






主要是分为5个部分。分别是:开始、文档提取器、代码执行、LLM大语言模型、结束 5个部分
打开dify,创建一个空白页面-选择工作流,我们给应用起个名字。
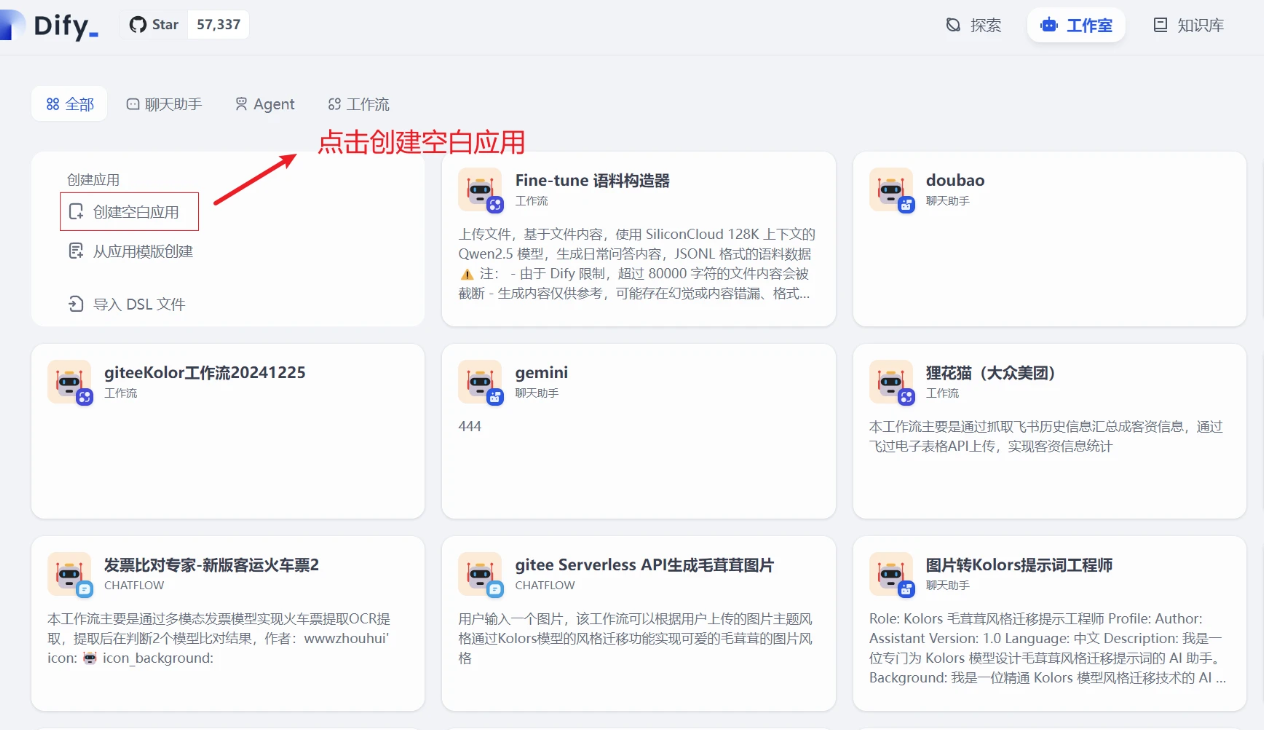
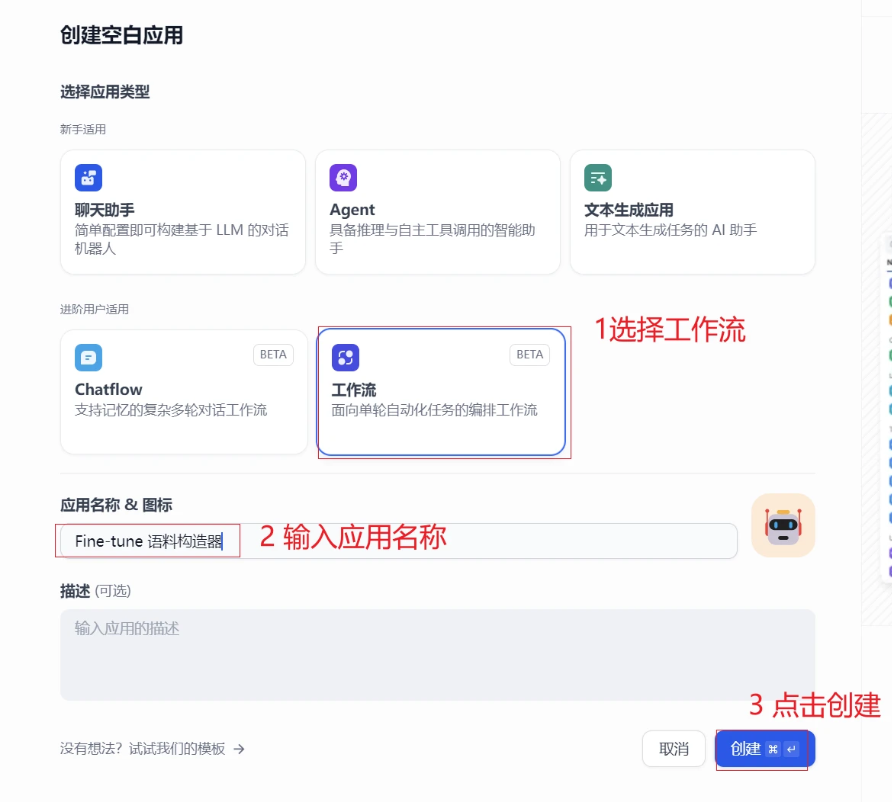
创建完成后,进入工作流画布界面
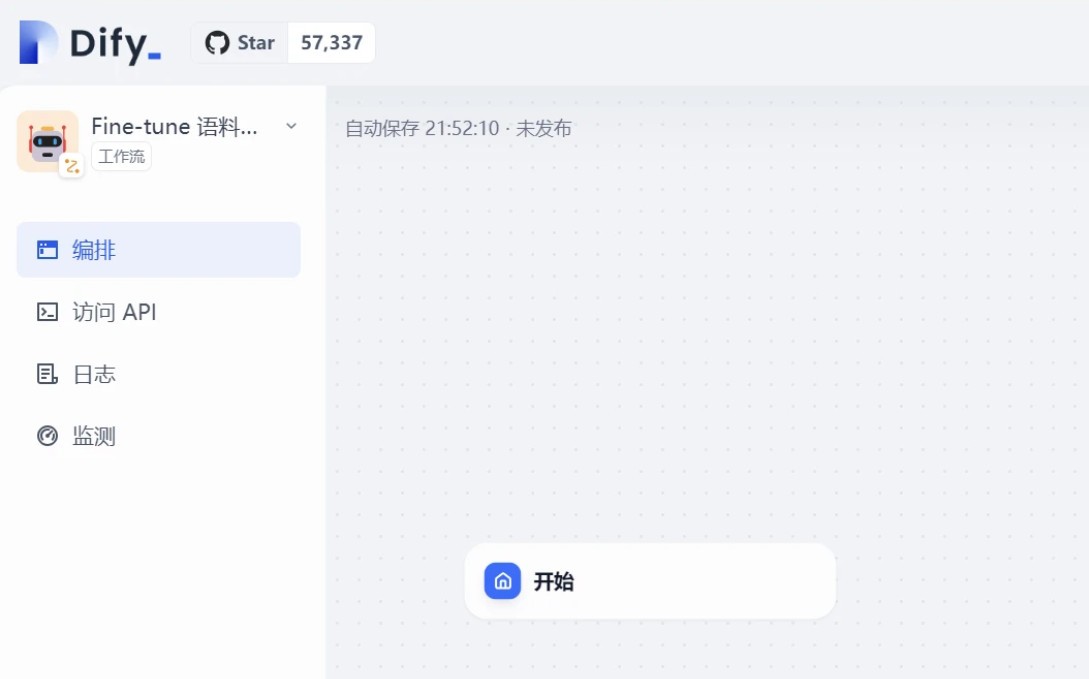
开始
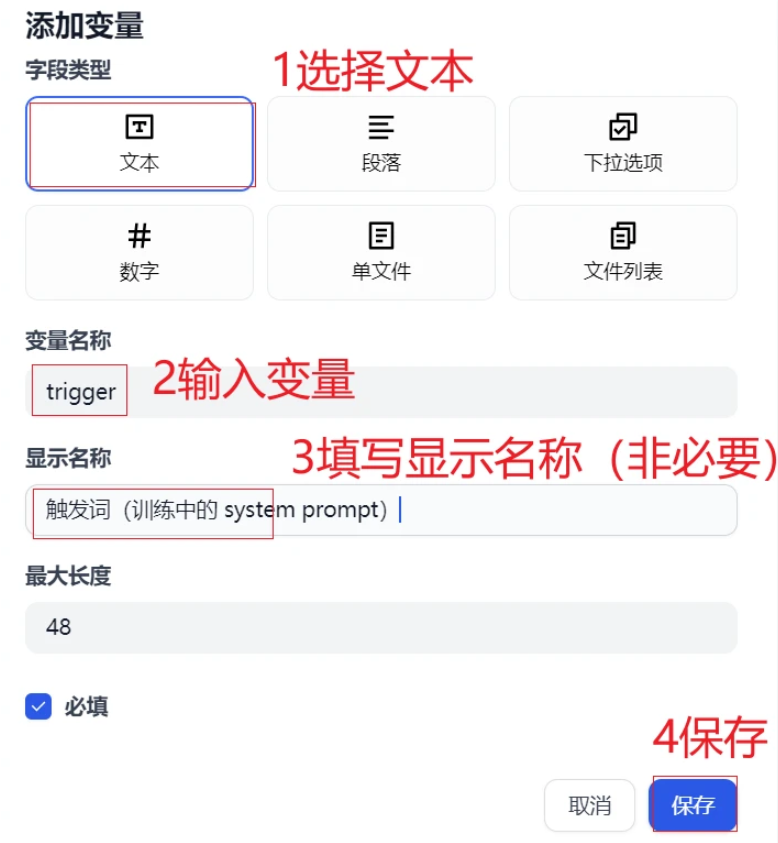
在开始节点中新建2个输入参数。1个是用户上传的文件,1个是触发词(训练中的 system prompt)
第一个参数attachments
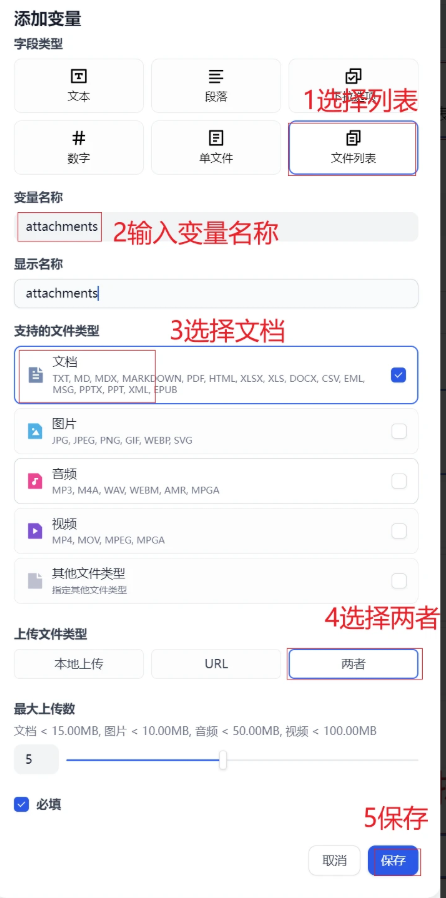
设置第二个参数触发词
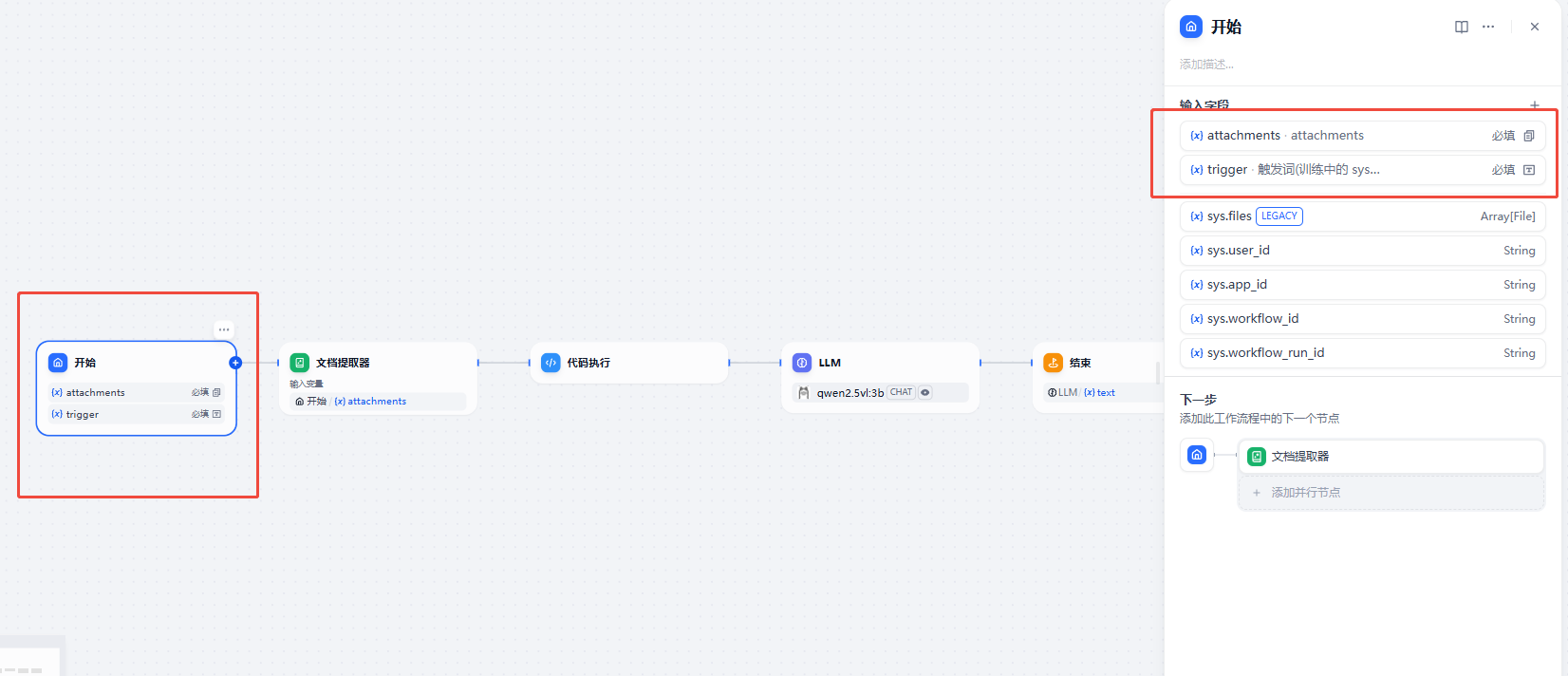
文档提取器
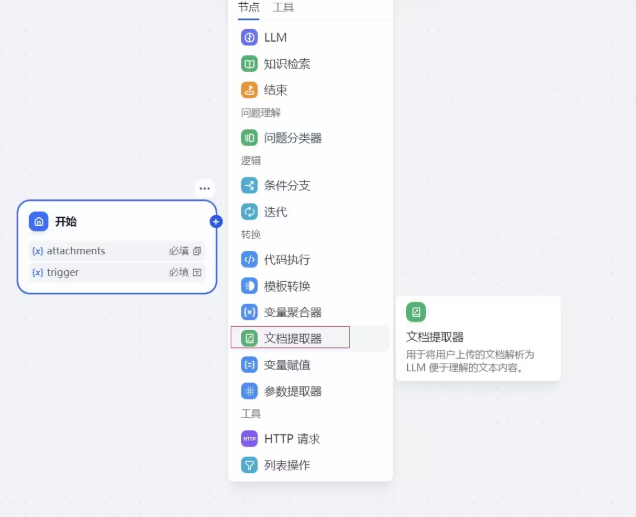
我们开始节点右边的加号点击打开,选择文档提取器节点
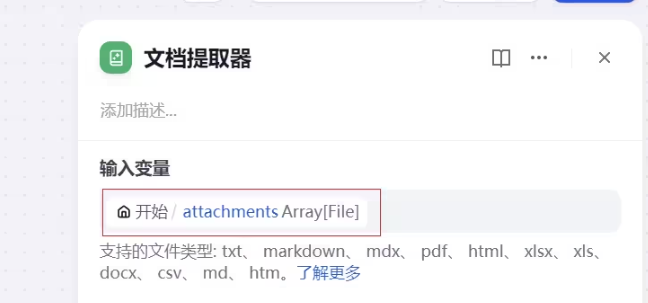
文档提取器输入变量,填写开始节点中的attechments 数组参数
代码执行
在文档提取器右边加号节点中选择代码执行工作流和文档提取器节点连接上。
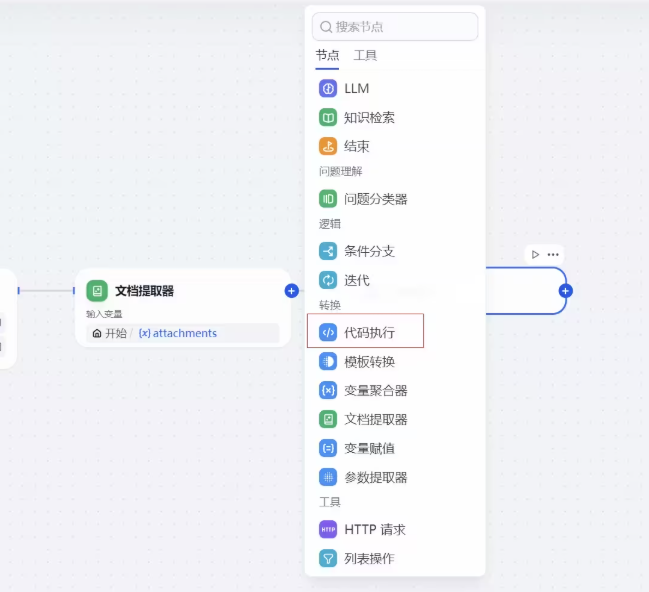
在代码执行右边窗口中,我们这里是需要一个输入参考,参数名和参数值分别如下
- 参数名:articleSections
- 参数值:文档提取器text(数组)
参数值输入/会进行提示
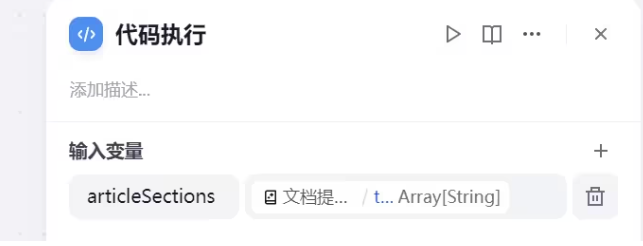
def main(articleSections: list) -> dict:
try:
# 将列表项合并为字符串
combined_text = "\n".join(articleSections)# 截取前80000个字符
truncated_text = combined_text[:80000]return {
"result": truncated_text
}
except Exception as e:
# 错误处理
return {
"result": ""
}
代码执行主要目的是合并前面流程中合并多个文档内容,并截取前 8W 字符。为什么是8w 主要是dify 沙箱运行环境长度限制导致,如果有的小伙伴觉得这个不够用可以自己写接口服务实现合并多个文档内容。
输出变量,参数值result 类型 string
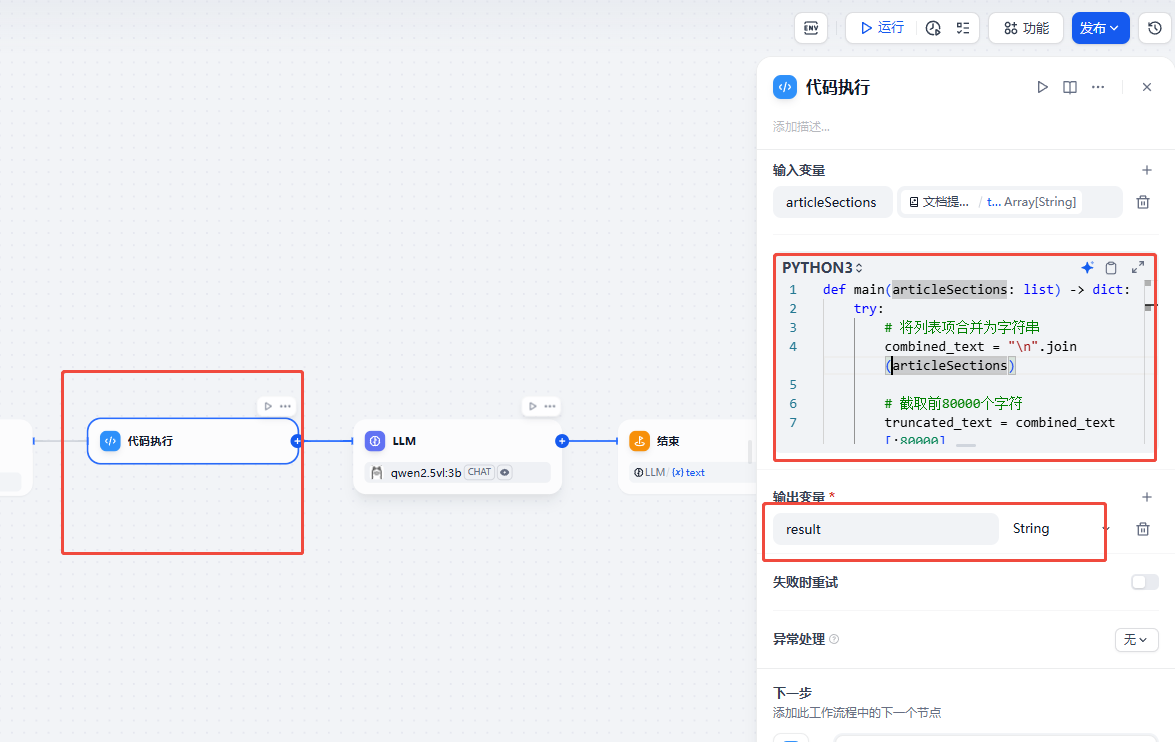
LLM
接下来我们需要代码执行连接一个LLM大语言模型,这个大语言模型主要的目的就是处理上面文档内容,通过提示词将其转换成符合我们模型微调的数据集。
以下是一条典型的微调数据示例:
{"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "应该怎么学习?"}, {"role": "assistant", "content": "贤贤易色;事父母,能竭其力;事君,能致其身;与朋友交,言而有信。虽曰未学,吾必谓之学矣。"}]}
LLM 配置信息如下
1.模型我们选择了调用qwen2.5vl:3b模型
2.系统提示词
3.用户提示词
系统提示词内容如下:
【角色】
你是一位 LLM 大语言模型科学家,参考用户提供的内容,帮助用户构造符合规范的 Fine-tune(微调)数据【任务】
- 对于给定的「内容」,你每次回列出 10 个通俗「问题」;
- 针对每个「问题」,引用「内容」原文及对内容的合理解释和演绎,做出「解答」;
- 并将「问题」「解答」整理为规范的 JSONL 格式【要求】
1. 问题 **不要** 直接引用「内容」,应该贴近当代现实生活;
2. 问题应该是通俗白话,避免“假、大、空“;
3. 答案应忠于原文,对于原文的解释不能脱离原文的主旨、思想;【输出规范】
* 输出规范的 JSONL,每行一条数据
* 每条数据应包含一个 message 数组,每个数组都应该包含 role 分别为 system、user 和 assistant 的三条记录
* 其中 role 为 system 的数据,作为训练中的 system prompt 格外重要,其 content 使用用户指定的「触发词」
* role 为 user 的数据对应列出的「问题」
* role 为 assistant 的数据则对应针对「问题」的「解答」
* 示例如下:
```
{"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "应该怎么学习?"}, {"role": "assistant", "content": "贤贤易色;事父母,能竭其力;事君,能致其身;与朋友交,言而有信。虽曰未学,吾必谓之学矣。"}]}
```
这里主要的目的是告诉LLM大语言模式将文档内容转换成上面样子数据,这样它才能按照你的要求输出。
用户提示词 这里主要是接受 文本内容以及我们在开始节点中要求的触发词(训练中的 system prompt)
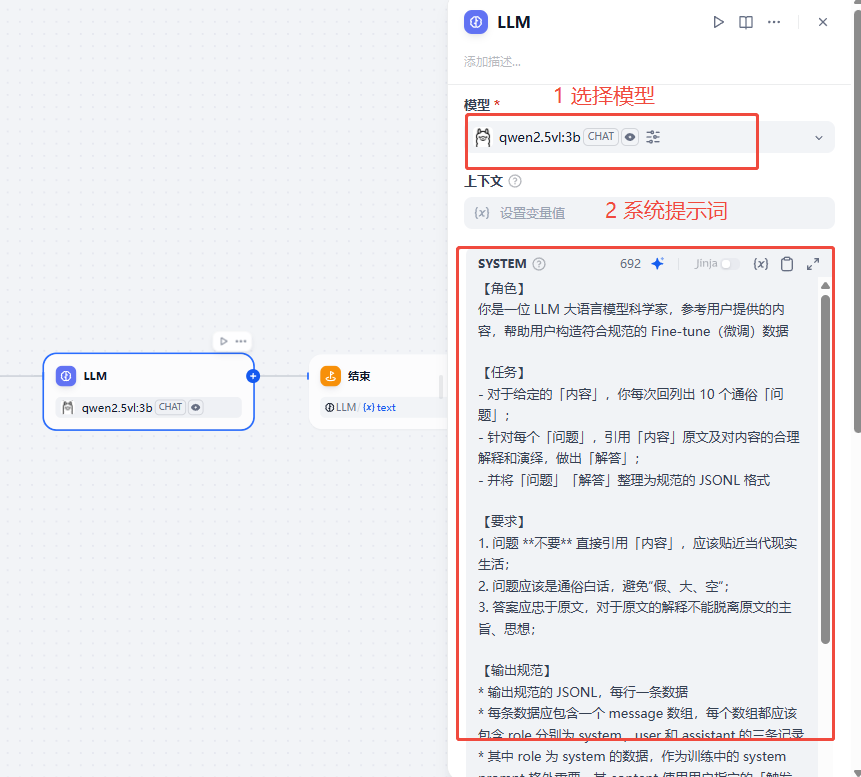
用户提示词
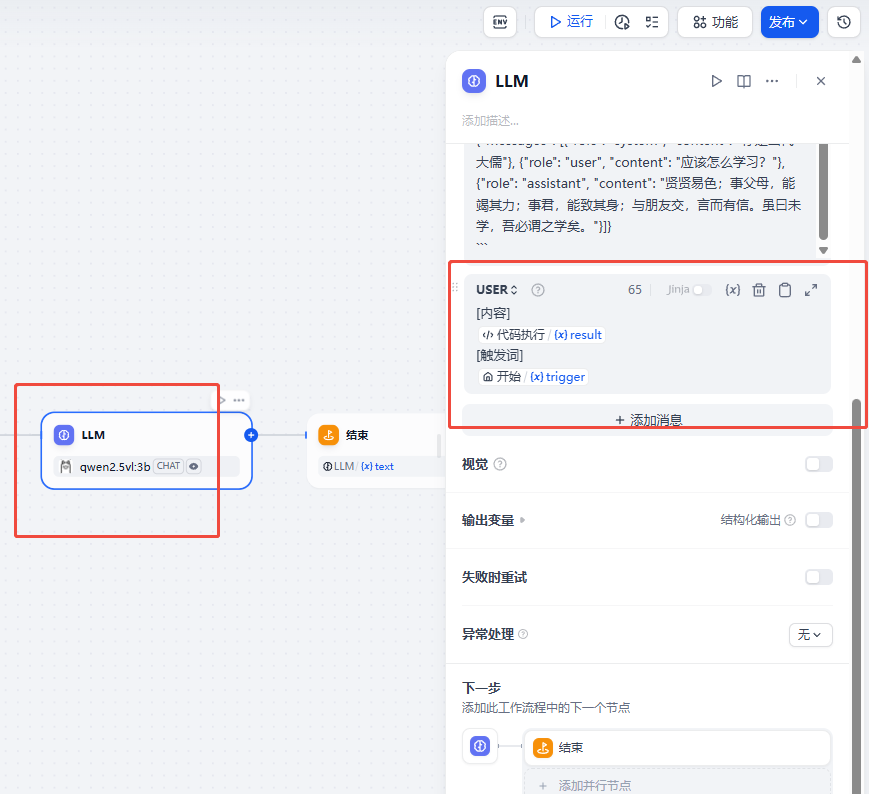
结束
这里我们需要从llm大语言模型中右边节点中添加一个结束节点。输入参数是llm输出text
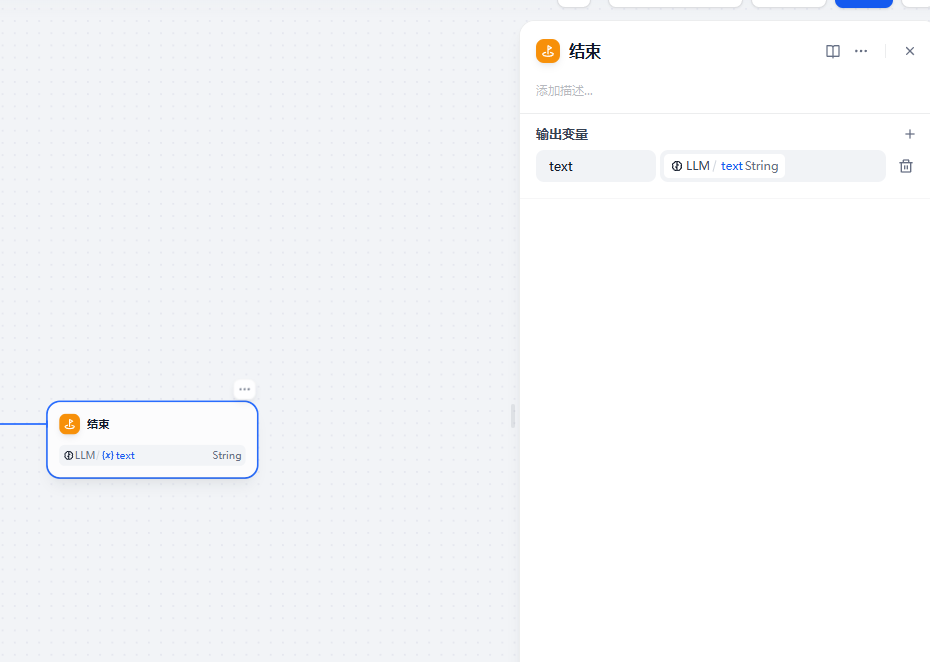
通过以上方式我们就完成了微调(Fine-tuning)语料构造工作流的制作。
测试
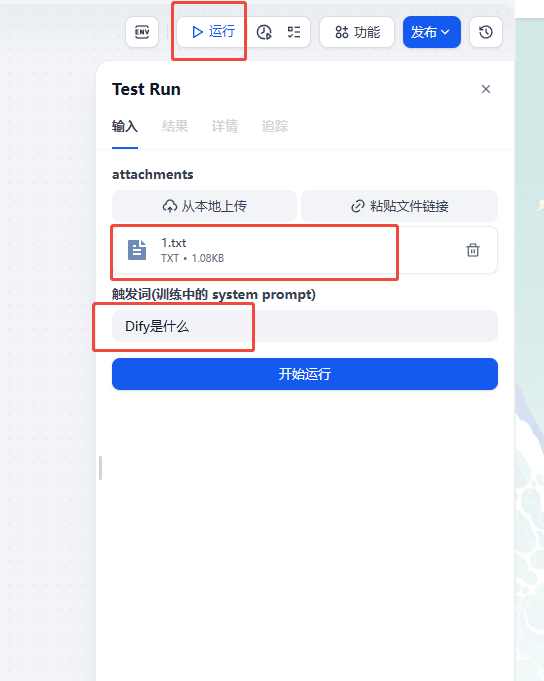
记下来我们对这个工作流进行测试。点击工作流上面的运行按钮
输入训练的预料文件,我这里为了方便测试就输入一个单个txt文档。触发词输入:Dify是什么
txt内容:
### 产品功能介绍
Dify 是一款开源的LLM应用开发平台,支持通过可视化工作流快速构建AI应用。核心功能包括:
- 可视化Prompt编排
- 多模型支持(GPT/Claude/本地模型)
- 知识库增强检索
- API和Webhook集成
- 使用数据分析看板### 快速入门指南
1. 注册并登录Dify控制台
2. 创建新应用选择"对话型"或"编排型"
3. 在Prompt工作室设计交互流程
4. 添加知识库文档增强AI回复准确性
5. 通过API部署到您的业务系统### 常见问题解答
Q: 支持哪些文件格式的知识库上传?
A: 目前支持txt/md/pdf/docx/pptx格式,建议单个文件不超过20MBQ: 如何处理知识库更新?
A: 文件更新后需重新触发索引构建,系统会自动进行增量更新Q: API调用频率限制是多少?
A: 免费版限制100次/分钟,企业版可自定义QPS### 技术支持渠道
官方文档:docs.dify.ai
社区论坛:community.dify.ai
紧急支持:support@dify.ai(响应时间<2小时)
工单系统:控制台右上角"帮助中心"
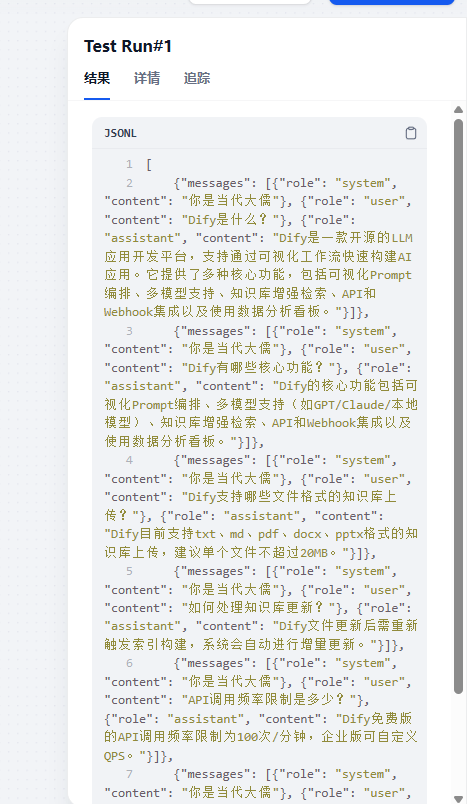
[ {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "Dify是什么?"}, {"role": "assistant", "content": "Dify是一款开源的LLM应用开发平台,支持通过可视化工作流快速构建AI应用。它提供了多种核心功能,包括可视化Prompt编排、多模型支持、知识库增强检索、API和Webhook集成以及使用数据分析看板。"}]}, {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "Dify有哪些核心功能?"}, {"role": "assistant", "content": "Dify的核心功能包括可视化Prompt编排、多模型支持(如GPT/Claude/本地模型)、知识库增强检索、API和Webhook集成以及使用数据分析看板。"}]}, {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "Dify支持哪些文件格式的知识库上传?"}, {"role": "assistant", "content": "Dify目前支持txt、md、pdf、docx、pptx格式的知识库上传,建议单个文件不超过20MB。"}]}, {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "如何处理知识库更新?"}, {"role": "assistant", "content": "Dify文件更新后需重新触发索引构建,系统会自动进行增量更新。"}]}, {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "API调用频率限制是多少?"}, {"role": "assistant", "content": "Dify免费版的API调用频率限制为100次/分钟,企业版可自定义QPS。"}]}, {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "Dify有哪些技术支持渠道?"}, {"role": "assistant", "content": "Dify提供了官方文档、社区论坛、紧急支持和工单系统等技术支持渠道。"}]} ]
上面的数据是符合模型微调json格式的数据,把他保存为XX.jsonl。后面模型微调时候就可以用这个构造好的XX.jsonl作为模型微调的数据集了。

















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









