










关于python操作文档的问题
文档类型:docx
语言:python我想在文档中姓名后面的下划线之上插入一个姓名,并保存为新的文档,
用python应该怎么实现呢
文档见下图
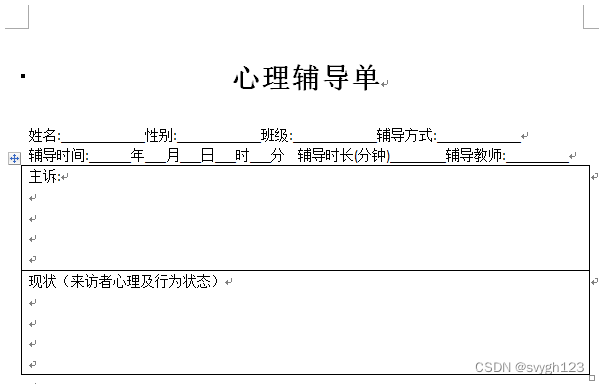
一般情况下,我们在看到题目的时候,应该先审题,看题目中有哪些难点,就是那些比较难以实现的点,比较费时费力的点,比较模糊不清的点,这些点都要提炼出来。
这个题目也是比较简单的,先按照我们常规的人工思想来思考这个问题该怎么解决:
如果是我们人工处理的话,就是单击到姓名后面的下划线,然后输入一个真实姓名,接着另存为另一个文档名字就可以了。
那如果要程序应该怎么处理呢?
通过之前的文章我们知道,python+selenium是可以录制操作步骤进行自动化操作的,这是一个解决问题的思路,通过录制操作步骤导出代码进行修改可以实现。
但是这种方式比较繁琐,通过查找资料,python有第三方库可以处理word:python-docx
官网例子:
```python
# 导入docx库中的Document类和Inches类
from docx import Document
from docx.shared import Inches
# 创建一个Document对象
document = Document()
# 添加一个标题,级别为0
document.add_heading('文档标题', 0)
# 添加一个段落,内容为"A plain paragraph having some "
p = document.add_paragraph('A plain paragraph having some ')
# 在段落中添加加粗文本"bold"
p.add_run('bold').bold = True
# 在段落中添加普通文本" and some "
p.add_run(' and some ')
# 在段落中添加斜体文本"italic."
p.add_run('italic.').italic = True
# 添加一个一级标题
document.add_heading('Heading, level 1', level=1)
# 添加一个引用样式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
# 添加一个无序列表项
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
# 添加一个有序列表项
document.add_paragraph(
'first item in ordered list', style='List Number'
)
# 添加一张图片,宽度为1.25英寸
document.add_picture('monty-truth.png', width=Inches(1.25))
# 定义一个记录列表,包含三个元组,每个元组包含三个元素:数量、ID和描述
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
# 添加一个表格,1行3列
table = document.add_table(rows=1, cols=3)
# 获取表格的第一行单元格
hdr_cells = table.rows[0].cells
# 设置第一行单元格的文本内容
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
# 遍历记录列表,为表格添加行和单元格,并设置单元格的文本内容
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
# 添加一个分页符
document.add_page_break()
# 保存文档为demo.docx
document.save('demo.docx')
```最终效果:

最后来看看我们带下划线的word怎么处理:
from docx import Document
# 打开原始文档
doc = Document('doc.docx')
# 遍历文档中的所有段落
for para in doc.paragraphs:
# 寻找包含“姓名:”的段落
if '姓名:' in para.text:
# 提取姓名行的文本
text = para.text
# 查找“姓名:”和“性别:”的位置
name_start = text.find('姓名:') + len('姓名:')
underscore_index = text.find('_', name_start) # 找到姓名后的下划线位置
gender_start = text.find('性别:') # 找到“性别:”的位置
# 确保下划线和“性别:”都存在
if underscore_index != -1 and gender_start != -1:
# 计算插入位置和原有姓名(不包括下划线)
insert_pos = underscore_index
original_name = text[name_start:underscore_index].strip()
# 清除原有段落内容
para.clear()
# 重新构建段落内容
# 先添加“姓名:”及原姓名部分直到下划线前
para.add_run(f'姓名:{original_name}')
# 在下划线正上方插入真实姓名(这里以"张三"为例,请替换为实际姓名)
real_name = "张三"
para.add_run(real_name).underline = True # 保持下划线样式
# 继续添加下划线和剩余的文本,注意处理下划线和“性别:”之间的空白
para.add_run('_' + text[underscore_index+1:gender_start].strip())
# 添加“性别:”及其之后的内容
para.add_run(text[gender_start:])
# 保存到新文档
doc.save('newdoc.docx')最终效果:
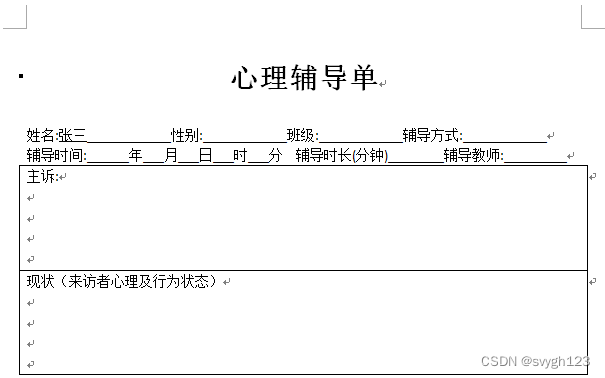
问题来源:
















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











