







本文首发于微信公众号:人工智能与图像处理
多模态综述(MultiModal Learning) (qq.com)
一,多模态
1.1 模态
模态是指一些表达或感知事物的方式,每一种信息的来源或者形式,都可以称为一种模态。例如:
-
人有触觉,听觉,视觉,嗅觉;
-
信息的媒介,有语音、视频、文字等;
-
多种多样的传感器,如雷达、红外、加速度计等。
以上的每一种都可以称为一种模态。
相较于图像、语音、文本等多媒体(Multi-media)数据划分形式,“模态”是一个更为细粒度的概念,同一媒介下可存在不同的模态。 比如我们可以把两种不同的语言当做是两种模态,甚至在两种不同情况下采集到的数据集,亦可认为是两种模态。
1.2 多模态
多模态即是从多个模态表达或感知事物。 多模态可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,例如图片与文本语言的关系。
多模态可能有以下三种形式:
-
描述同一对象的多媒体数据。如互联网环境下描述某一特定对象的视频、图片、语音、文本等信息。下图即为典型的多模态信息形式。

“下雪”场景的多模态数据(图像、音频与文本)
-
来自不同传感器的同一类媒体数据。如医学影像学中不同的检查设备所产生的图像数据, 包括B超(B-Scan ultrasonography)、计算机断层扫描(CT)、核磁共振等;物联网背景下不同传感器所检测到的同一对象数据等。
-
具有不同的数据结构特点、表示形式的表意符号与信息。如描述同一对象的结构化、非结构化的数据单元;描述同一数学概念的公式、逻辑 符号、函数图及解释性文本;描述同一语义的词向量、词袋、知识图谱以及其它语义符号单元等。
通常主要研究模态包括"3V":即Verbal(文本)、Vocal(语音)、Visual(视觉)。人跟人交流时的多模态:
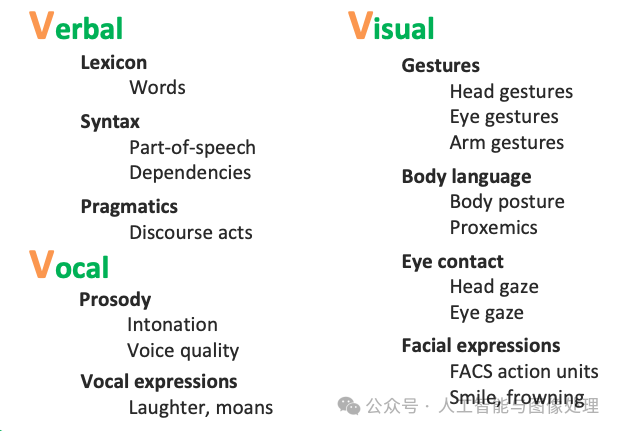
multimodal communicative behaviors
1.3 多模态学习
多模态机器学习是从多种模态的数据中学习并且提升自身的算法,它不是某一个具体的算法,它是一类算法的总称。
从语义感知的角度切入,多模态数据涉及不同的感知通道如视觉、听觉、触觉、嗅觉所接收到的信息;
在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、符号、音频、时间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数据库、不同知识库的各种信息资源的组合。对多源异构数据的挖掘分析可被理解为多模态学习。
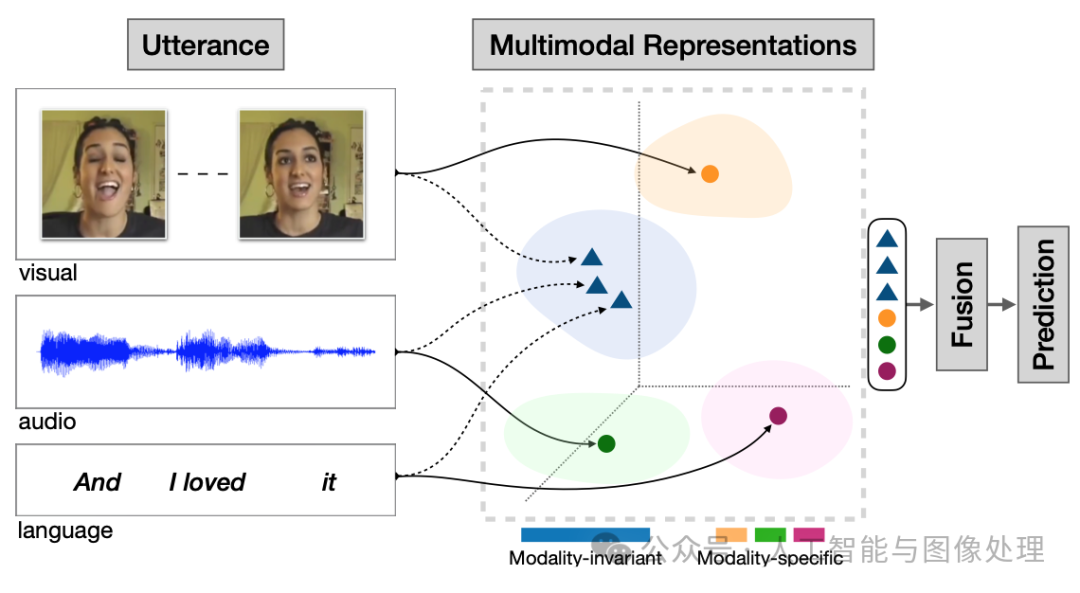
多模态学习举例
1.4 多模态的典型任务
1.4.1 跨模态预训练
-
图像/视频与语言预训练。
-
跨任务预训练
1.4.2 Language-Audio
-
Text-to-Speech Synthesis: 给定文本,生成一段对应的声音。
-
Audio Captioning:给定一段语音,生成一句话总结并描述主要内容。(不是语音识别)
1.4.3 Vision-Audio
-
Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
-
Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
-
Image Generation from Audio: 给定声音,生成与其相关的图像。
-
Speech-conditioned Face generation:给定一段话,生成说话人的视频。
-
Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
1.4.4 Vision-Language
-
Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<-->文本的相互检索。
-
Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
-
Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
-
Image/Video Generation from Text:给定文本,生成相应的图像或视频。
-
Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
-
Vision-and-Language Navigation(视觉-语言导航):给定自然语言进行指导,使得智能体根据视觉传感器导航到特定的目标。
-
Multimodal Dialog(多模态对话):给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
1.4.5 定位相关的任务
-
Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
-
Temporal Language Localization: 给定一个视频即一段文本,定位到文本所描述的动作(预测起止时间)。
-
Video Summarization from text query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频。
-
Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指示的物体。
-
Video-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
-
Object Tracking from Natural Language Query: 给定一段视频和一些文本,追踪视频中文本所描述的对象。
-
Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑。
1.4.6 更多模态
-
Affect Computing (情感计算):使用语音、视觉(人脸表情)、文本信息、心电、脑电等模态进行情感识别。
-
Medical Image:不同医疗图像模态如CT、MRI、PETRGB-D模态:RGB图与深度图
二,图文多模态
由于是讲“图文多模态”,还是要从“图”和“文”的表征方法讲起:
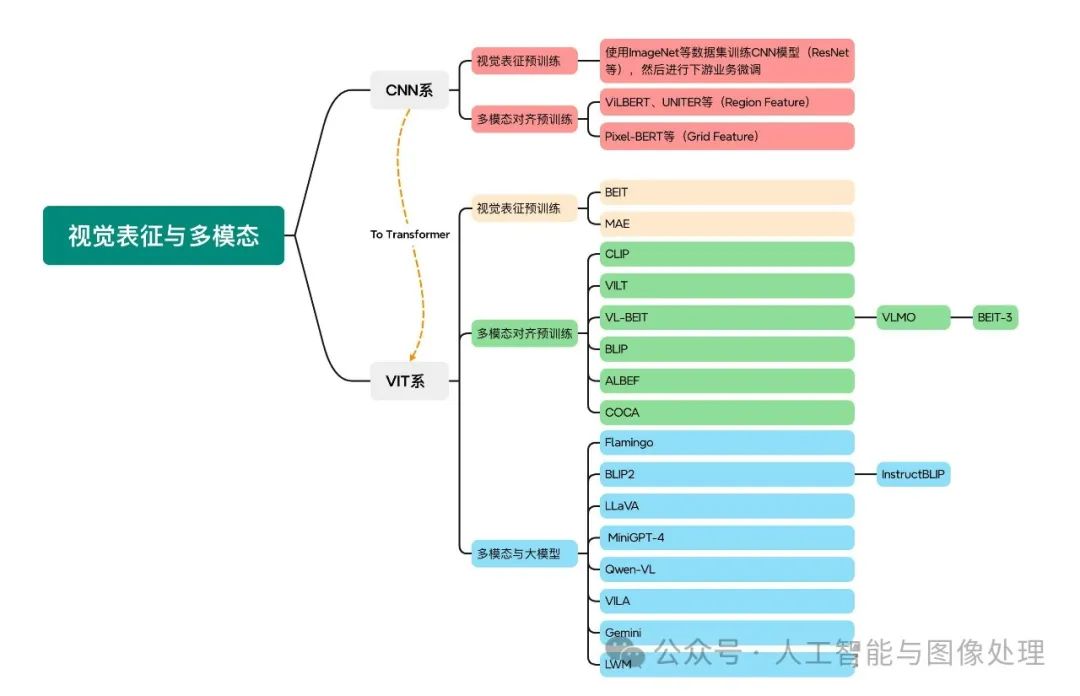
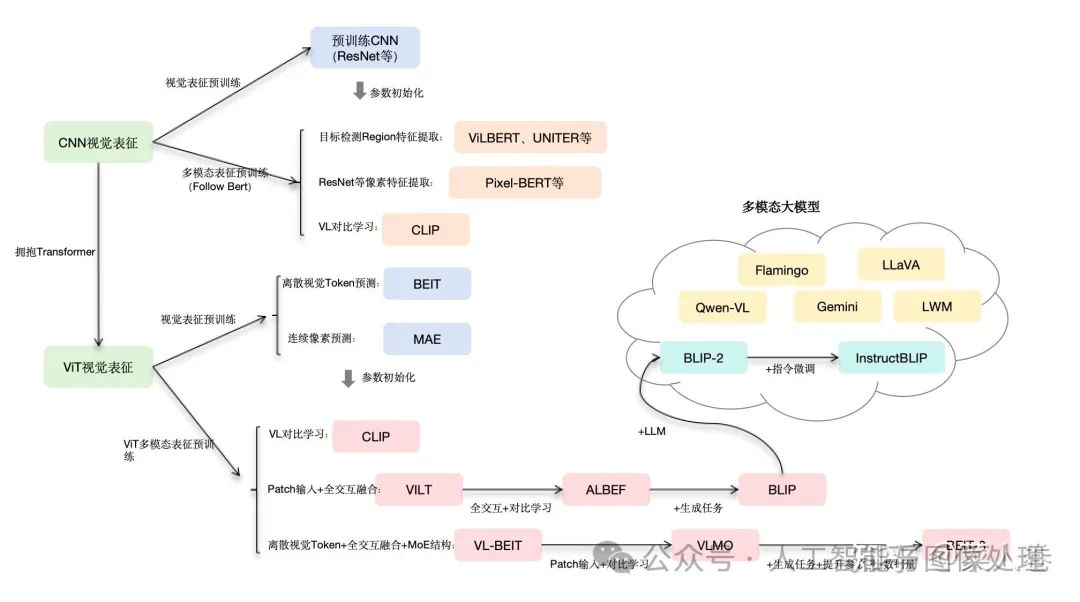
视觉表征:分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础;
对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。
-
以CNN为基础的视觉表征和预训练手段,以及在此基础上的多模态对齐的方法。由于预训练已经成为AI技术取得效果的标配,多模态对齐部分的内容也是以多模态预训练技术承载;
-
对于VIT线,有多模态大模型如火如荼的发展,可谓日新月异。
视觉与自然语言的对齐(Visul Language Alignment)或融合:目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。
三,多模态与大模型
先看下下面两张图:
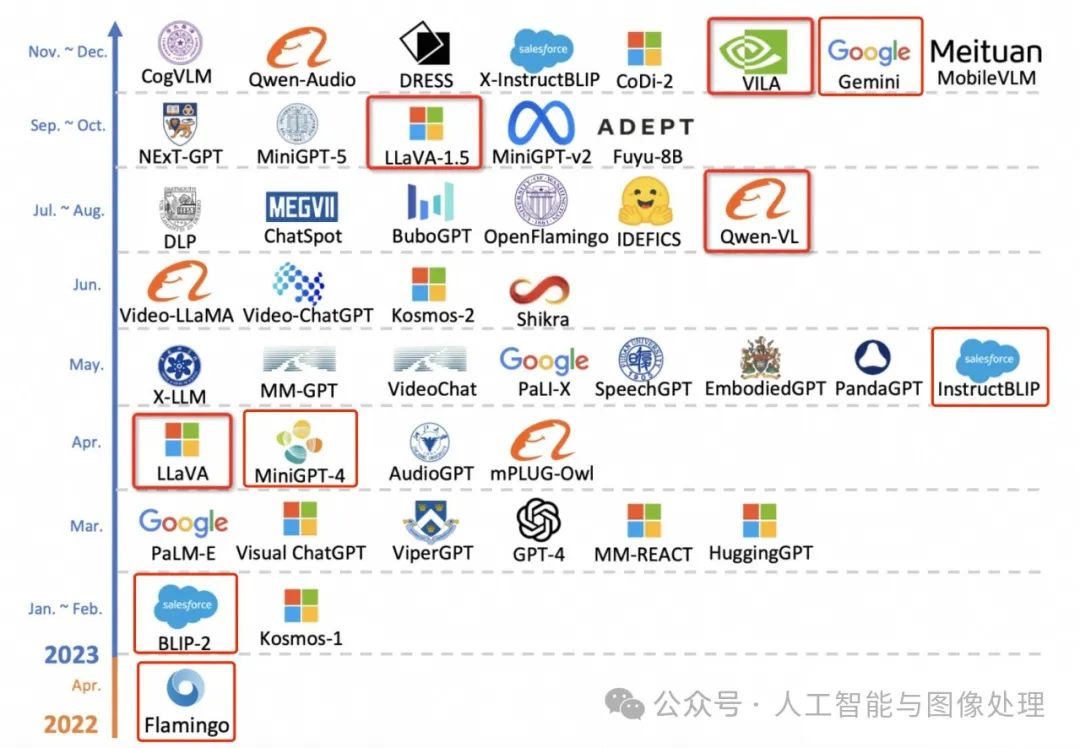
截止2023年10月的大模型
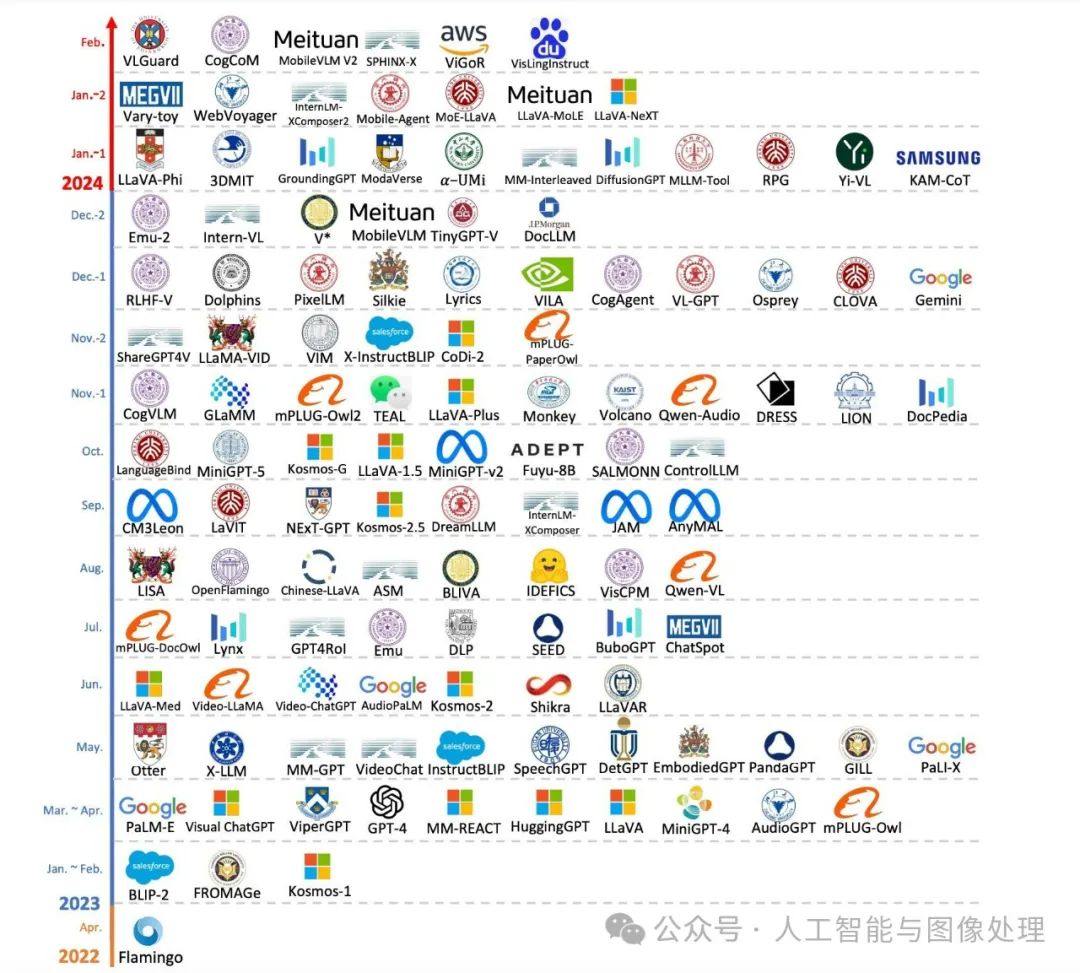
截止2024年2月的大模型
由上面两张图对比可见,短短几个月,增加了非常多的模型,足见这个方向的火热程度。
3.1 Flamingo
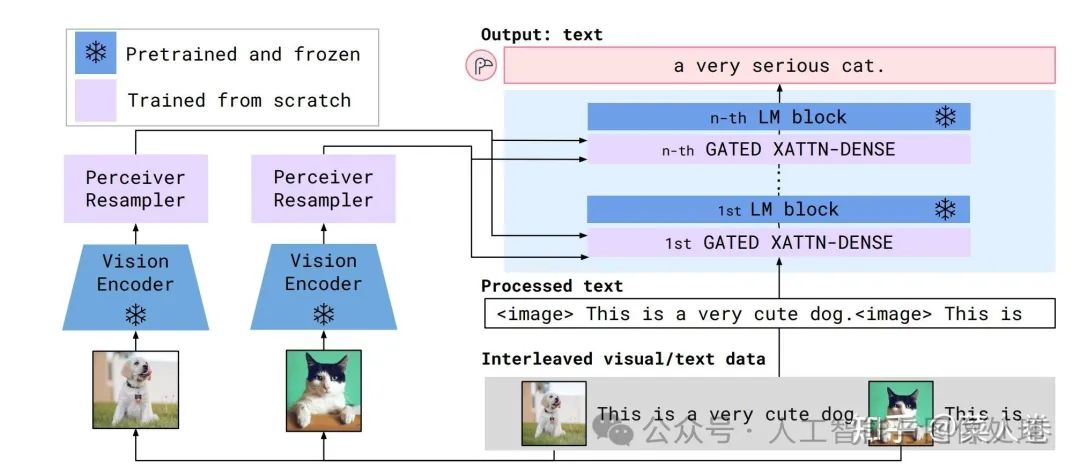
如今GPT-4代表着多模态大模型的顶尖水平,但在此之前,甚至在ChatGPT之前就已有相关探索工作,其中谷歌的Flamingo最具当前主流技术雏形。事实上,Flamingo更像是图文多模态领域的GPT-3,不同的是它支持图文上下文的输入,通过In-Context Few-Shot方式完成任务。Flamingo同样支持视频帧序列作为输入,通过Prompt指令完成Video理解任务。

Flamingo
做到这种功能,在模型侧和GPT-3类似,不同的是Flamingo在文本Transfomer网络中增加视觉输入特征,模型结构如上图所示,包括三个部分:
-
视觉侧特征抽取使用预训练的ResNet和采样模块(Perceiver Resampler,将变长的视觉特征输入转成少量的视觉特征)模型;
-
文本侧模型使用LLM(基座使用Chinchilla,同样是谷歌发布的对标GPT-3的大语言模型,并提供了1.4B、7B、和70B等版本,分别对应Flamingo-3B、Flamingo-9B和Flamingo-80B);
-
GATED XATTN-DENSE层,用于连接LLM 层与视觉特征,允许 LM 在处理文本时考虑视觉信息。通过交叉注意力,LM 可以关注与视觉特征相关的部分。预训练LLM和视觉ResNet参数训练过程中是冻结状态。
相应的,在数据层面Flamingo也是使用了多样形式的训练语聊,包括:
-
图文穿插形式:MultiModal MassiveWeb (M3W),43 Million;
-
图文Pair对形式:LTIP(Long Text & Image Pairs),312 Million;
-
带文本描述的短视频:VTP (Video & Text Pairs) ,27 Million 。
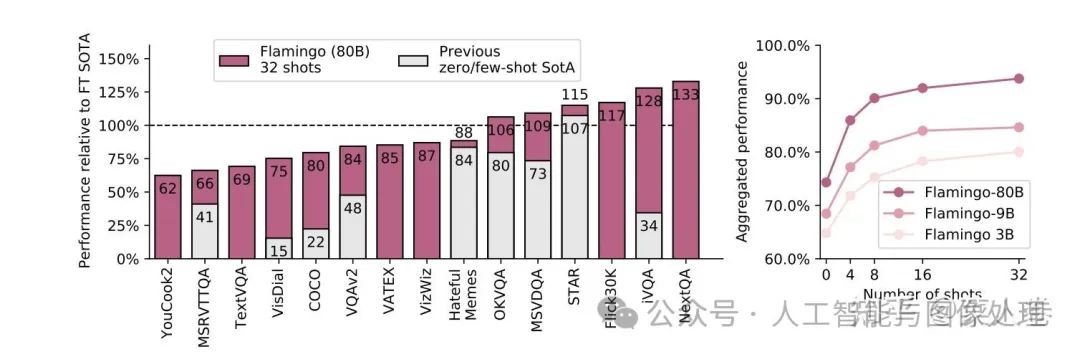
最后Flamingo在各种多模态任务上的效果也非常优秀,甚至在有些数据集上通过few-shot方式可以超过经典模型的SOTA。
Flamingo凭借其出色的效果,吸引了许多研究者对于多模态大模型的注意,但当时这种规模的模型训练不是谁都能玩的起,因此并没有引起特别火热的跟风潮。直到ChatGPT的出现,让人逐渐接受了大模型这条道路的正确性,以前觉得自己玩不起的机构,砸锅卖铁拉投资也愿意投入,自此相关的开源研究开始如火如荼。
在众多开源工作中,BLIP-2以及与之一脉相承的InstructBLIP算是早期的探路者之一,我们可以从这两个工作开始讲起。
3.2 BLIP-2和InstructBLIP
BLIP-2的论文标题是Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,核心思路是通过利用预训练好的视觉模型和语言模型来提升多模态效果和降低训练成本。
BLIP-2的网络结构如下图所示,从架构上来说,和Flamingo十分类似。包括视觉编码层、视觉与文本的Adapter(Q-Former)以及大语言模型层。
-
视觉编码层:使用ViT模型,权重初始化通过CLIP预训练完成,并剔除最后一次提升输出特征的丰富性;训练过程中冻结权重,不更新;
-
文本侧的大语言模型层:早期的BLIP-2使用OPT/FlanT5来实验Decoder based和Encoder-Decoder based LLM的效果;这部分同样在训练过程中冻结权重,不更新;
-
图文Adapter层:Q-Former结构,类似BLIP网络(同样先进行了图文多模态预训练模块),通过Queries向量,提取视觉侧的关键信息输入到LLM;这部分是多模态大模型训练过程中的主要参数。
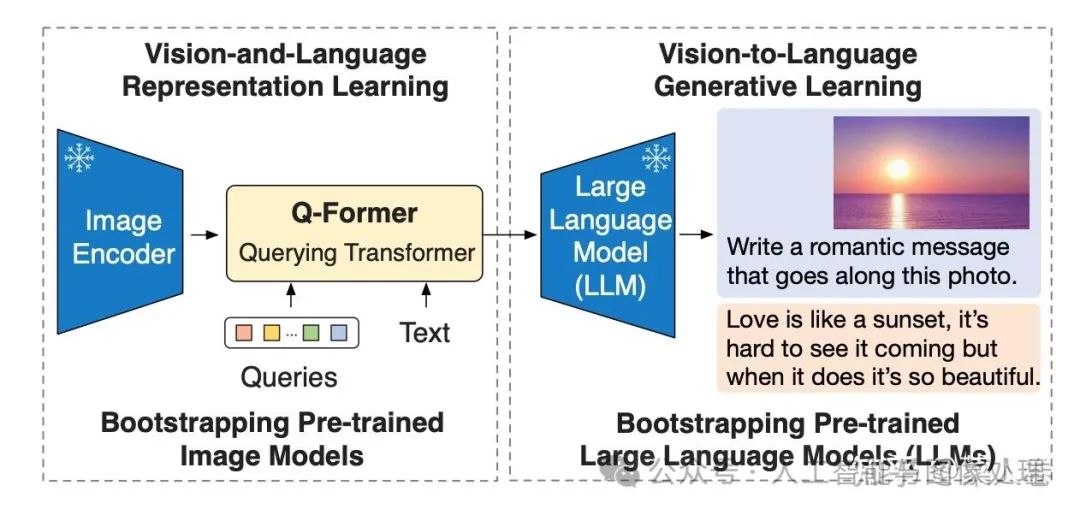
BLIP-2
和Flamingo相比,BLIP-2简化了视觉特征和大模型的交互,直接仅仅将视觉特征和文本特征一起作为大模型的输入,没有深层的交互模块(如GATED XATTN-DENSE层);另一方面在视觉和LLM的Adapter层做了更多的设计,即Q-Former结构,如下图所示。从Q-Former结构图,我们可以看到BLIP的影子,最大的不同在于一个Learned Queries模块,用于对ViT输出的视觉特征进行采样(Pooling),得到固定长度的视觉特征序列。
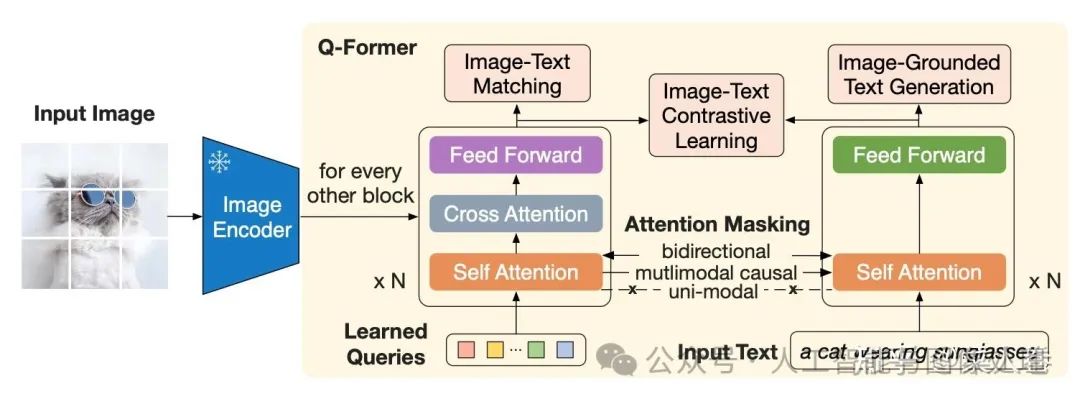
Q-Former结构
上面提到,为了避免灾难遗忘,BLIP-2冻结了ViT和LLM的参数,只训练Q-Former模块。为了训练更加稳定,Q-Former模块的训练包括两个阶段。
-
Stage1: 将Q-Former与冻结的ViT拼接,借鉴BLIP,使用 ITC(图文对比学习)、ITG(图生成文本)和ITM(图文匹配)任务进行学习,对参数进行初始化,学习图文相关性特征。
-
Stage2:如下图,将Stage1得到的模型再拼接LLM,即Q-Former的输出可通过线性投影输入到LLM(冻结参数),进行视觉到自然语言的生成学习,目标是训练Q-Former使其输出的视觉特征和LLM的输入分布对齐。
-

BLIP-2通过视觉和LLM的特征对齐,使得LLM具备了多模态理解能力,但其训练数据主要沿用BLIP(图文Pair对形式),和当下的多模态模型的主流技术方案仍存在一定GAP,是早期代表性探索之一。不过,随着指令微调成为大模型必备流程,后续BLIP-2也自然升级为InstructBLIP。
如下图,InstructBLIP的网络结构与BLIP-2几乎一致,同样也是2阶段训练,不同的是采样了指令微调范式,将文本模态的Instruction也作为输入同时给到Q-former和LLM进行学习。
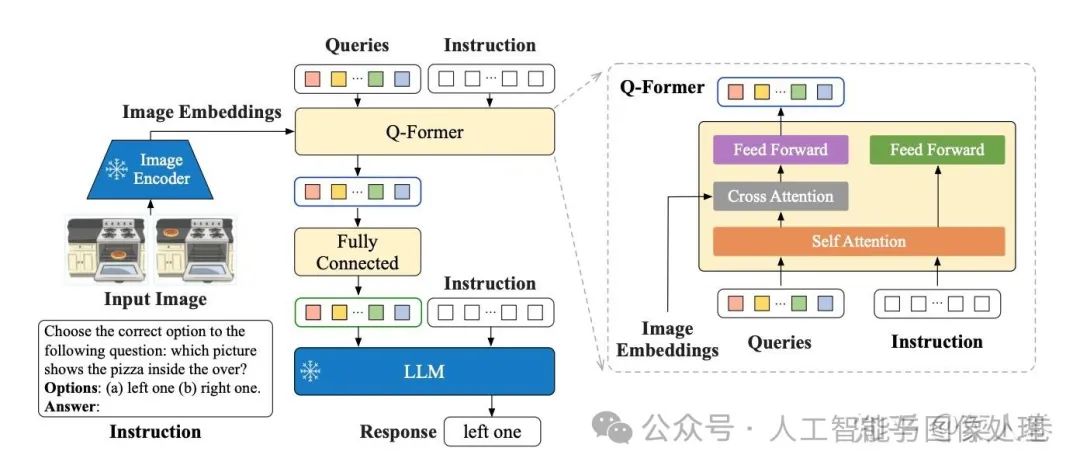
InstructBLIP的网络结构
对应的,InstructBLIP的另一个不同是训练数据也使用指令形式,将各种类型任务的开源学术数据,使用模板构造成指令多模态数据。数据模板如下面表格。
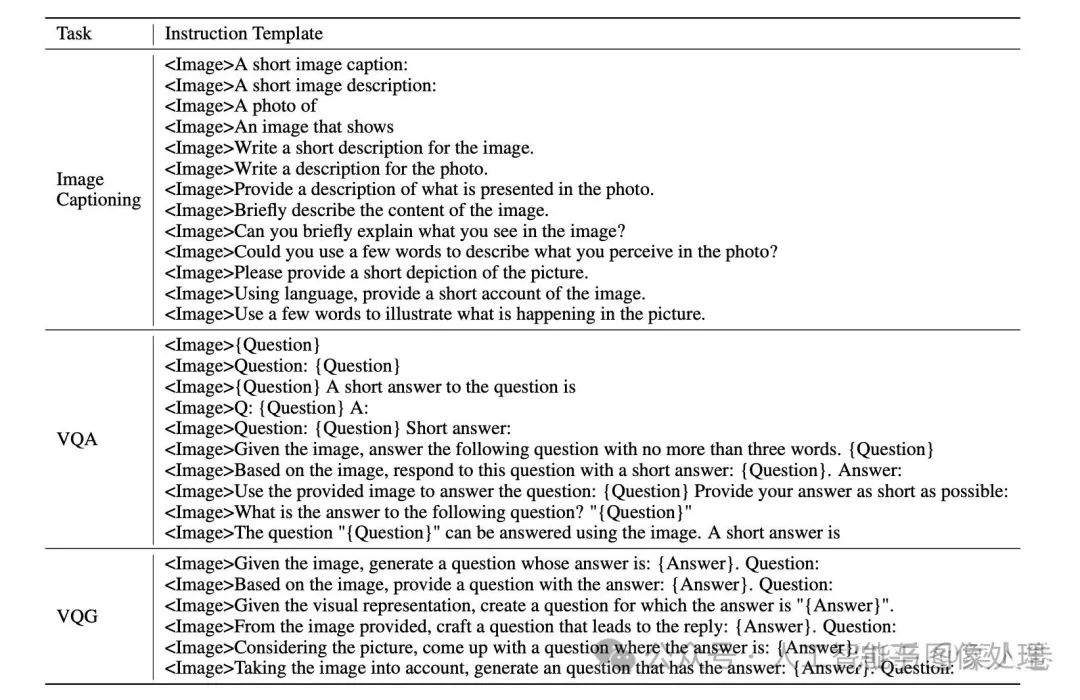
通过指令数据和指令微调,是的InstructBLIP可以像GPT-4一样通过指令提示词的方式完成任务,虽然效果上仍有差距。即使不是InstructBLIP的训练范式并不是开创性的,但是我们依然可以用InstructBLIP作为参考,来看对比后面要介绍的其他工作。
3.3 Qwen-VL
阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。

如下图,Qwen-VL的训练过程分为三个阶段:
-
Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数;
-
Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练;
-
Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。
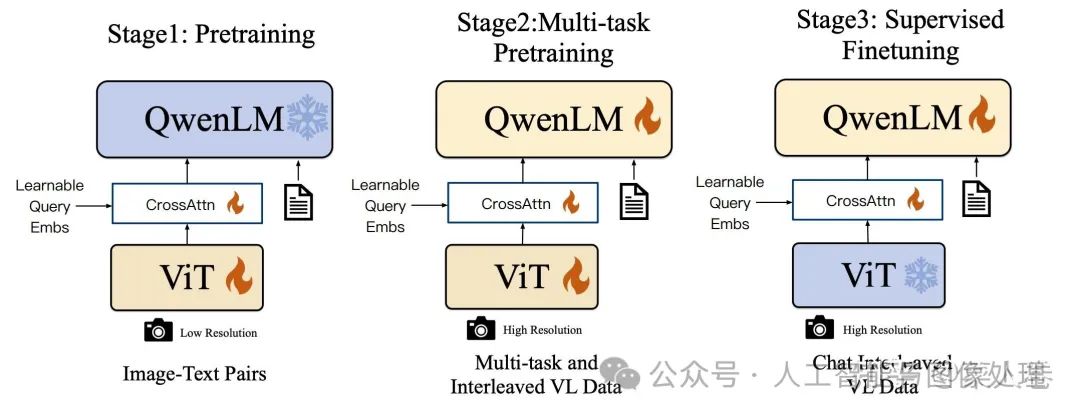
Qwen-VL的训练过程
Qwen-VL的另一个启发是在Stage2和Stage3的训练过程中,不止使用VL数据,还使用了纯文本的训练数据,避免遗忘LLM的能力,这个策略的效果在其他的工作中也有所印证。此外,相比InstructBLIP,Qwen-VL模型视觉和LLM的Adapter模块简化很多,仅仅是一个浅层的Attention Pooling模块,通过更加细节的训练流程和更加丰富的训练数据,仍取得了比InstructBLIP更优的效果。
3.4 LLaVA1.5
同样,微软的LLaVA也是一个持续更新的系列工作,这里主要总结LLaVA和LLaVA1.5的核心思路。下图为LLaVA1.5的数据和模型概况。可以看到,和Qwen-VL相比,LLaVA1.5在预训练和指令微调数据上使用了更少的数据(将Qwen-VL的Stage2和Stage3都视作指令微调);在模型结构上,除了视觉Encoder和LLM均使用了不同的基座模型,视觉和自然语言的Adapter使用更简单的MLP层。
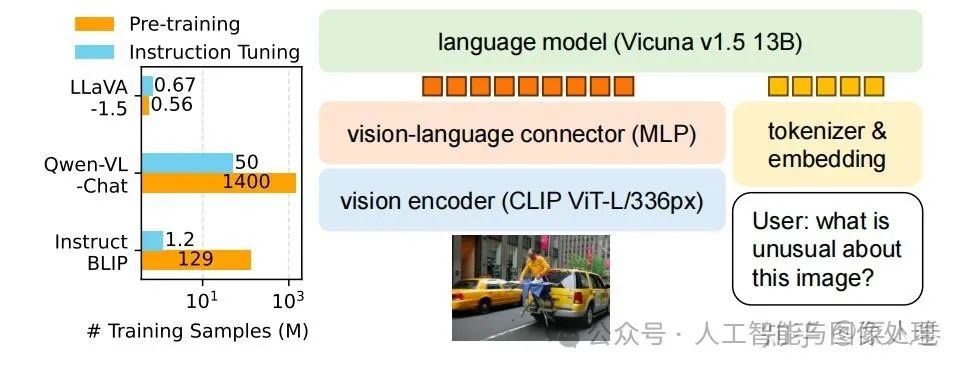
LLaVA1.5的数据和模型概况
LLaVA1.5模型的效果在一些评测数据集上相比Qwen-VL有更好的效果,说明通过一些优化工作,使用更少的数据,更简单的Adapter结构,也能使LLM具备不错的多模态理解能力。在数据层面,如下表,对比LLaVA1.5和LLaVA工作,通过增加高质量细粒度的VL数据、丰富指令、纯文本指令微调数据、提升图片输入像素、提升LLM参数规模等手段,可以有效提升模型效果。
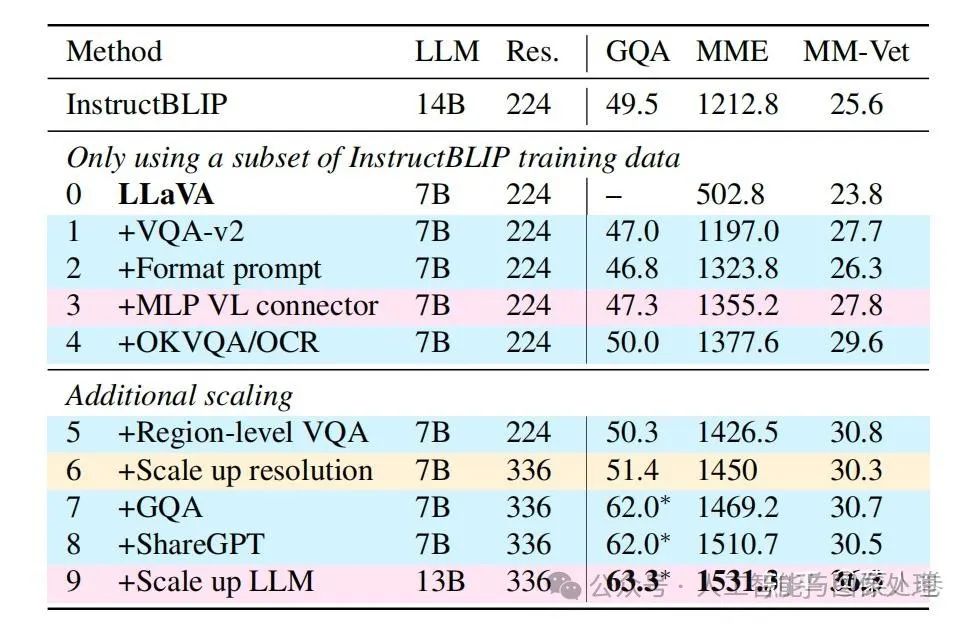
3.5 VILA
另一个与LLaVA比较类似,但有所补充的工作是英伟达的VILA(不是显卡)。VILA模型的网络结构和LLaVA十分类似。不同的是VILA通过实验,总结了多模态预训练的一些经验,其中有些经验在相关工作中也有所体现,主要为以下三点:
-
LLM参与训练更好:在预训练阶段冻结LLM参数,能做到不错的zero-shot的能力,但会损失in-context学习的能力,而LLM参数参与训练的话可以有效缓解;
-
预训练数据使用图文交替数据更好:图文Pair对并不是最优的选择,图文交错的数据效果更好;
-
SFT时纯文本数据图文数据混合更好:在图文指令微调训练数据中混入纯文本的指令数据,不仅可以缓解纯文本能力的遗忘,还能提升VL任务的能力。
具体的,如下图,VILA的训练分为3个阶段,视觉编码模块ViT参数均是冻结状态。
-
Step 0 使用图文Pair数据对初始化Projector(图文Adapter)参数,LLM模块参数冻结;
-
Step 1 使用图文交替数据全参数预训练;
-
Step 2 使用指令微调数据进行全参数微调,其中微调数据混合了图文指令和纯文本指令;
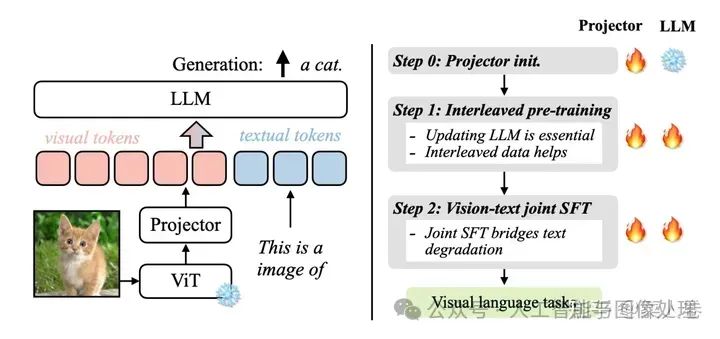
VILA的训练分为3个阶段
VILA是较新的工作,因此有更丰富的模型效果对比,如下表,相对各时期的SoTA,VILA在公开评测指标上有不错的效果。
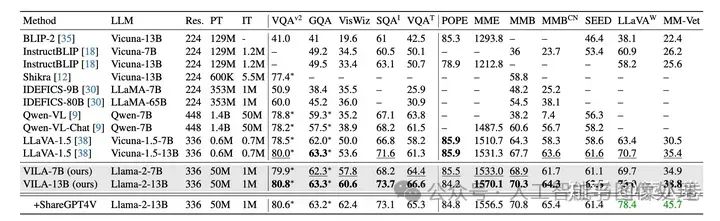
VILA在公开评测指标上有不错的效果
3.6 Gemini 1.0和Gemini 1.5
目光来到闭源世界,与VILA同阶段,谷歌公司发布了Gemini系列,又在近期发布了性能更强的Gemini 1.5,可惜被另一个热爱闭源的OpenAI的Sora抢了风头,属实悲催。由于Gemini系列并没有开源,我们只能通过技术报告中的简单介绍来了解其方法。
Gemini 1.0是一个多模态模型,这里模态除了图图像和文还包括音频、视频,符合谷歌多模态大模型一贯的ALL IN ONE的风格,这也是依赖积累丰富的数据资源和算力资源。Gemini 1.0提供Ultra、Pro和Nano版本,分别适应不同能力、参数大小和推理速度要求,最小的Nano甚至可以端上运行。
方法上,Gemini 1.0的网络结构同样是Transformer Decoders,支持32K上下文长度,使用了Multi-Query Attention等优化机制。如下图,模型输入可以是文本、音频、视觉输入,输入视觉可以是图片、图表、截图、PDFs或视频等,输出可以是图片和文本(没错,可以生成图片)。视觉的Encoder模块借鉴了谷歌自己的Flamingo、CoCa和PaLI,结合这些模型,可以输入多模态的同时,也可以通过离散的视觉Tokens生成图片或视频等视觉模态。
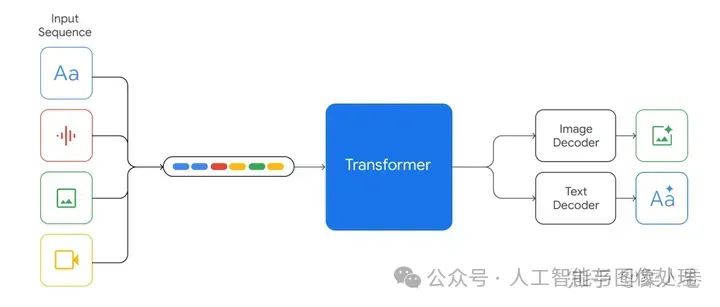
对于音频模态,Gemini可以直接输入Universal Speech Model (USM)的16kHz特征,具体可以参考USM工作。对于视频理解,Gemini通过将视频编码为长上下文窗口中的一系列帧来实现。视频帧或图像可以与文本或音频自然交织在一起,作为模型输入的一部分。Gemini同时支持不同像素输入的视觉以满足不同粒度的理解任务。
在具体训练数据方面,技术报告同样并没有提过多细节,只是简单说了数据包括什么模态、经过了什么清洗步骤等,我们也不再深究。至于最近的Gemini 1.5,同样是技术报告的形式发布,没有特别多技术细节,主要介绍了模型是如何的强。区别要点包括:模型在Gemini 1.0基础上引入了sparse mixture-of-expert (MoE),同时强化了上下文长度(32K->10M)同时几乎没有损失上下文感知能力。在训练过程中,Gemini 1.5强化了指令微调过程,使用了用户偏好数据。
总体来说,虽然Gemini没有提供技术细节,但也体现了谷歌对于多模态大模型技术方向的判断,比如我们可以get到网络结构的MoE、一个模型更多模态、超长上下文、文本生成+多模态生成结合等。
3.7 LWM
最后,我们再介绍一篇和Gemini类似的开源工作《World Model on Million-Length Video And Language With RingAttention》,模型名LWM(Large World Model)。至于为什么叫World Model,意思可以通过视觉和视频的理解物理世界,LWM是UC Berkeley最近发布的一篇工作,个人认为在开源方向上是一个优秀的工作,但好像也是由于Sora和Gemini 1.5的热度,没有引起太多关注。
LWM希望完成的任务和Gemini十分相似,核心是超长上下文理解的多模态大模型。凭借支持1M的token输入,LWM可以对超过一小时的视频进行理解,在Gemini 1.5之前几乎是多模态大模型中最长的上下文输入(之一)。LWM的主要工作要点包括:
-
支持超长上下文,可处理超长的文本、图片序列或视频等;
-
一些技术难点方案:Masked Sequence Packing方法混合的输入长度;通过loss weighting 平衡视觉和文本模态;模型自动生成长序列问答数据集用于模型训练;
-
实现了高性能的RingAttention,Masked Sequence Packing等优化项,完成了百万级别长度的多模态序列的训练;
-
开源7B参数规模的大模型,包括长上下文的文本模态模型(LWM-Text,LWM-Text-Chat),和多模态模型(LWM,LWM-Chat)。
具体方案上,LWM使用Transformer架构,在LLama2 7B基础上扩充上下文理解的长度上限,模型结构如下图:

LWM架构图
与之前大多数方法不同的是,视觉的编码器使用VQGAN,可以将256 × 256输入图片编码成16 × 16 离散Token。这使得LWM不仅可以生成文本,也可以基于文本生成Image Token还原成视频。对于多图或视频帧,可以分别做视觉特征抽取,和文本模态一起输入到LLM中。
在模型训练流程上,主要分为两个阶段的训练:
-
阶段一,使用Books数据集,先扩充文本LLM上下文长度到1M;
-
阶段二,长上下文的多模态训练,即混合图-文数据、视频-文本数据、以及纯文本的Books数据进行训练。
上面两个过程有两个核心问题需要解决:
-
1、长文档的可扩展训练;
-
2、如何稳定地扩展LLM的上下文。
前者关注训练的效率和开销,后者则关注长上下文拓展的有效性。
-
针对问题1,LWM主要实现了高效的RingAttention,同时结合了FlashAttention;
-
针对问题2,一方面,两个训练阶段都是多轮训练方式,逐步提升上下文长度的方式,如下图所示。另一方面通过简单的调整了RoPE的 Q参数,提升模型长文本的位置编码能力。

总的来说,LWM是一篇不错的文章,最重要的是开源,技术方案基本没有保留,值得拉出来单独讨论。在效果上LWM和Gemini 1.0 Pro以及GPT4有一定的竞争力,更多的细节可以阅读原论文。
四,总结:
多模态的呈现出以大模型为主线,逐步开始朝长上下文、混合模态、世界模型、多模态生成等方向发展。多模态大模型的惊艳能力主要来自于文本大模型中所蕴含的知识,以及超强的上下文理解能力,视觉特征只是从属的信息输入或感知源。但近期Gemini 1.5、LWM、甚至Sora等工作又开始尝试大模型理解物理世界(引出世界模型的概念),大模型好像开始从文本之外的模态强化输入信息的影响力。不管怎么说,持续的更新迭代让人耳目一新,相信也会不断刷新人们对人工智能边界的认知。
多模态的呈现出以大模型为主线,逐步开始朝长上下文、混合模态、世界模型、多模态生成等方向发展。
五,参考文章:
https://zhuanlan.zhihu.com/p/684472814
https://zhuanlan.zhihu.com/p/582878508

















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









