







TensorFlow学习系列:
TensorFlow_1参数初始化方法
TensorFlow_2学习率
TensorFlow_3激活函数
TensorFlow_4正则化
TensorFlow_5dropout
TensorFlow_6断点续训与Tensorboard可视化
TensorFlow_7优化器
TensorFlow_8损失函数
一,概述
在机器学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好。
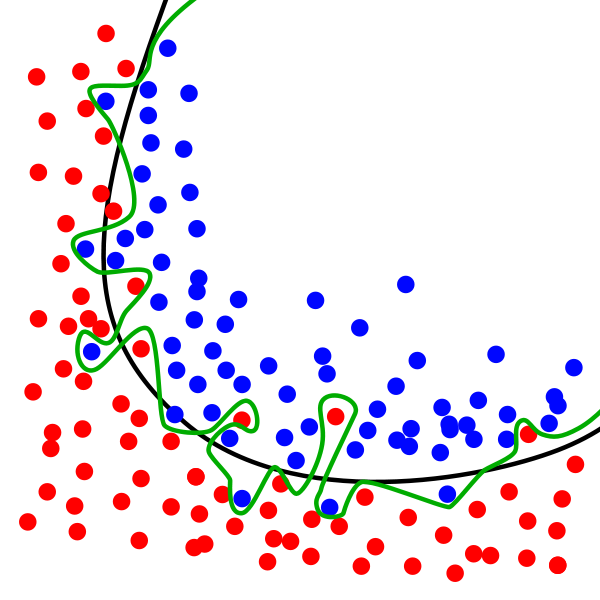
图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差。解决过拟合的方式有:1)增加数据集,2)减少数据特征(一般不采用),3)正则化(上一篇已讲过),4)dropout。这篇文章就说一下通过droupout防止过拟合问题。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。但在测试及验证中:每个神经元都要参加运算,但其输出要乘以概率p。示意图如下:
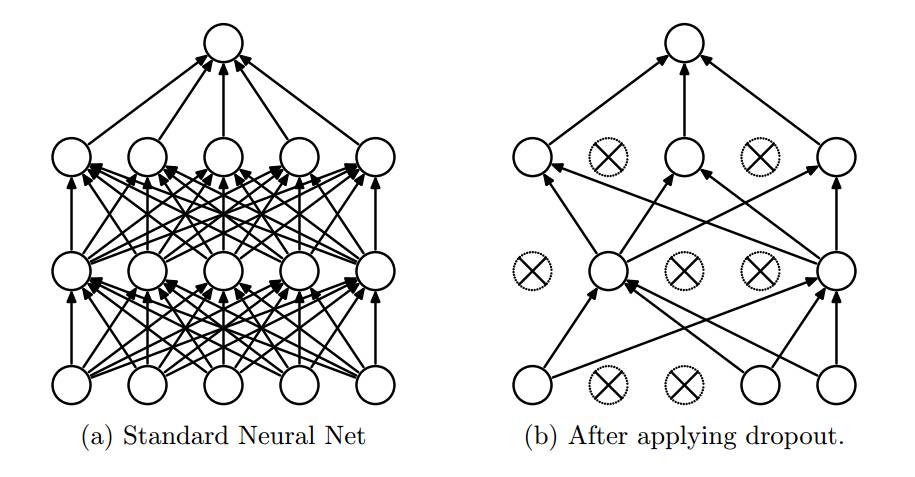
二,TensorFlow中使用tf.nn.dropout函数
def dropout(x, keep_prob, noise_shape=None, seed=None, name=None)输入是:
- x:你自己的训练、测试数据等
- keep_prob:dropout概率
- ……,其它参数不咋用,不介绍了
输出是:
- A Tensor of the same shape of x
注意,输出的非0元素是原来的 “1/keep_prob” 倍!
三,实例
3.1 代码一
import tensorflow as tf
dropout = tf.placeholder(tf.float32) #占位
x = tf.Variable(tf.ones([6, 6])) #定义变量
y = tf.nn.dropout(x, dropout) #定义dropout
init = tf.initialize_all_variables() #初始化变量
sess = tf.Session()
sess.run(init)
print (sess.run(y, feed_dict = {dropout: 1})) #先不进行dropout看输出的是啥结果:

将最后一句代码改为:
print (sess.run(y, feed_dict = {dropout: 0.8}))结果:
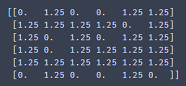
可见:输出的非0元素确是原来的 “1/keep_prob” 倍(1/0.8=1.25)
3.2 代码二
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(1)
np.random.seed(1)
N_SAMPLE = 20
N_HIDDEN = 300
LR = 0.01
x = np.linspace(-1,1,N_SAMPLE)[:,np.newaxis]
y = x+0.3*np.random.randn(N_SAMPLE)[:,np.newaxis]
test_x = x.copy()
test_y = test_x + 0.3*np.random.randn(N_SAMPLE)[:,np.newaxis]
#plt.scatter(x,y,c='magenta',s=50,alpha=0.5,label='train')
plt.scatter(test_x,test_y,c='cyan',s=50,alpha=0.5,label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5,2.5))
plt.show()
tf_x = tf.placeholder(tf.float32,[None,1])
tf_y = tf.placeholder(tf.float32,[None,1])
tf_is_training = tf.placeholder(tf.bool,None)
#overfitting net
o1 = tf.layers.dense(tf_x,N_HIDDEN,tf.nn.relu)
o2 = tf.layers.dense(o1,N_HIDDEN,tf.nn.relu)
o_out = tf.layers.dense(o2,1)
o_loss = tf.losses.mean_squared_error(tf_y,o_out)
o_train = tf.train.AdamOptimizer(LR).minimize(o_loss)
#dropout net
d1 = tf.layers.dense(tf_x,N_HIDDEN,tf.nn.relu)
d1 = tf.layers.dropout(d1,rate=0.5,training = tf_is_training)
d2 = tf.layers.dense(d1,N_HIDDEN,tf.nn.relu)
d2 = tf.layers.dropout(d2,rate=0.5,training = tf_is_training)
d_out = tf.layers.dense(d2,1)
d_loss = tf.losses.mean_squared_error(tf_y,d_out)
d_train = tf.train.AdamOptimizer(LR).minimize(d_loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
plt.ion()
for t in range(500):
sess.run([o_train,d_train],feed_dict={tf_x:x,tf_y:y,tf_is_training:True})
if t%10==0:
plt.cla()
[o_loss_,d_loss_,o_out_,d_out_] = sess.run([o_loss,d_loss,o_out,d_out],
feed_dict = {tf_x:test_x,tf_y:test_y,tf_is_training:False})
plt.scatter(x,y,c='magenta',s=50,alpha=0.3,label='train')
plt.scatter(test_x,test_y,c='cyan',s=50,alpha=0.3,label='test')
plt.plot(test_x,o_out_,'r-',lw=3,label='overfitting')
plt.plot(test_x,d_out_,'b--',lw=3,label='dropout(50%)')
plt.text(0,-1.2,'overfitting loss = %.4f'%o_loss_,fontdict={'size':10,'color':'red'})
plt.text(0,-1.5,'dropout loss=%.4f'%d_loss_,fontdict={'size':10,'color':'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5,2.5))
plt.pause(0.1)
plt.ioff()
plt.show()
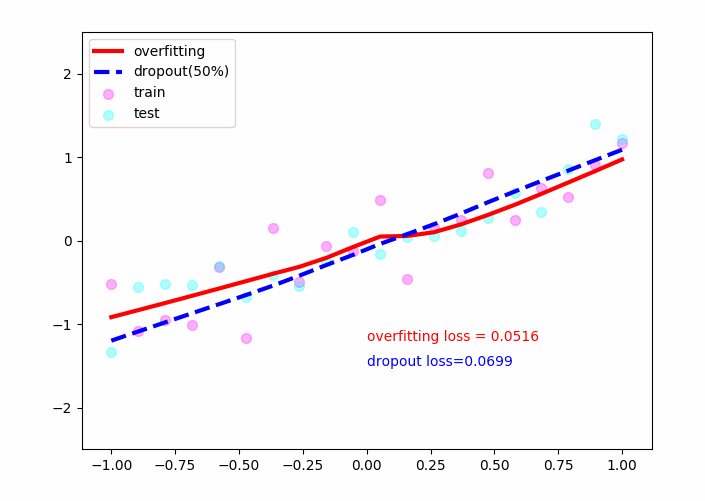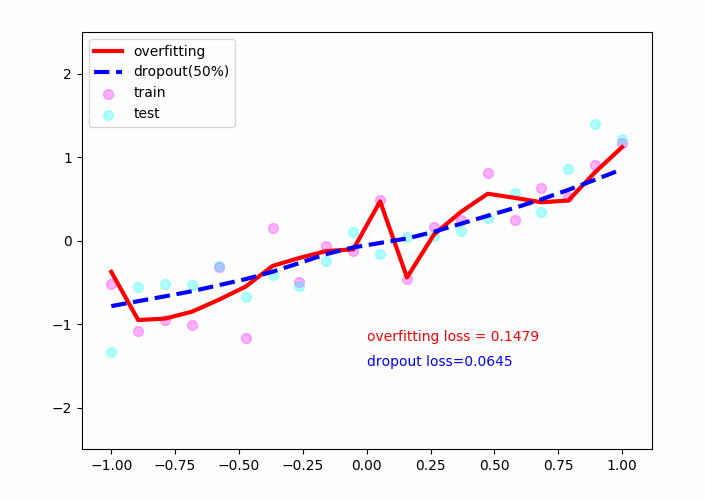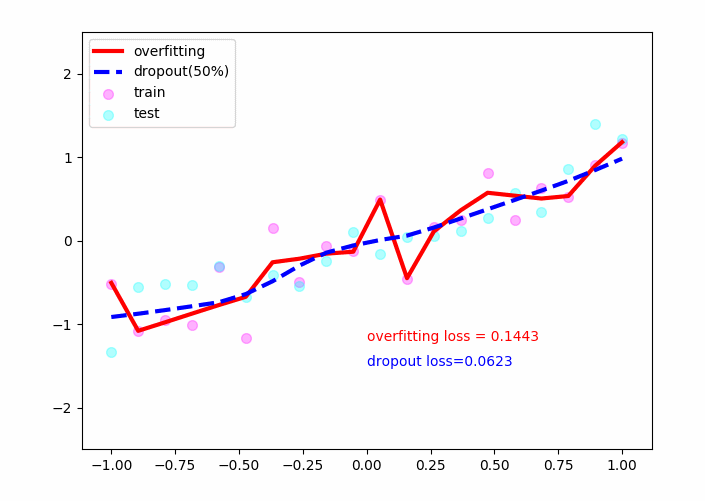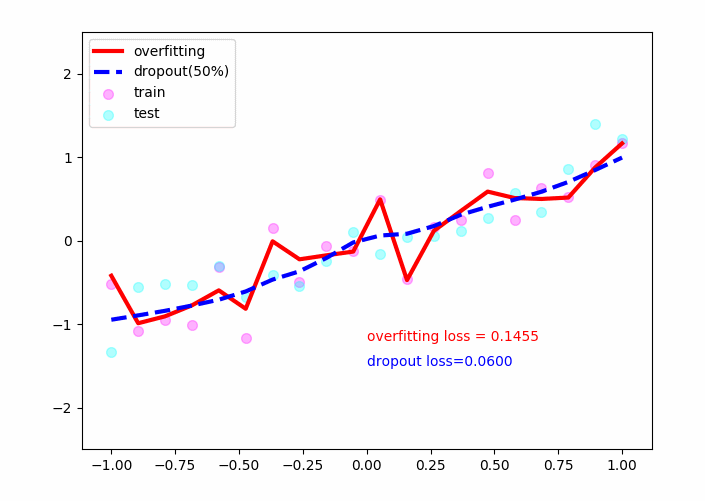
结果:
欢迎扫码关注我的微信公众号
















 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









