






Python网络爬虫-Requests库及实战示例
1.Requests库
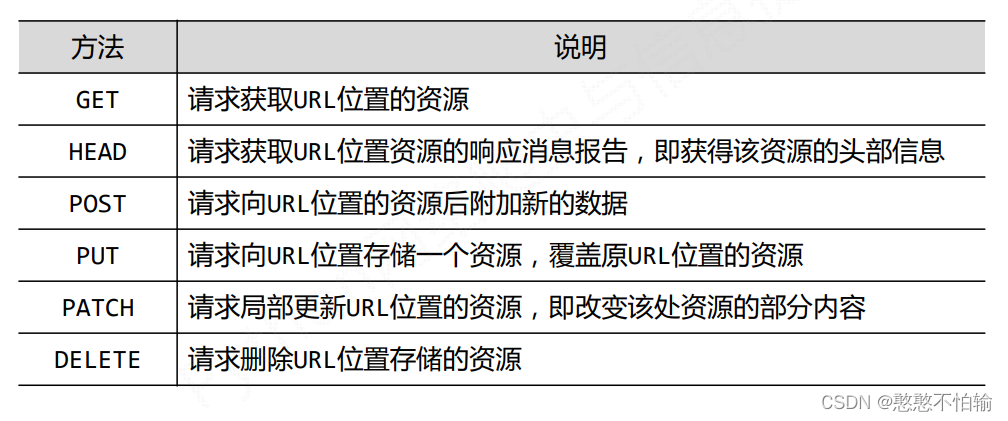
1.1Requests库的7个主要方法:
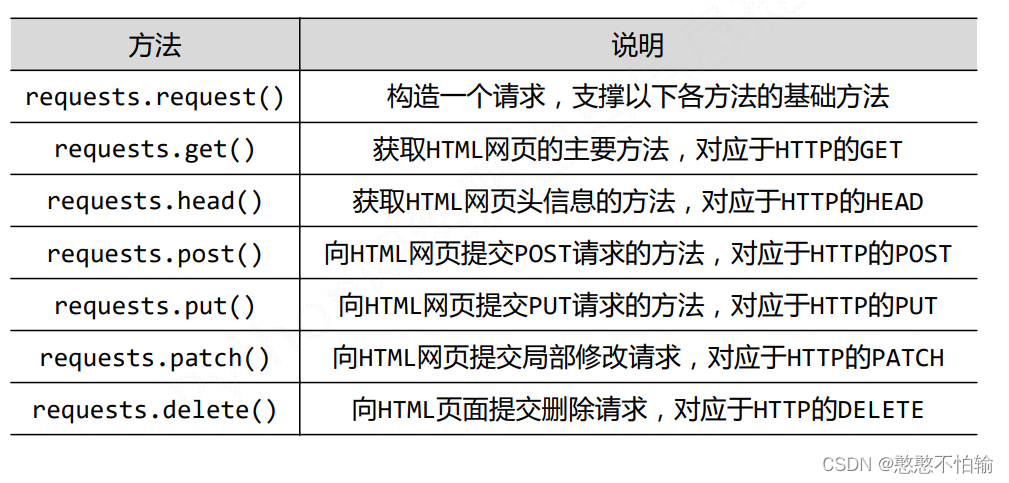
1.1.1requests.get()

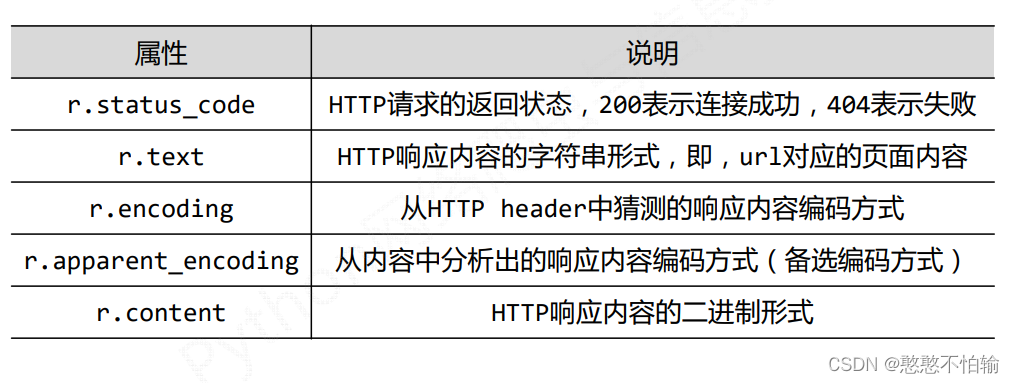
1.1.2Response
其中Response对象的属性有以下5种:
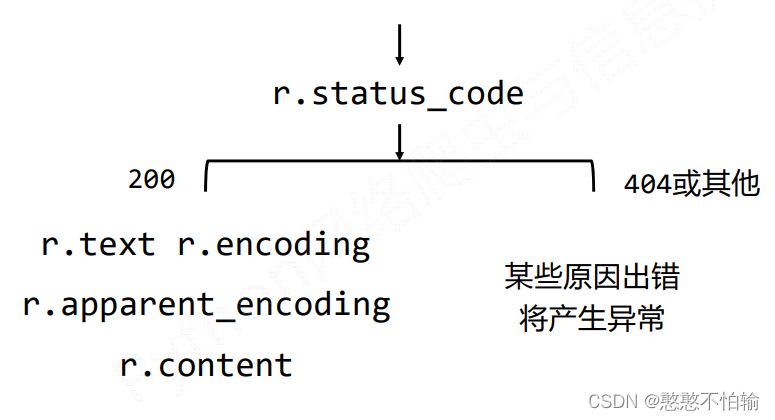
通过r.status_code返回http请求状态,当输出为200时可以进行Response其他4个属性的输入;当输出为404(非200时),表示由某些原因出错产生异常,以下以图解形式呈现:
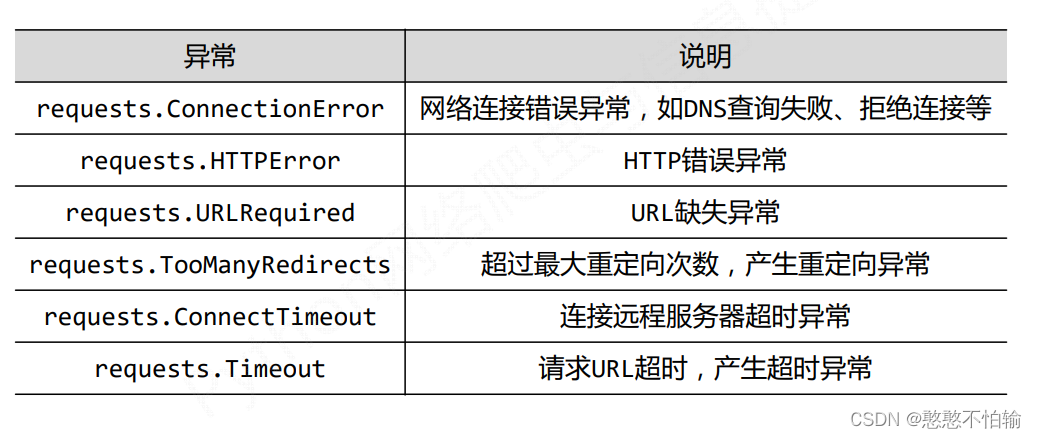
下面为Response编码解析:

1.2爬取网页的通用代码框架
1.2.1Requests库异常
1.2.2爬取网页的通用代码框架
下面代码框架中try‐except是进行异常处理;

1.3 http协议以及对网络资源的操作
1.3.1http协议是什么


1.3.2http协议对资源的操作

http协议对资源的操作:
理解patch与put的区别,以下给出一个例子:

2.网络爬虫爬取原则
2.1网络爬虫的尺寸

2.2网络爬虫的限制
-
来源审查:User‐Agent
检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问
-
发布公告:Robots协议
告知所有爬虫网站的爬取策略,要求爬虫遵守
3.Requests库网络爬取实战
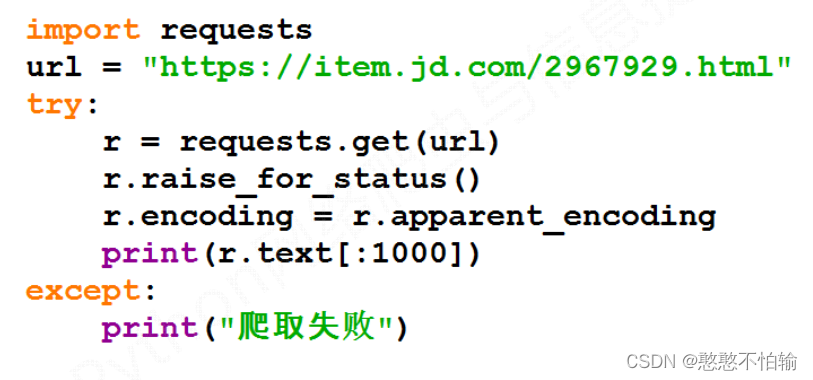
3.1京东商品页面的爬取
以下为代码示例:
3.2亚马逊商品商品的爬取
这里User-Agent会检测出来python requests库从而禁止爬取,所以要修改http协议头,下面为代码示例:

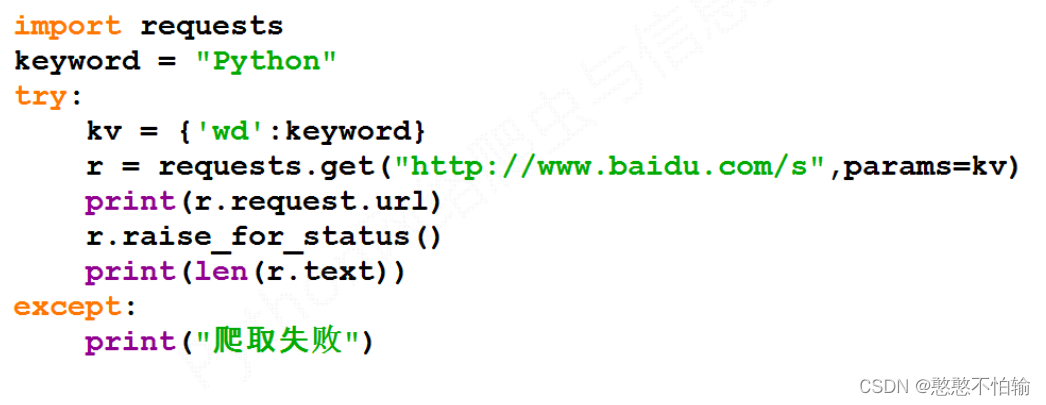
3.3百度搜索关键词提交
我们先了解百度关键词接口构成:

由此我们只需要指定wd指向的keyword,keyword及我们想要查询的关键词,程序运行结束后会有url链接,点击之后则会看到你所爬取的关键词的所有内容,下面是代码示例:
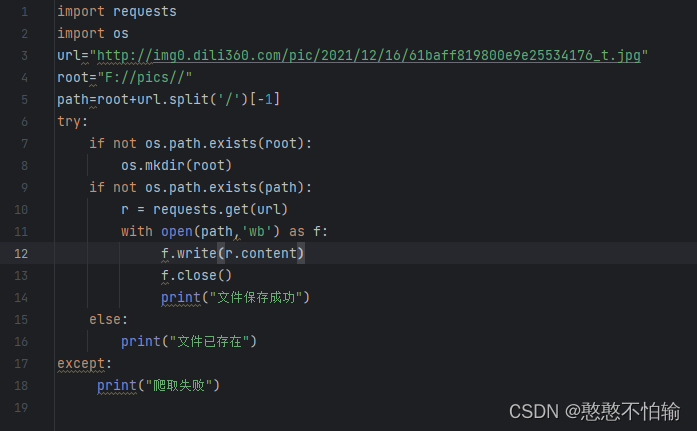
3.4网络图片的爬取和存储
第5行代码含义是将url最后一个斜杠后是内容作为存储图片的文件名;try内的代码含义为先判断这个图片是否存在在你的存储路径中,如果没有则通过网络爬取并将文件保存。















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









