






不同框架下跑yolov10(pt、onnx_runtime、tensorrt) (qq.com)
一,搭建环境
1.1 我的配置版本(不同配置对应版本不同)
CUDA==11.0.287cuDNN==8.2.1python==3.8.8TensorRT==8.6.1
1.2 检查python版本

1.3 创建虚拟环境
conda create -n yolov10_tensorrt python=3.8.81.4 检查CUDA版本(安装步骤跳过)
cat /usr/local/cuda/version.txt![]()
1.5 安装、检查cuDNN版本
1.5.1 下载 cudnn安装包
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse805-111wget https://developer.download.nvidia.com/compute/machine-learning/cudnn/secure/8.2.1.32/11.3_06072021/cudnn-11.3-linux-x64-v8.2.1.32.tgz?RZMmLfhVPnobSebC_z9Ro-Uo5IIgyDjLkyPUVoYN2cFEV1EoXY2YjuV-4vEmzyekKluqukwNMQu_sDnBwo5XU--BakKOtGiC3QKYnUxiuf-IT2O8UdLxQeu2NdGJsXdHxmkNZr1zJNpIKPS_mnLB017zWGaG2QP2wcu42TgSNm-ylmvUwPQp3k3c6av0hJ7i2_K5HeCBM-Pb89vGmpM=&t=eyJscyI6IndlYnNpdGUiLCJsc2QiOiJsaW5rLnpoaWh1LmNvbS8/dGFyZ2V0PWh0dHBzJTNBLy9kZXZlbG9wZXIubnZpZGlhLmNvbS9yZHAvY3Vkbm4tYXJjaGl2ZSUyM2EtY29sbGFwc2U4MDUtMTExIn0=
1.5.2 解压文件
tar -xvf cudnn-11.3-linux-x64-v8.2.1.32.tgz1.5.3 将解压后的头文件和库复制到cuda目录中:
cd cudasudo cp include/cudnn* /usr/local/cuda/includesudo cp lib64/libcudnn* /usr/local/cuda/lib64sudo chmod a+r /usr/local/cuda/include/cudnn* /usr/local/cuda/lib64/libcudnn*# 环境变量配置vim ~/.bashrc# 新增一行export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64# 保存并退出source ~/.bashrc
1.5.4 cuDNN安装完成,查看安装的版本:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
1.6 安装pycuda
虚拟环境里执行conda install 可安装成功
conda install -c conda-forge pycuda1.7 安装:TensorRT
1.7.1 下载TensorRT
官网下载(需要简单注册登录):
https://developer.nvidia.com/tensorrt-downloadwget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.6.1/tars/TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz下载文件:TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz
1.7.2 安装TensorRT
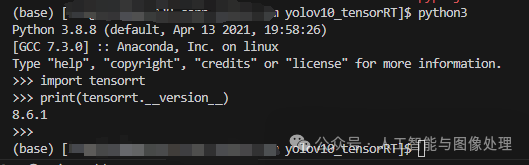
## step 1# 解压cd ./TensorRT_ONNXtar -xzvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz# 生成新目录 TensorRT-8.6.1.6 ## step 2 # 环境变量配置vim ~/.bashrc# 新增export LD_LIBRARY_PATH=./TensorRT_ONNX/TensorRT-8.6.1.6/lib:$LD_LIBRARY_PATHexport PATH=./TensorRT_ONNX/TensorRT-8.6.1.6/bin:$PATHexport LIBRARY_PATH=./TensorRT_ONNX/TensorRT-8.6.1.6/lib:$LIBRARY_PATH # 保存并退出source ~/.bashrc ## step 3cd ./TensorRT_ONNX/TensorRT-8.6.1.6/pythonpip3 install tensorrt-8.6.1-cp38-none-linux_x86_64.whl ## step 4 验证安装正确性python3import tensorrtprint(tensorrt.__version__)
号外:以上安装步骤完成后,只能在非虚拟环境里找到tensorrt,想要在虚拟环境中也能引入tensorrt,参考下面的链接:
https://blog.csdn.net/threestooegs/article/details/126097476即将base环境中的tensorrt拷贝到虚拟环境中,注意base环境和虚拟环境的python版本要一致
cp -r ./tools/anaconda3/lib/python3.8/site-packages/tensorrt ./tools/anaconda3/envs/yolov10_tensorrt/lib/python3.8/site-packages1.8 下载yolov10代码,安装yolov10环境
这部分不是必须的,你只要能安装运行需要的库就行,但是一个一个安装不是缺这个就是少那个,还不如一键安装。git clone https://github.com/THU-MIG/yolov10
cd yolov10pip install -r requirements.txtpip install -e .
二,运行推理

测试图片
2.1 pt推理
2.1.1 使用pt模型预测代码
from ultralytics import YOLOv10import globimport osimport numpy as npimport cv2import timeclasses = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush']class Colors:"""Ultralytics color palette https://ultralytics.com/."""def __init__(self):"""Initialize colors as hex = matplotlib.colors.TABLEAU_COLORS.values()."""hexs = ('FF3838', '00C2FF', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB','2C99A8', 'FF9D97', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')self.palette = [self.hex2rgb(f'#{c}') for c in hexs]# print(self.palette)self.n = len(self.palette)def __call__(self, i, bgr=False):"""Converts hex color codes to rgb values."""c = self.palette[int(i) % self.n]return (c[2], c[1], c[0]) if bgr else c@staticmethoddef hex2rgb(h): # rgb order (PIL)return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))colors = Colors() # create instance for 'from utils.plots import colors'imgpath = r'./TensorRT_ONNX/yolov10_onnx_rknn_horizon_tensorRT/yolov10/figures'modelpath = r'./TensorRT_ONNX/yolov10_onnx_rknn_horizon_tensorRT/yolov10/models/yolov10n.pt'save_dir = imgpath + '_Rst2'os.makedirs(save_dir,exist_ok=True)model = YOLOv10(modelpath)imgs = glob.glob(os.path.join(imgpath,'*.jpg'))for img in imgs:imgname = img.split('/')[-1]frame = cv2.imread(img)start_time = time.time()results = model.predict(img)[0]end_time = time.time()elapsed_time = end_time - start_timeprint(f"The elapsed time is {elapsed_time} seconds.")# results = model(img)for box in results.boxes:# print(box)xyxy = box.xyxy.squeeze().tolist()x1, y1, x2, y2 = int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])c, conf = int(box.cls), float(box.conf)name = classes[c]color = colors(c, True)cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), color, thickness=2, lineType=cv2.LINE_AA)cv2.putText(frame, f"{name}: {conf:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, color,2)# cv2.imshow('image', frame)# cv2.waitKey(0)print(save_dir+'/'+imgname)cv2.imwrite(save_dir+'/'+imgname,frame)
2.1.2 使用pt模型预测时间
运行成功,推理一张图需要0.468s

2.1.3 使用pt模型预测结果

下载onnx,tensorrt推理代码
git clone https://github.com/cqu20160901/yolov10_onnx_rknn_horizon_tensorRT2.2 onnx推理
2.2.1 使用onnx模型预测代码
#!/usr/bin/env python3# -*- coding:utf-8 -*-import argparseimport osimport sysimport cv2import numpy as npimport onnxruntime as ortfrom math import expimport timeCLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush']meshgrid = []class_num = len(CLASSES)head_num = 3strides = [8, 16, 32]map_size = [[80, 80], [40, 40], [20, 20]]object_thresh = 0.4input_height = 640input_width = 640topK = 50class DetectBox:def __init__(self, classId, score, xmin, ymin, xmax, ymax):self.classId = classIdself.score = scoreself.xmin = xminself.ymin = yminself.xmax = xmaxself.ymax = ymaxdef GenerateMeshgrid():for index in range(head_num):for i in range(map_size[index][0]):for j in range(map_size[index][1]):meshgrid.append(j + 0.5)meshgrid.append(i + 0.5)def TopK(detectResult):if len(detectResult) <= topK:return detectResultelse:predBoxs = []sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True)for i in range(topK):predBoxs.append(sort_detectboxs[i])return predBoxsdef sigmoid(x):return 1 / (1 + exp(-x))def postprocess(out, img_h, img_w):print('postprocess ... ')detectResult = []output = []for i in range(len(out)):output.append(out[i].reshape((-1)))scale_h = img_h / input_heightscale_w = img_w / input_widthgridIndex = -2cls_index = 0cls_max = 0for index in range(head_num):reg = output[index * 2 + 0]cls = output[index * 2 + 1]for h in range(map_size[index][0]):for w in range(map_size[index][1]):gridIndex += 2if 1 == class_num:cls_max = sigmoid(cls[0 * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w])cls_index = 0else:for cl in range(class_num):cls_val = cls[cl * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w]if 0 == cl:cls_max = cls_valcls_index = clelse:if cls_val > cls_max:cls_max = cls_valcls_index = clcls_max = sigmoid(cls_max)if cls_max > object_thresh:regdfl = []for lc in range(4):sfsum = 0locval = 0for df in range(16):temp = exp(reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w])reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][ 1] + w] = tempsfsum += tempfor df in range(16):sfval = reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w] / sfsumlocval += sfval * dfregdfl.append(locval)x1 = (meshgrid[gridIndex + 0] - regdfl[0]) * strides[index]y1 = (meshgrid[gridIndex + 1] - regdfl[1]) * strides[index]x2 = (meshgrid[gridIndex + 0] + regdfl[2]) * strides[index]y2 = (meshgrid[gridIndex + 1] + regdfl[3]) * strides[index]xmin = x1 * scale_wymin = y1 * scale_hxmax = x2 * scale_wymax = y2 * scale_hxmin = xmin if xmin > 0 else 0ymin = ymin if ymin > 0 else 0xmax = xmax if xmax < img_w else img_wymax = ymax if ymax < img_h else img_hbox = DetectBox(cls_index, cls_max, xmin, ymin, xmax, ymax)detectResult.append(box)# topKprint('before topK num is:', len(detectResult))predBox = TopK(detectResult)return predBoxdef precess_image(img_src, resize_w, resize_h):image = cv2.resize(img_src, (resize_w, resize_h), interpolation=cv2.INTER_LINEAR)image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = image.astype(np.float32)image /= 255.0return imagedef detect(img_path):orig = cv2.imread(img_path)start_time = time.time()img_h, img_w = orig.shape[:2]image = precess_image(orig, input_width, input_height)image = image.transpose((2, 0, 1))image = np.expand_dims(image, axis=0)ort_session = ort.InferenceSession('./yolov10n_zq.onnx')pred_results = (ort_session.run(None, {'data': image}))out = []for i in range(len(pred_results)):out.append(pred_results[i])predbox = postprocess(out, img_h, img_w)end_time = time.time()execution_time = end_time - start_time # 得到执行时间,单位为秒print("execution_time:",execution_time)print('after topk num is :', len(predbox))for i in range(len(predbox)):xmin = int(predbox[i].xmin)ymin = int(predbox[i].ymin)xmax = int(predbox[i].xmax)ymax = int(predbox[i].ymax)classId = predbox[i].classIdscore = predbox[i].scorecv2.rectangle(orig, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)ptext = (xmin, ymin + 10)title = CLASSES[classId] + "%.2f" % scorecv2.putText(orig, title, ptext, cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2, cv2.LINE_AA)cv2.imwrite('./test_onnx_result.jpg', orig)if __name__ == '__main__':print('This is main ....')GenerateMeshgrid()img_path = './test.jpg'detect(img_path)
2.2.1 使用onnx模型预测时间
运行成功,推理一张图需要0.39s

2.2.2 使用onnx模型预测结果

2.3 tensorrt推理
2.3.1 使用tensorrt模型预测代码
import cv2import numpy as npimport tensorrt as trtimport pycuda.driver as cudaimport pycuda.autoinitfrom math import expfrom math import sqrtimport timenp.bool = np.bool_TRT_LOGGER = trt.Logger(trt.Logger.VERBOSE)CLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light','fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee','skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple','sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch','potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear','hair drier', 'toothbrush']meshgrid = []class_num = len(CLASSES)head_num = 3strides = [8, 16, 32]map_size = [[80, 80], [40, 40], [20, 20]]object_thresh = 0.4input_height = 640input_width = 640topK = 50# Simple helper data class that's a little nicer to use than a 2-tuple.class HostDeviceMem(object):def __init__(self, host_mem, device_mem):self.host = host_memself.device = device_memdef __str__(self):return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)def __repr__(self):return self.__str__()def allocate_buffers(engine):inputs = []outputs = []bindings = []stream = cuda.Stream()for binding in engine:size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_sizedtype = trt.nptype(engine.get_binding_dtype(binding))# Allocate host and device buffershost_mem = cuda.pagelocked_empty(size, dtype)device_mem = cuda.mem_alloc(host_mem.nbytes)# Append the device buffer to device bindings.bindings.append(int(device_mem))# Append to the appropriate list.if engine.binding_is_input(binding):inputs.append(HostDeviceMem(host_mem, device_mem))else:outputs.append(HostDeviceMem(host_mem, device_mem))return inputs, outputs, bindings, streamdef get_engine_from_bin(engine_file_path):print('Reading engine from file {}'.format(engine_file_path))with open(engine_file_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:return runtime.deserialize_cuda_engine(f.read())# This function is generalized for multiple inputs/outputs.# inputs and outputs are expected to be lists of HostDeviceMem objects.def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):# Transfer input data to the GPU.[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]# Run inference.context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)# Transfer predictions back from the GPU.[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]# Synchronize the streamstream.synchronize()# Return only the host outputs.return [out.host for out in outputs]class DetectBox:def __init__(self, classId, score, xmin, ymin, xmax, ymax):self.classId = classIdself.score = scoreself.xmin = xminself.ymin = yminself.xmax = xmaxself.ymax = ymaxdef GenerateMeshgrid():for index in range(head_num):for i in range(map_size[index][0]):for j in range(map_size[index][1]):meshgrid.append(j + 0.5)meshgrid.append(i + 0.5)def TopK(detectResult):if len(detectResult) <= topK:return detectResultelse:predBoxs = []sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True)for i in range(topK):predBoxs.append(sort_detectboxs[i])return predBoxsdef sigmoid(x):return 1 / (1 + exp(-x))def postprocess(out, img_h, img_w):print('postprocess ... ')detectResult = []output = []for i in range(len(out)):output.append(out[i].reshape((-1)))scale_h = img_h / input_heightscale_w = img_w / input_widthgridIndex = -2cls_index = 0cls_max = 0for index in range(head_num):reg = output[index * 2 + 0]cls = output[index * 2 + 1]for h in range(map_size[index][0]):for w in range(map_size[index][1]):gridIndex += 2if 1 == class_num:cls_max = sigmoid(cls[0 * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w])cls_index = 0else:for cl in range(class_num):cls_val = cls[cl * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w]if 0 == cl:cls_max = cls_valcls_index = clelse:if cls_val > cls_max:cls_max = cls_valcls_index = clcls_max = sigmoid(cls_max)if cls_max > object_thresh:regdfl = []for lc in range(4):sfsum = 0locval = 0for df in range(16):temp = exp(reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w])reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][ 1] + w] = tempsfsum += tempfor df in range(16):sfval = reg[((lc * 16) + df) * map_size[index][0] * map_size[index][1] + h * map_size[index][1] + w] / sfsumlocval += sfval * dfregdfl.append(locval)x1 = (meshgrid[gridIndex + 0] - regdfl[0]) * strides[index]y1 = (meshgrid[gridIndex + 1] - regdfl[1]) * strides[index]x2 = (meshgrid[gridIndex + 0] + regdfl[2]) * strides[index]y2 = (meshgrid[gridIndex + 1] + regdfl[3]) * strides[index]xmin = x1 * scale_wymin = y1 * scale_hxmax = x2 * scale_wymax = y2 * scale_hxmin = xmin if xmin > 0 else 0ymin = ymin if ymin > 0 else 0xmax = xmax if xmax < img_w else img_wymax = ymax if ymax < img_h else img_hbox = DetectBox(cls_index, cls_max, xmin, ymin, xmax, ymax)detectResult.append(box)# topKprint('before topK num is:', len(detectResult))predBox = TopK(detectResult)return predBoxdef preprocess(src_image, input_width, input_height):image = cv2.resize(src_image, (input_width, input_height)).astype(np.float32)image = image * 0.00392156image = image.transpose(2, 0, 1)image = np.ascontiguousarray(image)return imagedef main():engine_file_path = './yolov10n_zq.trt'input_image_path = './test.jpg'orign_image = cv2.imread(input_image_path)image = cv2.cvtColor(orign_image, cv2.COLOR_BGR2RGB)img_h, img_w = image.shape[:2]image = preprocess(image, input_width, input_height)with get_engine_from_bin(engine_file_path) as engine, engine.create_execution_context() as context:inputs, outputs, bindings, stream = allocate_buffers(engine)inputs[0].host = imaget1 = time.time()trt_outputs = do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream, batch_size=1)t2 = time.time()print('run tiems time:', (t2 - t1),"s")print('outputs heads num: ', len(trt_outputs))out = []for i in range(len(trt_outputs)):out.append(trt_outputs[i])predbox = postprocess(out, img_h, img_w)print(len(predbox))for i in range(len(predbox)):xmin = int(predbox[i].xmin)ymin = int(predbox[i].ymin)xmax = int(predbox[i].xmax)ymax = int(predbox[i].ymax)classId = predbox[i].classIdscore = predbox[i].scorecv2.rectangle(orign_image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)title = CLASSES[classId] + "%.2f" % scorecv2.putText(orign_image, title, (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2, cv2.LINE_AA)cv2.imwrite('./test_result_tensorRT.jpg', orign_image)if __name__ == '__main__':print('This is main ...')GenerateMeshgrid()main()
2.3.2 使用tensorrt模型预测时间
运行
python3 yolov10n_onnx_demo_zq.py报错1
AttributeError: ‘tensorrt.tensorrt.Builder‘ object has no attribute ‘max_workspace_size‘ 【转tensorRT】
解决方案:(tensorrt降低版本)
pip install nvidia-tensorrt==7.2.* --index-url https://pypi.ngc.nvidia.com
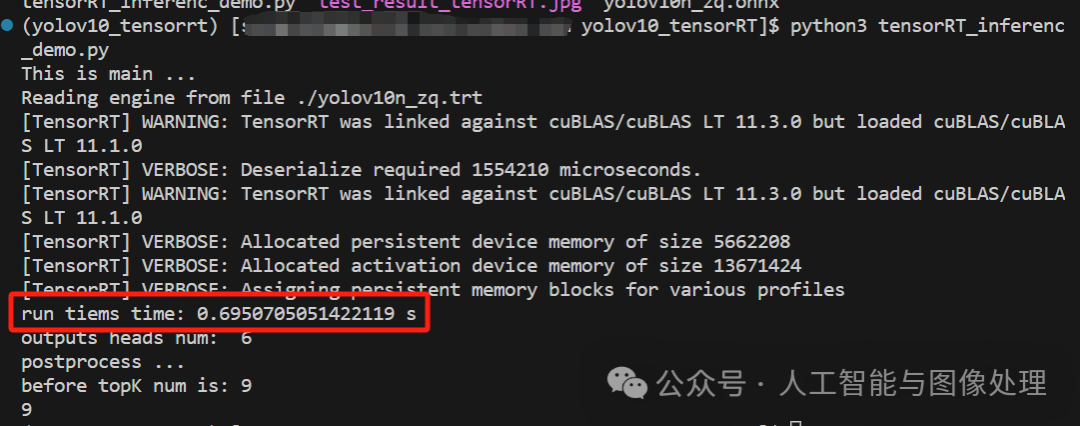
运行成功,推理一张图需要0.69s
2.3.3 使用tensorrt模型预测结果

不知道哪里出了问题,我跑出来的时间和预想的差异还挺大,欢迎一起探讨。















 2023
2023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









