到如何优化 RAG(Retrieval-Augmented Generation)性能时,许多人往往采取“试错”的方法:“我尝试了一个新模块,问了几个问题,答案看起来还行…”。这样的定性评估方式虽然直观,但很难得出可靠的改进结论。
优化 RAG 性能需要采用科学实验的方式。这意味着我们必须设计量化的评估指标,并准备高质量的评估数据集。通过结构化的实验和评估方法,我们才能明确什么样的调整会真正提升性能。

2. 结构化评估 RAG 的性能
RAG 系统的性能评估可以从以下两个主要方面进行:
- 检索评估(Retrieval Evaluation): 检索的段落是否相关?
- 生成评估(Generation Evaluation): 模型生成的答案是否恰当?
对于端到端的评估,我们通常关注以下四类指标:
- Groundedness(可靠性): 检索评估中的关键指标,评估检索的段落是否为生成的答案提供了可靠支持,避免幻觉(hallucinations)或无关信息。这是生成评估的基础。
- Completeness(完整性): 生成评估的核心指标,用于评估模型的回答是否全面覆盖了用户问题的所有方面,同时间接反映了检索阶段的信息充分性。
- Utilization(利用率): 连接检索和生成的桥梁指标,用来评估检索到的信息是否被有效利用。如果利用率低,可能意味着检索到的段落与问题无关,或者模型未充分使用这些段落。
- Relevance(相关性): 检索评估的直接反映,衡量检索到的段落与用户问题之间的相关性,同时也会影响生成评估的整体表现。
这些指标需要基于高质量的测试样本和严格的评估流程。
3. 使用 Agents 完成 RAG 性能基准测试
在开始具体流程前,我们需要了解三个代理(Agents)的协作关系:
- 测试样本代理(Test Sample Agent): 用于生成和准备测试数据,这些数据构成了评估系统的基础。
- 样本质量评价代理(Critique Agent): 对测试样本进行质量审核,确保最终用于评估的数据具备高准确性和清晰性。
- 评估代理(Evaluation Agent): 负责根据设计的指标对系统性能进行量化评估。这些评估指标覆盖了检索和生成的多个层面。
通过这三种代理的协作,可以建立一个系统化的性能基准测试流程,帮助开发者深入理解和优化 RAG 系统。
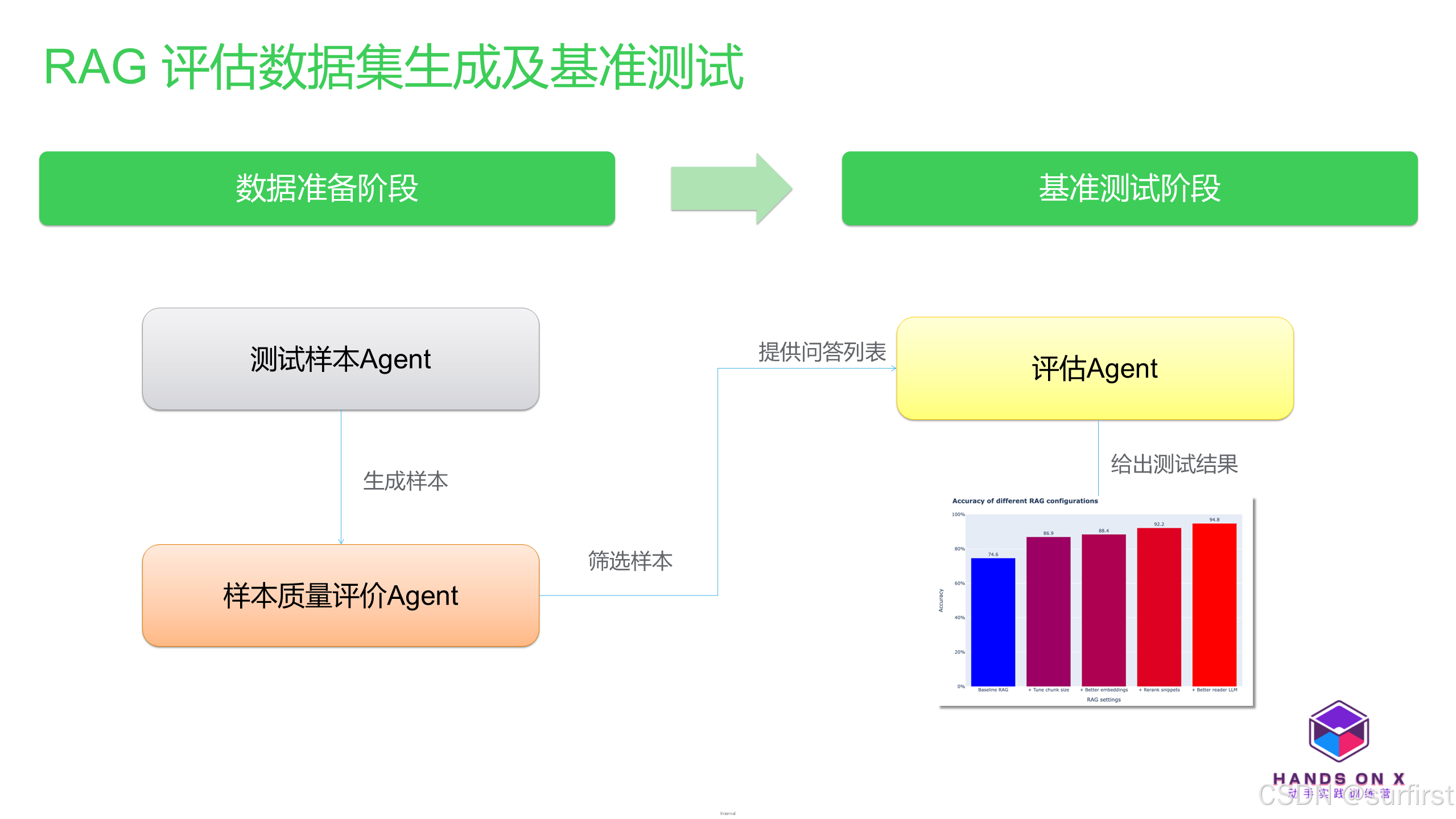
3.1 生成测试样本
为了评估 RAG
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











