






导读
本文将介绍为什么要提取最长转录本,以及如何从 fasta和gff3文件中提取最长转录本。
1. Why
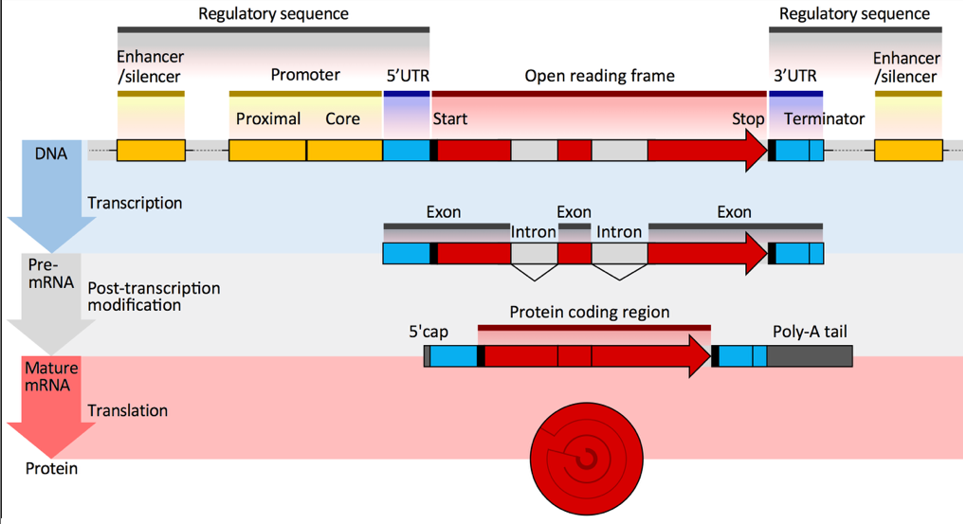
由于可变剪切的存在,通常一个基因可以转录为多个转录本。但是如果将多个转录本同时进行分析,那么分析会因此受到影响。所以,目前的解决办法是,选取一个最具代表性的转录本(最长转录本)来进行分析。
2. 获取方式
-
从序列文件中( FASTA)提取 -
从基因结构注释信息文件( GFF)中提取
3. 用法
-
安装 GetTransTool [1]
pip install GetTransTool -i https://pypi.tuna.tsinghua.edu.cn/simple
-
从 GENCODE fasta文件中提取最长转录本
GetLongestTransFromGencode --file example.fa.gz --outfile longest_trans_gencode.fa
# --file 序列文件
# --outfile 输出文件
-
根据 GFF文件(gencode/ensembl/ucsc)提取最长转录本
GetLongestTransFromGTF --database ensembl --gtffile example.gtf.gz --genome example.fa.gz --outfile longest_trans_ensembl.fa
# --database 基因组注释时,选择的数据库
# --gtffile 注释文件
# --genome 基因组序列文件
# --outfile 输出文件
-
从 GENCODE fasta文件中提取最长CDS
GetCDSLongestFromGencode --file example.fa.gz --outfile longest_cds_trans_gencode.fa
# --file 序列文件
# --outfile 输出文件
-
根据 GFF文件(gencode/ensembl/ucsc)提取最长CDS
GetCDSLongestFromGTF --database ensembl --gtffile example.gtf.gz --genome example.fa.gz --outfile longest_trans_ensembl.fa
# --database 基因组注释时,选择的数据库
# --gtffile 注释文件
# --genome 基因组序列文件
# --outfile 输出文件
-
最长转录本,输出结构示例:
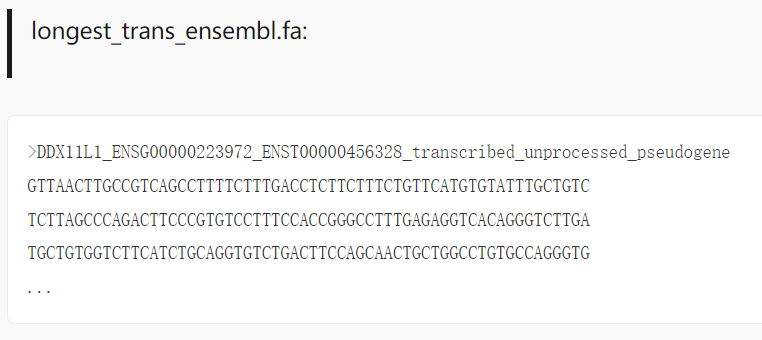
-
最长 CDS,输出结构示例:
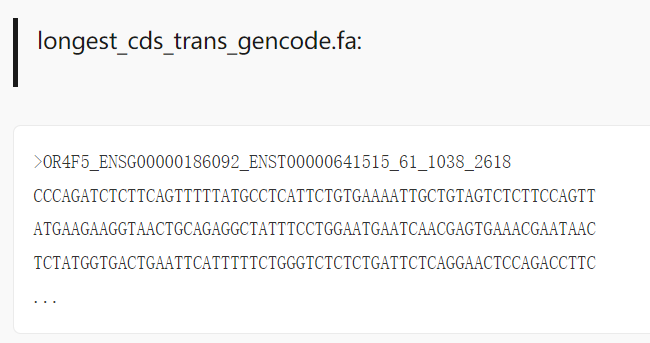
4. code
代码过长,下面只展示部分。
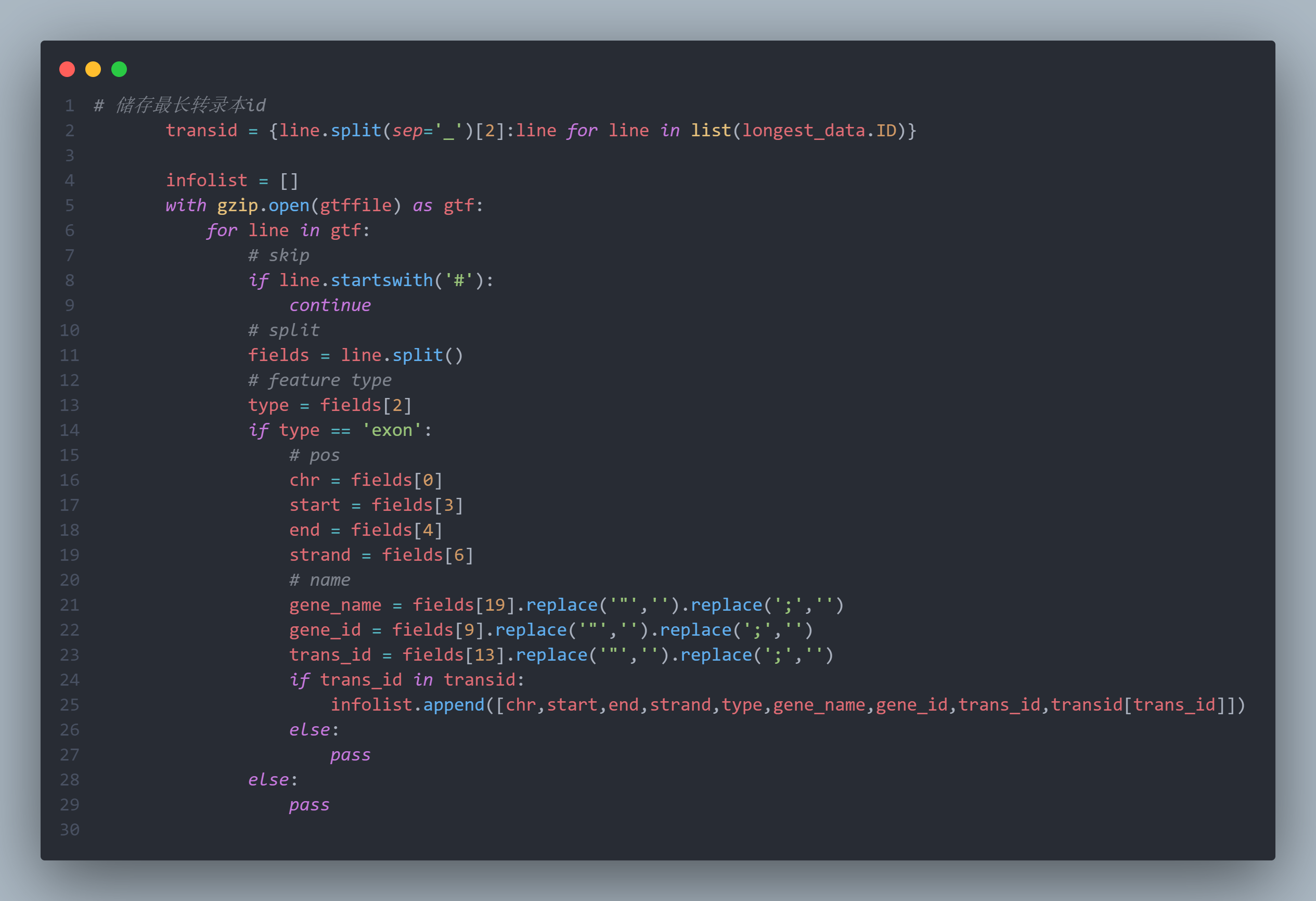
参考资料
GetTransTool: https://github.com/junjunlab/GetTransTool
本文由 mdnice 多平台发布















 6776
6776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









