







 本文介绍了线性回归模型的基本概念,包括其在房屋价格预测中的应用。重点讨论了代价函数的作用,如何衡量模型与数据的拟合度,并详细讲解了梯度下降算法,包括学习率的选择及其对优化过程的影响。
本文介绍了线性回归模型的基本概念,包括其在房屋价格预测中的应用。重点讨论了代价函数的作用,如何衡量模型与数据的拟合度,并详细讲解了梯度下降算法,包括学习率的选择及其对优化过程的影响。
文章目录
一、线性回归模型(Linear Regression Model)
1、 什么是线性回归?
That just means fitting a straight line to your data.//在这里我查阅资料发现说法并不完全准确,不一定非是直线,也可以是曲线
2、线性回归模型例子
经典的房屋价格预测,注意横轴数轴代表什么,说人话就是给出一些面积和价格让计算机算出一个大致的线性方程,再给面积值的时候就能预测价格了
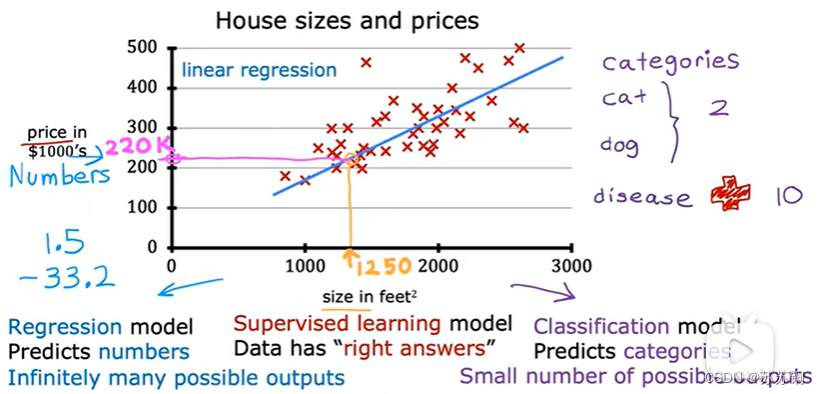
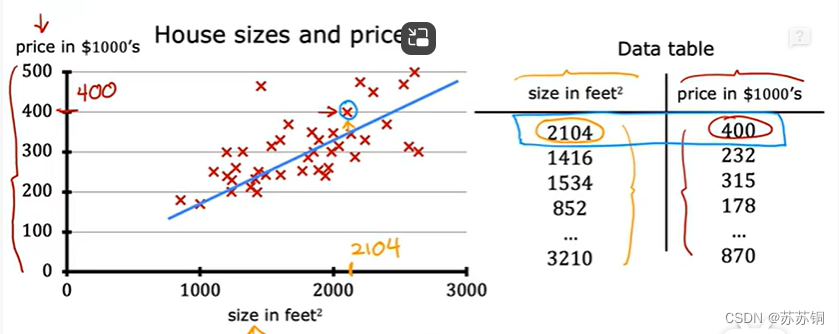
二、术语(Terminology)

| Terminology | 术语 |
|---|---|
| Training set | 训练集 |
| input variable /feature | 输入变量x |
| output variable/target variable | 输出变量y |
| number of training examples | 训练样本总数m |
| single training example | 训练实例 |
| cost function | 代价函数 |
| parameters | 参数 |
三、代价函数
1、什么是代价函数公式
Constructing a cost function can measure how well a line fits the training data.//衡量一条线与训练数据的拟合程度
| 表达式 | 术语 |
|---|---|
| ( x ( i ) , y ( i ) ) = ( 2014 , 400 ) (x^{(i)},y^{(i)})=(2014,400) (x(i),y(i))=(2014,400) | 第i个训练实例 |
| f w , b ( x ) = w x + b f_{w,b}(x)=wx+b fw,b(x)=wx+b | 假设函数 |
| J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 J{(w,b)}=\frac{1}{2m}\sum^{m}_{i=1}{(\widehat{y}^{(i)}-y^{(i)})^2} J(w,b)=2m1i=1∑m(y (i)−y(i))2 | 代价函数 |
其中
y
^
(
i
)
=
f
w
,
b
(
x
(
i
)
)
\widehat{y}^{(i)}=f_{w,b}(x^{(i)})
y
(i)=fw,b(x(i)),所以代价函数也可以表示为
j
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
j{(w,b)}=\frac{1}{2m}\sum^{m}_{i=1}{(f_{w,b}(x^{(i)})-y^{(i)})^2}
j(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2
2、理解代价函数
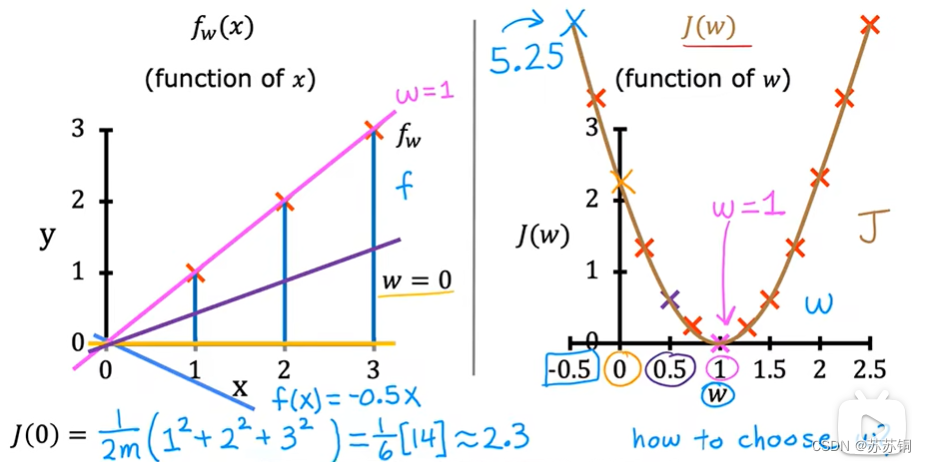
goal of linear regression: minimize
J
(
w
)
J{(w)}
J(w)
general case: minimize
J
(
w
,
b
)
J{(w,b)}
J(w,b)//最小化代价函数值
四、梯度下降(gradient descent)
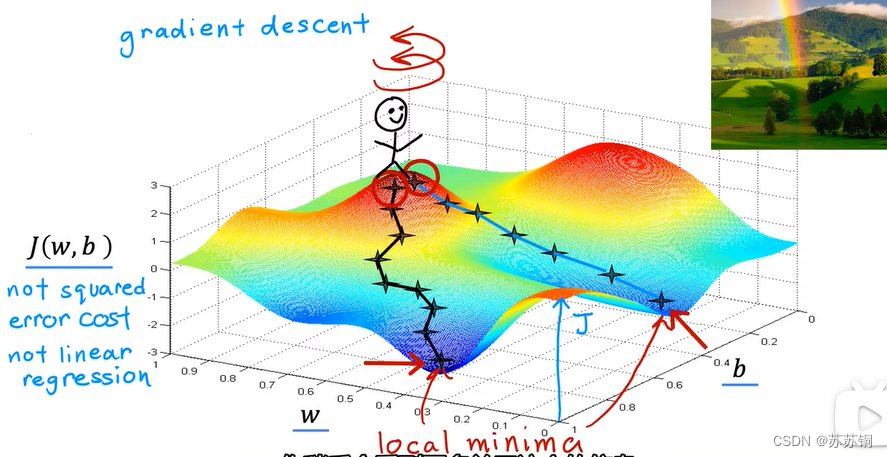
1、什么是梯度下降
It is an efficient algorithm that you can write in code for automatically finding the values of parameters w and b.They give you the best fit line that minimizes the cost function j.//自动查找参数w和b的值,提供最佳拟合线

α
\alpha
α : learning rate //学习率
注意w和b的更新要同时进行
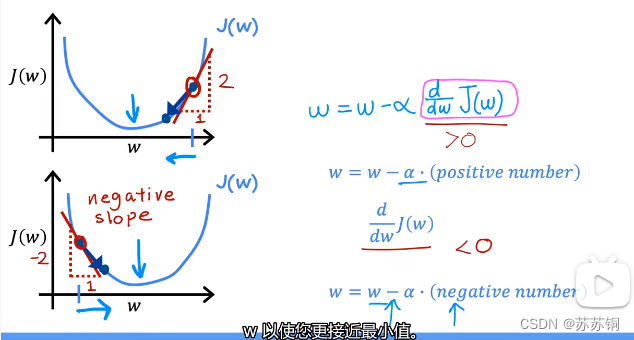
用偏导数与学习率
α
\alpha
α相乘,对参数进行不断修正,使其更接近最小值
2、梯度下降算法细节
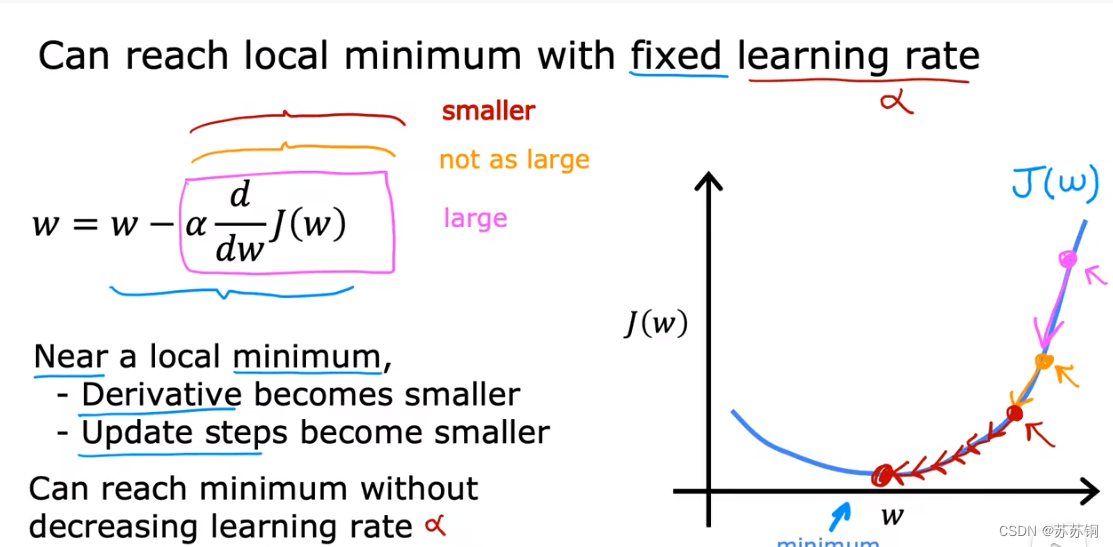
如果学习率太小,过程缓慢;如果太大,可能无法收敛。
固定的学习率也能因为偏导数越来越小让更新的步骤变得越来越“小心”
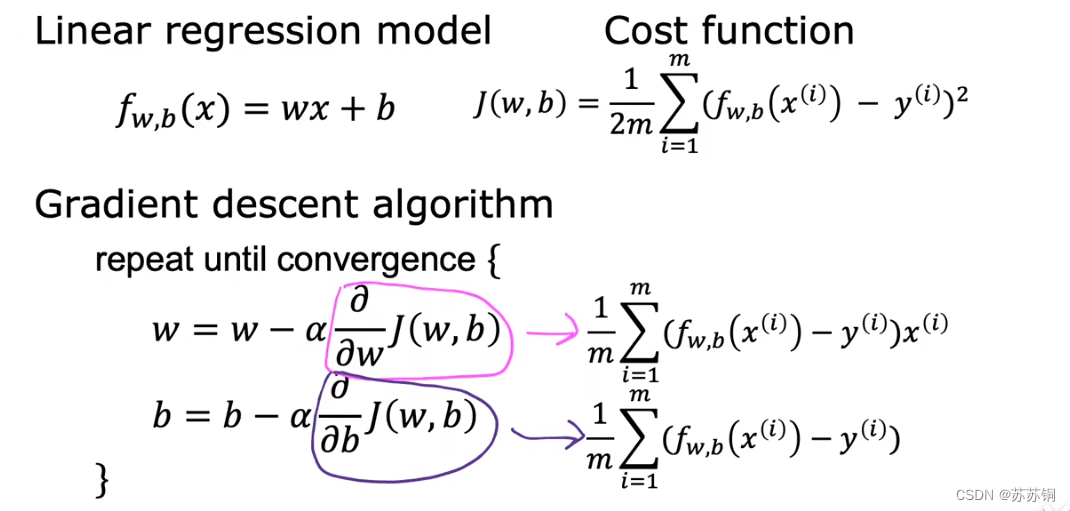
两个偏导数的计算公式

关于微积分的推导过程,高数知识
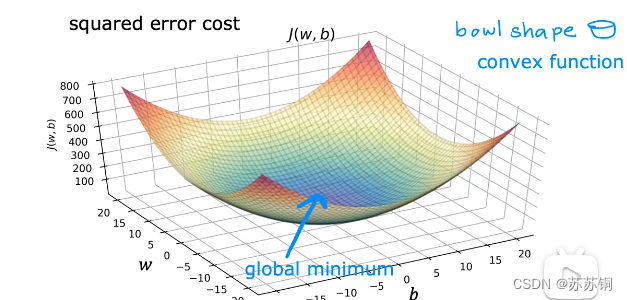
线性回归的平方误差代价函数的函数值没有多个局部最小值,只有一个全局最小值
批量梯度下降:在梯度下降的每一步中都用到所有训练示例















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









