







ABSTRACT Electroencephalogram (EEG) signals have emerged as an important tool for emotion research due to their objective reflection of real emotional states. Deep learning-based EEG emotion classification algorithms have made encouraging progress, but existing models struggle with capturing long-range dependence and integrating temporal, frequency, and spatial domain features that limit their classification ability. To address these challenges, this study proposes a Bi-branch Vision Transformer- based EEG emotion recognition model, Bi-ViTNet, that integrates spatial-temporal and spatial-frequency feature representations.Specifically, Bi-ViTNet is composed of spatial-frequency feature extraction branch and spatial-temporal feature extraction branch that fuse spatial-frequency-temporal features in a unified framework. Each branch is composed of Linear Embedding and Transformer Encoder, which is used to extract spatial-frequency features and spatial-temporal features. Finally, fusion and classification are performed by the Fusion and Classification layer. Experiments on SEED and SEED-IV datasets demonstrate that Bi-ViTNet outperforms state-of-the-art baselines.
摘要:脑电图(EEG)信号因其能客观反映真实的情绪状态而成为情绪研究的重要工具。基于深度学习的EEG情绪分类算法取得了令人鼓舞的进展,但现有模型在捕获远程依赖性和整合时间、频率和空间域特征方面存在困难,这限制了它们的分类能力。为了解决这些问题,本研究提出了一种基于双分支视觉转换器的脑电情绪识别模型Bi-ViTNet,该模型集成了时空和空间频率特征表示。具体而言,Bi-ViTNet由空频特征提取分支和时空特征提取分支组成,将空频-时空特征融合在一个统一的框架中。每个分支由线性嵌入和变压器编码器组成,用于提取空间频率特征和时空特征。最后由融合与分类层进行融合与分类。在SEED和SEED- iv数据集上的实验表明,Bi-ViTNet优于最先进的基线。
1.介绍
Emotion is a psychological and physiological response formed by sensing external and internal stimuli that influences human behavior and plays a significant role in daily life [1], [2], [3], [4], [5], [6], [7]. As one of the most important research topics in affective computing, emotion recognition has garnered increasing interest in recent years due to its wide range of potential applications in human-computer interaction [8], disease detection [9], [10], [11], fatigue driving [12], [13], [14], [15], mental workload estimation [16], [17], [18], [19], and cognitive neuroscience. In general, emotion recognition methods can be divided into two types depending on whether physiological or non-physiological signals is involved [20]. Non-physiological signals, including speech, posture, and facial expression [21], are external manifestations of human emotions. Physiological signals, corresponding to the physiological reactions caused by emotions,such as eye electricity, ECG, EMG, and EEG, are human recessive emotional expressions [22]. Non-physiological signals, such as facial expressions and speech, are limited in their ability to reliably reflect an individual’s true emotional state, because humans may conceal their emotions through masking their facial expression and voice. Physiological signals, on the other hand, are difficult to disguise and can objectively reflect human emotions. Consequently, physiological signals are more suitable for emotion recognition. Among physiological signals, EEG signals are characterized by high time resolution and rich information content, enabling the detection of subtle changes in emotions. These features make emotion recognition tasks based on EEG signals more objective and accurate than those based on other types of physiological signals [23], [24], [25], [26], [27]. Therefore, emotion recognition methods based on EEG signals are more favored by researchers.
情绪是通过感知外部和内部刺激而形成的影响人类行为的心理和生理反应,在日常生活中发挥着重要作用[1]、[2]、[3]、[4]、[5]、[6]、[7]。情感识别作为情感计算领域最重要的研究课题之一,近年来因其在人机交互[8]、疾病检测[9]、[10]、[11]、疲劳驾驶[12]、[13]、[14]、[15]、脑力工作量估算[16]、[17]、[18]、[19]、认知神经科学等领域的广泛应用而受到越来越多的关注。一般来说,情绪识别方法根据涉及的是生理信号还是非生理信号,可以分为两类[20]。非生理信号,包括语言、姿势和面部表情[21],是人类情绪的外在表现。生理信号,与情绪引起的生理反应相对应,例如眼电、心电、肌电、脑电图是人类的隐性情绪表达[22]。非生理信号,如面部表情和言语,在可靠地反映个人真实情绪状态的能力上是有限的,因为人类可能通过掩饰面部表情和声音来隐藏自己的情绪。另一方面,生理信号很难伪装,可以客观地反映人类的情绪。因此,生理信号更适合于情绪识别。在生理信号中,脑电图信号具有时间分辨率高、信息量丰富的特点,可以检测到情绪的细微变化。这些特点使得基于EEG信号的情绪识别任务比基于其他类型生理信号的任务更加客观和准确[23],[24],[25],[26],[27]。因此,基于脑电图信号的情绪识别方法更受到研究者的青睐。
In order to better complete emotion recognition based on EEG signals, it is necessary to extract multi-dimensional features of EEG signals. In general, EEG signal features can be divided into: temporal domain features of EEG signals, frequency domain features of EEG signals, and spatial domain features of EEG signals [28], [29]. Temporal domain features of EEG signals: EEG signals collected with scalp electrodes and EEG signals amplified with acquisition equipment are all expressed in temporal domain. In temporal domain analysis, the temporal changes of neurophysiological signals are used as features to describe EEG signals with precise time markers. Such features include the information extracted from the collected EEG signal and related to the peak value or duration, reflecting the change of the signal with time [30]. Frequency domain features of EEG signals: The collected EEG signals can be represented in frequency domain by Fourier transform or wavelet transform. In the frequency domain, the features of neural signals are the subband power of EEG signals and the Power Spectral Density (PSD) that reflects the power changes of specific EEG signal frequency bands [31]. Spatial domain features of EEG signals: The purpose of extracting spatial domain features of EEG signals is to identify brain regions that generate specific neural activities by drawing topographical map of brain [32], [33].
为了更好地完成基于脑电信号的情绪识别,需要提取脑电信号的多维特征。一般来说,脑电信号的特征可以分为:脑电信号的时域特征、脑电信号的频域特征、脑电信号的空间特征[28]、[29]。脑电信号的时域特征:头皮电极采集的脑电信号和采集设备放大的脑电信号均以时域表示。在时域分析中,将神经生理信号的时间变化作为特征,用精确的时间标记来描述脑电信号。这些特征包括从采集到的脑电信号中提取的与峰值或持续时间相关的信息,反映了信号随时间的变化[30]。脑电信号的频域特征:采集到的脑电信号可以用傅里叶变换或小波变换在频域上表示。在频域,神经信号的特征是脑电信号的子带功率和反映特定脑电信号频段功率变化的功率谱密度(power Spectral Density, PSD)[31]。脑电信号的空间域特征:提取脑电信号空间域特征的目的是通过绘制脑地形图来识别产生特定神经活动的脑区域[32],[33]。
There are two main types of emotion recognition tasks based on EEG features [34]: conventional machine learning methods and deep learning methods. Conventional emotion recognition methods based on machine learning usually extract features from EEG signals, and then input these features into classification algorithm [35] such as Support V ector Machine (SVM) [36], K-Nearest Neighbor (KNN) [37], and Bayesian Network (BN) [38]. However, these methods require expert knowledge in both feature design and feature selection [39]. Therefore, it is challenging to extract relevant features from complex EEG signals and the results produced are lower compared to deep learning methods [40].The effectiveness of deep learning in solving pattern recognition problems in natural language processing, computer vision [21], speech recognition, and other fields [41], [42], have inspired researchers to apply deep learning methods in emotion recognition tasks using for example Convolutional Neural Networks(CNN) [43] and Long Short-Term Memory (LSTM) [44]. Although these methods have led to improvements in emotion recognition results compared to conventional machine learning methods, these methods still face some challenges. Challenge 1: At present, most of the models do not integrate the features of the three different domains of EEG signal, namely spatial-frequency- temporal, which limits the classification ability of the models to some extent.Challenge 2: At present, most models do not have strong ability to capture long-range dependency, and it is difficult to capture the global information of EEG signals, thus extracting more powerful features, which affects the performance of model classification.
基于EEG特征的情绪识别任务主要有两种类型[34]:传统的机器学习方法和深度学习方法。传统的基于机器学习的情绪识别方法通常是从EEG信号中提取特征,然后将这些特征输入到支持向量机(SVM)[36]、k近邻(KNN)[37]、贝叶斯网络(BN)[38]等分类算法[35]中。然而,这些方法需要特征设计和特征选择方面的专业知识[39]。因此,从复杂的脑电图信号中提取相关特征具有挑战性,与深度学习方法相比,产生的结果更低[40]。深度学习在解决自然语言处理、计算机视觉[21]、语音识别等领域的模式识别问题[41]、[42]方面的有效性激发了研究人员将深度学习方法应用于情绪识别任务,例如使用卷积神经网络(CNN)[43]和长短期记忆(LSTM)[44]。尽管与传统的机器学习方法相比,这些方法在情绪识别结果上有所改善,但这些方法仍然面临一些挑战。挑战1:目前大多数模型没有将脑电信号的空间-频率-时间三个不同域的特征进行整合,这在一定程度上限制了模型的分类能力。挑战2:目前大多数模型的远程依赖捕获能力不强,难以捕获EEG信号的全局信息,从而提取更强大的特征,影响了模型分类的性能。
The aim of our research is to address the aforementioned challenges and improve the classification performance of the model. Therefore, in order to address the aforementioned challenges, we propose an EEG emotion recognition model, Bi-branch Vision Transformer Network (Bi-ViTNet), which is based on the dual branch Vision Transformer and takes spatial-frequency features representation and spatialtemporal features representation as input. Bi-ViTNet consists of spatial-frequency feature extraction branch and spatialtemporal feature extraction branch. Each branch is composed of a Linear Embedding and a Transformer Encoder, which is used to extract spatial-frequency features and spatialtemporal features. The extracted spatial-frequency features and spatial-temporal features are fused and classified by Fusion and Classification layer. Bi-ViTNet not only integrates the frequency-spatial-temporal information of EEG signals in a unified network framework but also the Transformer Encoder in each branch of Bi-ViTNet can better capture the long-range dependencies of EEG signals. Experiments using SEED and SEED-IV datasets show that BiViTNet outperforms all the state-of-the-art models in terms of accuracy and standard deviation. Finally, we conduct ablation studies to determine the validity of each branching model.
我们的研究目的是解决上述挑战,提高模型的分类性能。因此,为了解决上述挑战,我们提出了一种EEG情绪识别模型,双支路视觉变压器网络(Bi-ViTNet)是基于双支路视觉变压器,以时空特征表示和空间频率特征表示为输入。Bi-ViTNet由空频特征提取分支和时空特征提取分支组成。每个分支由一个线性嵌入和一个变压器编码器组成,用于提取空间频率特征和时空特征。提取的空间频率特征和时空特征通过融合和分类层进行融合和分类。Bi-ViTNet不仅将脑电信号的频率-时空信息整合在一个统一的网络框架中,而且Bi-ViTNet各分支中的变压器编码器可以更好地捕获脑电信号的远程依赖关系。使用SEED和SEED- iv数据集的实验表明,BiViTNet在准确性和标准差方面优于所有最先进的模型。最后,我们进行消融研究,以确定每个分支模型的有效性。
2.相关工作
We have reviewed related work in terms of EEG signalbased emotion recognition and the Transformer model in this section.
在本节中,我们回顾了基于EEG信号的情感识别和Transformer模型的相关工作。
A. EEG-BASED EMOTION RECOGNITION
In recent years, time series data mining has gradually become a research hotspot [45], [46]. Time series technology has been applied in many fields, such as transportation [47] and medical treatment [48], [49], [50]. EEG is a typical time series data. EEG signals have been widely used in emotion recognition because they could reflect the real emotions of subjects accurately and objectively. In earlier studies, researchers used conventional machine learning models, such as SVM to model emotion using EEG signals. For example, Nie et al. extracted EEG features from the EEG signal, and employed a linear dynamic system technique to smooth these features, then modelled these features using SVM [51]. Anh et al. developed a real-time emotion recognition system based on EEG signals that is capable of detecting various emotional states, including happiness, relaxation, and neutral states. The system employs an SVM classifier and has demonstrated an average accuracy of 70.5% [52].
A .基于脑电图的情绪识别
近年来,时间序列数据挖掘逐渐成为研究热点[45],[46]。时间序列技术在交通运输[47]、医疗[48]、[49]、[50]等诸多领域都有应用。脑电图是一种典型的时间序列数据。由于脑电图信号能准确、客观地反映被试的真实情绪,因此在情绪识别中得到了广泛的应用。在早期的研究中,研究人员使用传统的机器学习模型,如支持向量机,利用脑电图信号来模拟情绪。例如,Nie等人从脑电信号中提取脑电信号特征,采用线性动态系统技术对这些特征进行平滑处理,然后使用支持向量机对这些特征进行建模[51]。Anh等人开发了一种基于脑电图信号的实时情绪识别系统,能够检测各种情绪状态,包括快乐、放松和中性状态。该系统采用SVM分类器,平均准确率为70.5%[52]。
Inspired by the success of deep learning in computer vision, natural language processing, and biomedical signal processing, several researchers have attempted to employ deep learning methods for EEG-based emotion recognition.Zheng et al proposed a deep belief network (DBN) to classify three categories of emotions using EEG features, and demonstrated through experiments that deep learning methods outperformed traditional machine learning methods [53].Alhagry et al put forward a kind of end-to-end deep learning neural network to recognize emotions from raw EEG signals.The network utilizes an LSTM-RNN to learn features from the EEG signals and the dense layer for classification [44].
受深度学习在计算机视觉、自然语言处理和生物医学信号处理方面的成功启发,一些研究人员试图将深度学习方法用于基于脑电图的情感识别。Zheng等人提出了一种深度信念网络(deep belief network, DBN),利用EEG特征对三类情绪进行分类,并通过实验证明了深度学习方法优于传统的机器学习方法[53]。Alhagry等人提出了一种端到端深度学习神经网络从原始脑电图信号中识别情绪。该网络利用LSTM-RNN从EEG信号和密集层中学习特征进行分类[44]。
Even though all the deep learning methods gave encouraging results, it is still difficult to combine more essential information from diverse domains. Therefore, some researchers proposed new methods. Al-Nafjan et al proposed a methodology for EEG emotion recognition. Power spectral density and deep neural networks were considered in the proposed approach [54]. Yin et al extracted Differential Entropy(DE) features to construct feature cubes and took them as input to a novel deep learning model as fusing graph convolutional neural network (GCNN) and LSTM to achieve EEG-based emotion classification [55]. Liu et al developed a dynamic differential entropy (DDE) technique to extract EEG signal characteristics. The collected DDE features were input to a convolutional neural network [56]. Rahman et al proposed to transform EEG signals into a topographic map of brain covering frequency and it was used as features to a convolutional neural networks for emotion recognition [57]. Topic et al came up with an idea to construct topographic feature map (TOPO-FM) and holographic feature map (HOLO-FM) using EEG signal features and after that used deep learning as a feature extraction method on feature maps to identify different types of emotions [58].
尽管所有的深度学习方法都给出了令人鼓舞的结果,但仍然很难将来自不同领域的更重要的信息结合起来。因此,一些研究者提出了新的方法。al - nafjan等人提出了一种EEG情绪识别方法。该方法考虑了功率谱密度和深度神经网络[54]。Yin等人提取微分熵(Differential Entropy, DE)特征构建特征立方体,并将其作为融合图卷积神经网络(GCNN)和LSTM的新型深度学习模型的输入,实现基于脑膜的情绪分类[55]。Liu等人开发了一种动态微分熵(DDE)技术来提取脑电信号特征。将收集到的DDE特征输入到卷积神经网络中[56]。Rahman等人提出将EEG信号转化为脑覆盖频率的地形图,并将其作为特征加入卷积神经网络进行情绪识别[57]。Topic等人提出了利用脑电图信号特征构建地形特征图(TOPO-FM)和全息特征图(HOLO-FM)的思路,之后利用深度学习作为特征图的特征提取方法来识别不同类型的情绪[58]。
These works obtained encouraging results using only one or two types of features (temporal or frequency features).There are few studies in EEG-based emotion recognition that combine three features: temporal domain features, frequency domain features, and spatial domain features. Jia et al. proposed an attention 3D dense network with fusing shortrange EEG features in the time domain, the spatial domain, and the frequency domain [39]. Xiao et al used 4D spatialspectral-temporal representations as input and proposed a method called the 4D local attention-based neural network for EEG emotion classification and recognition [59]. However, these models do not learn long-range dependencies well and have difficulty in capturing the global information of EEG signals.
这些工作仅使用一种或两种类型的特征(时间或频率特征)就获得了令人鼓舞的结果。结合时域特征、频域特征和空域特征的基于脑电图的情感识别研究很少。Jia等人提出了一种在时域、空域和频域融合短时脑电特征的注意力三维密集网络[39]。Xiao等人以四维时空表征作为输入,提出了一种基于四维局部注意的神经网络EEG情绪分类识别方法[59]。然而,这些模型不能很好地学习远程依赖关系,难以捕获脑电信号的全局信息。
B.TRANSFORMER
Transformer was first proposed in natural language processing [60], and since then it has been applied in other domains [61]. Vision Transformer (ViT) based on multi-head self-attention to patches of images has achieved outstanding results in the field of computer vision. A ViT associates a query and a set of key-value pairs with an output based on the attention mechanism described as Formula (1):
Transformer首先在自然语言处理中被提出[60],此后它被应用于其他领域[61]。基于多头自关注图像块的视觉变换(Vision Transformer, ViT)在计算机视觉领域取得了突出的成果。ViT将查询和一组键值对与基于注意机制的输出关联起来,如公式(1)所示: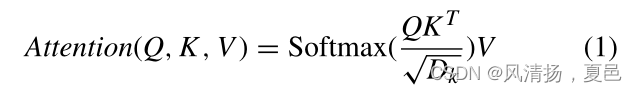
where Q is the query, K means the key, and V indicates the value, respectively. Dk represents the dimension of the query and the key. Through the training of largescale data sets, Vision Transformer has achieved state-of-theart ImageNet image classification result. In addition, it has been applied in computer vision problems, including object detection [62], image classification [63], segmentation [64], etc. In general, Transformer has the following advantages,
Advantage 1: Transformer has strong ability to learn longrange dependencies, and its multi-head self-attention and parallel input processing improve the modeling of long-range dependencies. Transformer could use attention mechanisms to capture global information and extract more powerful features. Advantage 2: The position embedding of Transformer preserved key position information of words and image blocks, while class tags can aggregate representative information [65]. Advantage 3: Transformer is suitable for multi-modal data input. The data can be used as the input of Transformer model when converted into vectors. These advantages of Transformer model motivate us to investigate it for emotion recognition tasks based on EEG signals.
其中Q为查询,K为键,V为值。Dk表示查询和键的维度。通过对大规模数据集的训练,Vision Transformer获得了最先进的ImageNet图像分类结果。此外,它还被应用于计算机视觉问题,包括目标检测[62]、图像分类[63]、分割[64]等。一般来说,Transformer具有以下优点:
优势1:Transformer具有较强的远程依赖关系学习能力,其多头自注意和并行输入处理,提高了远程依赖关系的建模能力。Transformer可以使用注意力机制来捕获全局信息并提取更强大的功能。优点2:Transformer的位置嵌入保留了单词和图像块的关键位置信息,而类标签可以聚合代表性信息[65]。优点3:变压器适用于多模态数据输入。将数据转换成向量后,可以作为Transformer模型的输入。变压器模型的这些优点促使我们研究它在基于脑电信号的情绪识别任务中的应用。
3.预赛
In this paper, we define ES = (ES 1 , ES 2 , . . . , ESB) ∈ RNe×B as the frequency features containing B frequency bands extracted from EEG signals, where Ne is the number of electrodes. We construct the spatial-frequency features AS = (AS 1, AS 2, . . . , ASB) ∈ RH×W ×B, where H and W represent the height and width of the frequency map, respectively.
We define ET = (ET1 , ET2 , . . . , ETT ) ∈ RNe×T as an EEG signal sample of T period, where Ne is the number of electrodes. We construct the spatial-temporal features AT = (AT1 , AT2 , . . . , ATT ) ∈ RH×W ×T , where H and W represent the height and width of the temporal map, respectively.
The objective of the study is to establish a mapping between spatial-frequency/temporal representations and emotional states. Given spatial-frequency representation AS and spatial-temporal representation AT , the emotion recognition task can be characterized as Yout = F(AS, AT ), where Yout represents the emotion state and and F is our proposed model.
本文定义ES = (ES 1, ES 2,…, ESB)∈RNe×B为从EEG信号中提取的包含B个频带的频率特征,其中Ne为电极个数。我们构造了空间频率特征AS = (AS 1, AS 2,…)。, ASB)∈RH×W ×B,其中H和W分别表示频率图的高度和宽度。
我们定义ET = (ET1, ET2,…, ETT)∈RNe×T为T周期的脑电信号样本,其中Ne为电极个数。构造了时空特征AT = (AT1, AT2,…)。, ATT)∈RH×W ×T,其中H和W分别表示时间图的高度和宽度。
本研究的目的是建立空间-频率/时间表征与情绪状态之间的映射关系。给定空间频率表征AS和时空表征AT,情绪识别任务可以表征为Yout = F(AS, AT),其中Yout表示情绪状态,F为我们提出的模型。
4.方法
We propose an EEG emotion recognition model, Bi-branch Vision Transformer Network (Bi-ViTNet), based on the dual branch Vision Transformer, with the spatial-frequency features representation and spatial-temporal features representation as the input. Figure 1 shows the overall architecture of the proposed Bi-ViTNet model. Bi-ViTNet consists of spatialtemporal encoder and spatial-frequency encoder, and inputs to the encoders are the spatial-frequency features and the spatial-temporal features respectively. Both spatial-temporal encoder and spatial-frequency encoder consist of a Linear Embedding Layer and a Transformer Encoder. The input features go into the Linear Embedding. We summarize three core ideas of the Bi-ViTNet as follows:
提出了一种基于双分支视觉变换的脑电情感识别模型——双分支视觉变换网络(Bi-ViTNet),以时空特征表示和空间频率特征表示为输入。图1显示了提议的Bi-ViTNet模型的整体架构。Bi-ViTNet由时空编码器和空间频率编码器组成,编码器的输入分别是空间频率特征和时空特征。时空编码器和空频编码器都由线性嵌入层和变压器编码器组成。输入特征进入线性嵌入。我们总结了Bi-ViTNet的三个核心理念:
1) Spatial-frequency data construction and spatialtemporal data construction methods are proposed;
2) Based on the construction of spatial-frequency data and spatial-temporal data, the spatial-frequency-temporal information of EEG is fused in a unified network framework;
3) The Transformer model is used to capture the global information of EEG signals in spatial-temporal and spatial-frequency domains.
1)提出了空间频率数据构建和时空数据构建方法;
2)基于空频数据和时空数据的构建,将脑电的空频时信息融合在统一的网络框架中;
3)利用Transformer模型在时空域和空间频域捕获脑电信号的全局信息。

图1所示。EEG情绪识别的全过程。实验对象的脑电信号被构造为时空表征和空间频率表征,并作为Bi-ViTNet模型的输入。该模型由两个分支组成,一个分支提取时空特征,另一个分支提取空间频率特征。两个结构相同的支路由线性嵌入层和变换编码器层组成。最后,对时空分支和空间频率分支提取的特征进行融合和分类。
A. SPATIAL-FREQUENCY AND SPATIAL-TEMPORAL FEATURE REPRESENTATIONS
To better characterize EEG data, the original EEG signal is converted into spatial-temporal and spatial-frequency representations, which are used to describe the spatial distribution of temporal and frequency information of EEG signals. The 10-20 electrode placement system is an arrangement of electrodes on the surface, containing the spatial information of brain potential distribution. Then, the mapping electrode position matrix is used to create a spatial frame for each sample and describe the spatial information in the constructed spatial-temporal and spatial-frequency representations of EEG signals. The spatial-temporal and spatial-frequency representations of EEG signals are used as the input of the Bi-ViTNet, as shown in Figure 2.
Figure 3 shows the process of converting the original EEG signals into spatial-temporal and spatial-frequency representations. The original EEG signals are divided into non-overlapping periods lasting for τ = 1 seconds, and each segment is assigned the same label as the original EEG signals.
A.空间-频率和时空特征表征
为了更好地表征脑电信号,将原始脑电信号转换成时空和空间-频率表征,用来描述脑电信号时间和频率信息的空间分布。10-20电极放置系统是电极在表面的排列,包含了脑电位分布的空间信息。然后,利用映射电极位置矩阵为每个样本创建空间帧,并在构建的脑电信号时空表征和空间频率表征中描述空间信息。脑电信号的时空和空间频率表示被用作Bi-ViTNet的输入,如图2所示。图3显示了将原始脑电图信号转换为时空和空间频率表示的过程。将原始EEG信号划分为τ = 1秒的不重叠时间段,并将每个时间段与原始EEG信号赋予相同的标签。
1) SPATIAL-TEMPORAL FEATURE REPRESENTATION
To construct the spatial-temporal feature representation, we extract temporal-domain features of different time stamps from EEG fragments with a length of τ = 1 seconds.
We define ET = (ET1 , ET2 , . . . , ETT ) ∈ RNe×T as the EEG signal sample containing time stamp T ,time stamp is T ∈ {1, 2, . . . , 25}, the electrode is Ne ∈ {FP1, FPZ, . . . , CB2}, and X Tt = (x1t , x2t , . . . , xNt ) ∈ RN (t ∈ {1, 2, . . . , T }) represent the EEG signals of all N electrodes collected on the time stamp T . Then, the selected data are mapped to a temporal-domain brain electrode position matrix ATt ∈ RH×W (t ∈ {1, 2, . . . , T }) according to the electrode location on the brain. Finally, the temporaldomain brain electrode position matrices from different time stamps are superimposed to form the spatial-temporal features representation of EEG, that is, the construction of AT = (AT1 , AT2 , . . . , ATT ) ∈ RH×W ×T is completed.
1)时空特征表示
为了构建时空特征表示,我们从长度为τ = 1秒的脑电信号片段中提取不同时间戳的时域特征。
我们定义ET = (ET1, ET2,…, ETT)∈RNe×T为包含时间戳T的脑电信号样本,时间戳T∈{1,2,…, 25},电极Ne∈{FP1, FPZ,…, CB2},和X Tt = (x1t, x2t,…), xNt)∈RN (t∈{1,2,…, T})表示在时间戳T上采集到的所有N个电极的脑电信号。然后,将所选数据映射到一个时域脑电极位置矩阵ATt∈RH×W (t∈{1,2,…, T})根据电极在大脑上的位置。最后,将不同时间戳的时域脑电极位置矩阵进行叠加,形成脑电信号的时空特征表示,即构造AT = (AT1, AT2,…), ATT)∈RH×W ×T完成。
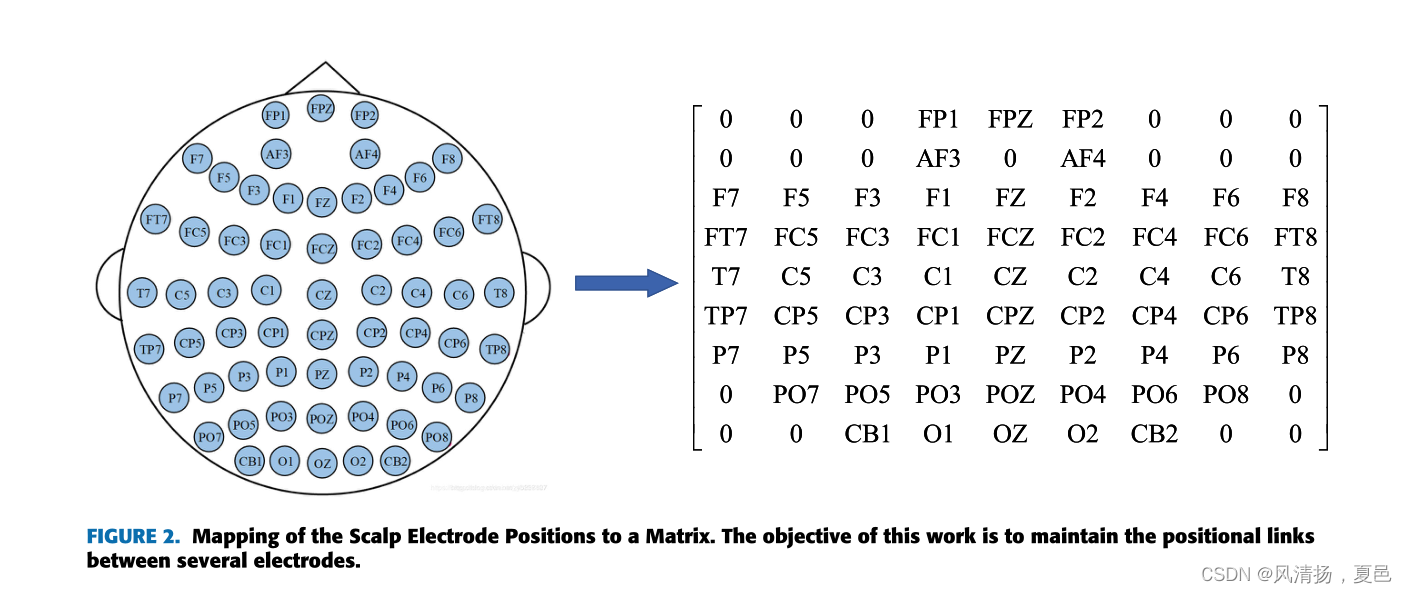
图2。头皮电极位置到矩阵的映射。这项工作的目的是维持几个电极之间的位置联系。
2) SPATIAL-FREQUENCY FEATURE REPRESENTATION
2)空间-频率特征表示
To construct the spatial-frequency feature representation, the temporal-frequency feature extraction method is used to extract the Power Spectral Density features of five frequency bands {δ, θ, α, β, γ } of all EEG channels from the EEG signal samples in the EEG segments with a length of τ = 1 seconds.We define ES = (ES 1 , ES 2 , . . . , ESB) ∈ RNe×B as a frequency feature containing a frequency band extracted from the Power Spectral Density feature, in which the frequency band is B ∈ {δ, θ, α, β, γ }, the electrode is Ne ∈ {FP1, FPZ, . . . , CB2}, and X Bb = (x1b, x2b, . . . , xNb ) ∈ RN (b ∈ {1, 2, . . . , B}) represent the collection of EEG signals from all Ne electrodes on the frequency band B. Then, the selected data are mapped to a frequency domain brain electrode position matrix ASb ∈ RH×W (b ∈ {1, 2, . . . , B}) according to the electrode location on the brain. Finally, the frequency-domain brain electrode position matrices from different frequencies are superimposed to form the spatial-frequency feature representation of EEG signals, that is, the construction of the spatial-frequency feature representation AS = (AS 1, AS 2, . . . , ASB) ∈ RH×W ×B is completed.
为了构建空频特征表示,采用时频特征提取方法,从长度为τ = 1秒的脑电信号样本中提取所有脑电信号通道δ、θ、α、β、γ} 5个频段的功率谱密度特征。我们定义ES = (ES 1, ES 2,…), ESB)∈RNe×B作为频率特征,其中包含从功率谱密度特征提取的频段,其中频段为B∈{δ, θ, α, β, γ},电极为Ne∈{FP1, FPZ,…, CB2},和X Bb = (x1b, x2b,…, xNb)∈RN (b∈{1,2,…, B})表示B频段上所有Ne电极的脑电信号集合,然后将所选数据映射到频域脑电极位置矩阵ASb∈RH×W (B∈{1,2,…, B})根据电极在大脑上的位置。最后,将不同频率的频域脑电极位置矩阵进行叠加,形成脑电信号的空频特征表示,即构建AS = (as1, as2,…)的空频特征表示。, ASB)∈RH×W ×B完成。
B. EEG EMOTION RECOGNITION BASED ON BI-BRANCH ViT
基于双分支ViT的EEG情绪识别
Transformer is a novel neural network architecture that was primarily created for natural language processing applications, in which multi-layer perceptron layers are utilized on top of multi-head attention mechanisms to capture the long-range dependencies in sequential input. Vision Transformer has recently demonstrated considerable promise in a variety of computer vision applications, such as picture classification and segmentation [61]. Motivated by these works, we propose a new kind of ViT, the Bi-branch Vision Transformer Network, which uses a different type of EEG feature representation. Specifically, we propose a ViT architecture with two branches, each of which processes a different EEG feature representation before combining the results for EEG categorization.
Transformer是一种新颖的神经网络架构,主要是为自然语言处理应用而创建的,其中多层感知器层被利用在多头注意机制的基础上,捕捉顺序输入中的长期依赖关系。Vision Transformer最近在各种计算机视觉应用中表现出相当大的前景,例如图像分类和分割[61]。在此基础上,我们提出了一种新的视觉网络,即双分支视觉变压器网络,它使用了一种不同类型的脑电特征表示。具体来说,我们提出了一个具有两个分支的ViT架构,每个分支处理不同的脑电信号特征表示,然后将结果组合在一起进行脑电信号分类。
We propose Bi-ViTNet to take advantage of the spatialtemporal representation and spatial- frequency representation for emotion recognition. Figure 4 illustrates the Bi-ViTNet model framework for EEG feature learning. The input of the Bi-ViTNet model is the spatial-temporal feature representation AT = (AT1 , AT2 , . . . , ATT ) ∈ RH×W ×T and the spatialfrequency feature representation AS = (AS 1, AS 2, . . . , ASB) ∈ RH×W ×B. We expand the spatial-temporal feature representation of size H ×W ×T and the H ×W ×B spatial-frequency feature representation into T spatial-temporal representation patches ATt ∈ RH×W with a size of H × W and B spectralspatial representation patches ASb ∈ RH×W with a size of H × W , respectively. Each representation patch is used as the input of the Linear Embedding layer. Linear Embedding is used to map representation patches to Ed with a constant size.According to Equation (2), WA can be obtained as the input of the Transformer Encoder, where xclsp ∈ REd denotes the class token in the feature representation learning, NTB ∈ {T , B} is the number of spatial-frequency/temporal representation patches, EA ∈ RH×W ×Ed is the linear projection matrix, and Apos E ∈ R(NTB+1)×Ed is one-dimensional position embedding, aiming to preserve the order information of frequency and time series.
我们提出了利用时空表征和空间频率表征来进行情感识别的Bi-ViTNet。图4展示了用于EEG特征学习的Bi-ViTNet模型框架。Bi-ViTNet模型的输入是时空特征表示AT = (AT1, AT2,…, ATT)∈RH×W ×T,空间频率特征表示AS = (AS 1, AS 2,…, asb)∈rh×w ×b。我们将大小为H×W ×T的时空特征表示和H×W ×B的空间频率特征表示分别扩展为大小为H×W的T个时空表示斑块ATt∈RH×W和大小为H×W的B个频谱空间表示斑块ASb∈RH×W。每个表示块作为线性嵌入层的输入。线性嵌入用于将表示块映射到具有恒定大小的Ed。根据式(2),可以得到WA作为Transformer Encoder的输入,其中xclsp∈REd为特征表示学习中的类令牌,NTB∈{T, B}为空频/时表示patch的个数,EA∈RH×W ×Ed为线性投影矩阵,Apos E∈R(NTB+1)×Ed为一维位置嵌入,目的是保持频率和时间序列的顺序信息。

As shown in Figure 4, the transformer encoder block includes multi-head self-attention, layer normalization, and multiple-layer perception. The first sub-layer is the Multihead self-attention (MSA) and the second is the Multi-layer perceptron (MLP). Before data enters each sub-layer, it is normalized by layer normalization (LN), and after it passes through each sub-layer, it is fused directly with the input using a residual connection. The operation in the transformer encoder is shown in Formula (3) and Formula (4).
如图4所示,变压器编码器块包括多头自关注、层规范化和多层感知。第一个子层是多头自注意(MSA),第二个子层是多层感知器(MLP)。数据在进入每一个子层之前,通过层归一化(LN)进行归一化,在通过每一个子层之后,通过残差连接直接与输入融合。变压器编码器的操作如式(3)、式(4)所示。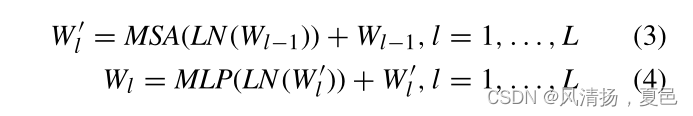
where MSA(·) and MLP(·) represent the MSA operation and MLP operation, W ′l and Wl are the outputs of the MSA and MLP , respectively. L is the number of stacked transformer encoder blocks. Finally, the spatial-temporal feature and spatial- frequency feature representations output by the transformer encoder are sent to the Fusion and Classification layer for emotion classification based on EEG.
其中,MSA(·)和MLP(·)分别表示MSA操作和MLP操作,W′l和Wl分别为MSA和MLP的输出。L为堆叠变压器编码器块的数量。最后,将变压器编码器输出的时空特征和空间频率特征表示发送到融合与分类层进行基于EEG的情感分类。
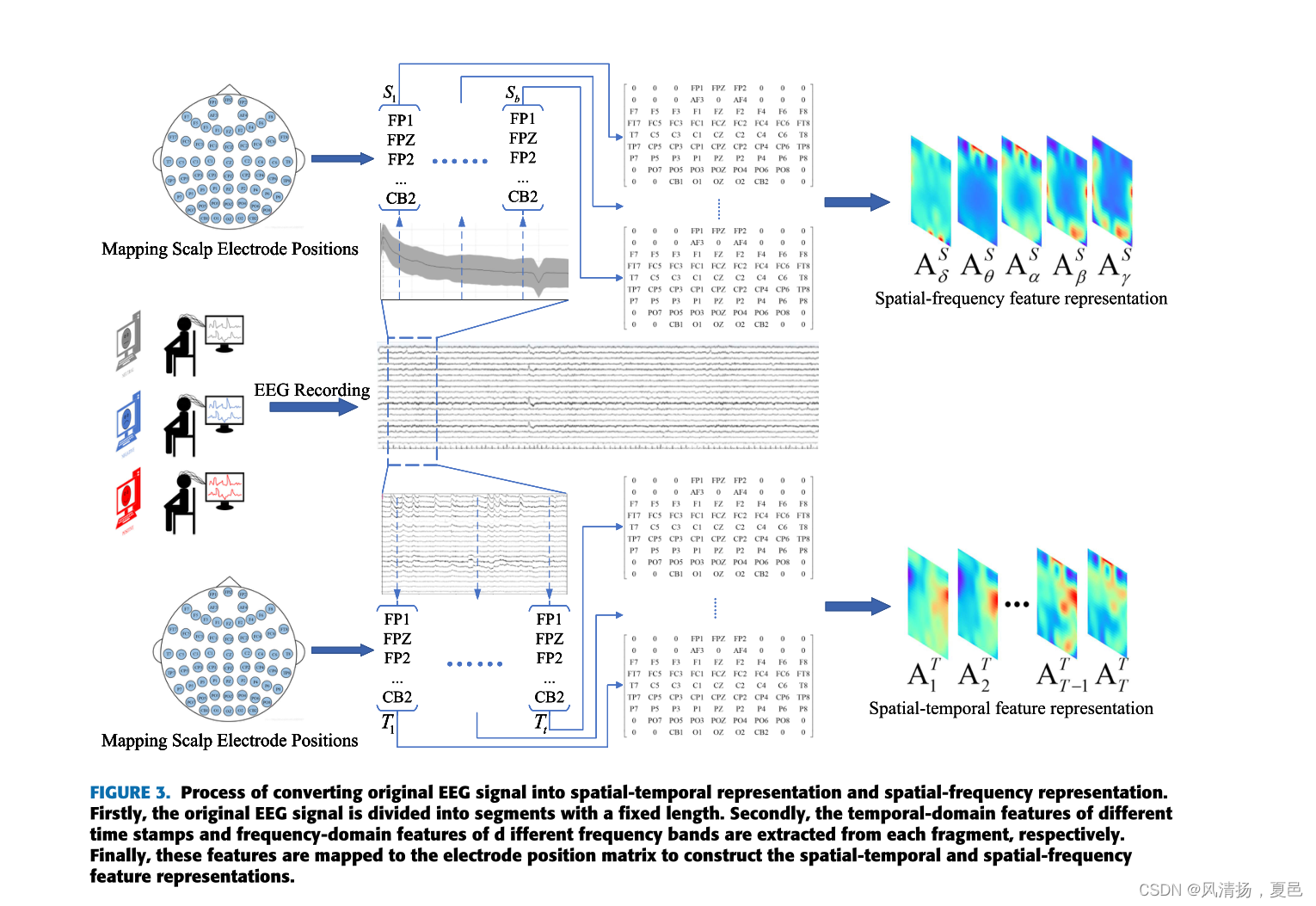
图3。将原始脑电信号转换为时空表示和空间频率表示的过程。首先,将原始脑电信号分割成固定长度的片段;其次,从每个片段中分别提取不同时间戳的时域特征和d个不同频带的频域特征;最后,将这些特征映射到电极位置矩阵中,以构建时空和空间频率特征表示。
C. FUSION AND CLASSIFICATION
C.融合与分类
Taking the spatial-temporal features representation and spatial-frequency features representation as the input, the Bi-branch Transformer model used for spatial-frequencytemporal features fusion and classification extracts the spatial-temporal feature information and spatial-frequency feature information from the spatial-temporal feature extraction module and the spatial-frequency feature extraction module, respectively. Finally, according to Equation (5), the output from the Bi-branch transformer is fused in the Fusion and Classification layer for high-precision classification.
以时空特征表示和空间频率特征表示为输入,用于时空特征融合与分类的双分支Transformer模型从时空特征中提取时空特征信息和空间频率特征信息分别为时空特征提取模块和空频特征提取模块。最后,根据式(5),将双支路变压器的输出在Fusion and Classification层进行融合,实现高精度分类。
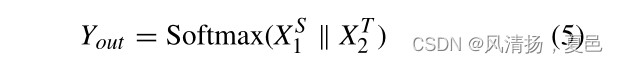
where ∥ represents the concatenate operation,X S 1 and X S 2denote the outputs from Bi-branch transformer, Yout denotes the classification result of Bi-ViTNet.The cross-entropy loss is used as a loss function in this paper.
其中∥表示连接操作,x1和x2表示双支路变压器输出,Yout表示Bi-ViTNet的分类结果。本文采用交叉熵损失作为损失函数。
5.实验
In this section, we first describe the datasets used in the study.Next, the experiment setup is then described. Finally, the experiment results are presented and discussed.
在本节中,我们首先描述了研究中使用的数据集。接下来,描述了实验设置。最后给出了实验结果并进行了讨论。
A.数据集
The study was carried out using SEED [53] datasets and SEED-IV [66] datasets. SEED datasets are public EEG datasets mainly used for emotion recognition. There are EEG data of 15 subjects in the datasets. Specifically, 15 Chinese film clips were selected to stimulate the subjects. Each clip viewing process can be divided into four stages, including 5s start prompt, 4-minute clip period, 45s self-assessment,and 15s rest period. The EEG recordings were carried out three times on each subject, and the interval between two consecutive recordings is two weeks. In every session, each subject watched 15 movie clips, each clip was about 4 minutes long, and they evoked positive, neutral, and negative emotions respectively. SEED-IV datasets are an extension of SEED datasets, including four different types of emotions, and the datasets can also be used to evaluate EEG based emotion recognition models. During the experiment, 72 video clips with a duration of 2 minutes were used to stimulate subjects to evoke happy, sad, fear, and neutral emotions.The participants self-evaluation their emotion after the video ends.ESI Neuroscan system was used to record signals of 62 channel EEG with a sampling rate of 1000 Hz, which was down sampled to 200 Hz. In order to filter noise and eliminate artifacts, EEG data of the two data sets were input to a bandpass filter. And the Power Spectral Density and Differential Entropy features of each segment in five frequency bands (δ:1 ∼ 4Hz, θ:4 ∼ 8Hz, α:8 ∼ 14Hz, β:14 ∼ 31Hz, γ : 31 ∼ 50Hz) were extracted. Table 1 summarizes the processing done to extract the EEG data.
本研究使用SEED[53]数据集和SEED- iv[66]数据集进行。SEED数据集是公开的EEG数据集,主要用于情感识别。数据集中有15个被试的脑电图数据。具体来说,我们选择了15个中国电影片段来刺激受试者。每个片段的观看过程可以分为4个阶段,包括5秒的开始提示,4分钟的剪辑时间,45秒的自我评估,15分钟休息时间。每个受试者进行3次脑电图记录,两次连续记录的间隔为2周。在每个阶段,每个被试观看15个电影片段,每个片段大约4分钟长,分别引起积极、中性和消极的情绪。SEED- iv数据集是SEED数据集的扩展,包括四种不同类型的情绪,这些数据集也可用于评估基于EEG的情绪识别模型。在实验过程中,我们使用了72段时长为2分钟的视频片段来刺激被试唤起快乐、悲伤、恐惧和中性的情绪。视频结束后,参与者自我评价自己的情绪。采用ESI Neuroscan系统记录62通道脑电图信号,采样率为1000hz,降采样至200hz。为了滤除噪声和消除伪影,将两个数据集的脑电信号输入到带通滤波器中。提取了5个频段(δ:1 ~ 4Hz, θ:4 ~ 8Hz, α:8 ~ 14Hz, β:14 ~ 31Hz, γ: 31 ~ 50Hz)各段的功率谱密度和微分熵特征。表1总结了提取EEG数据的处理过程。

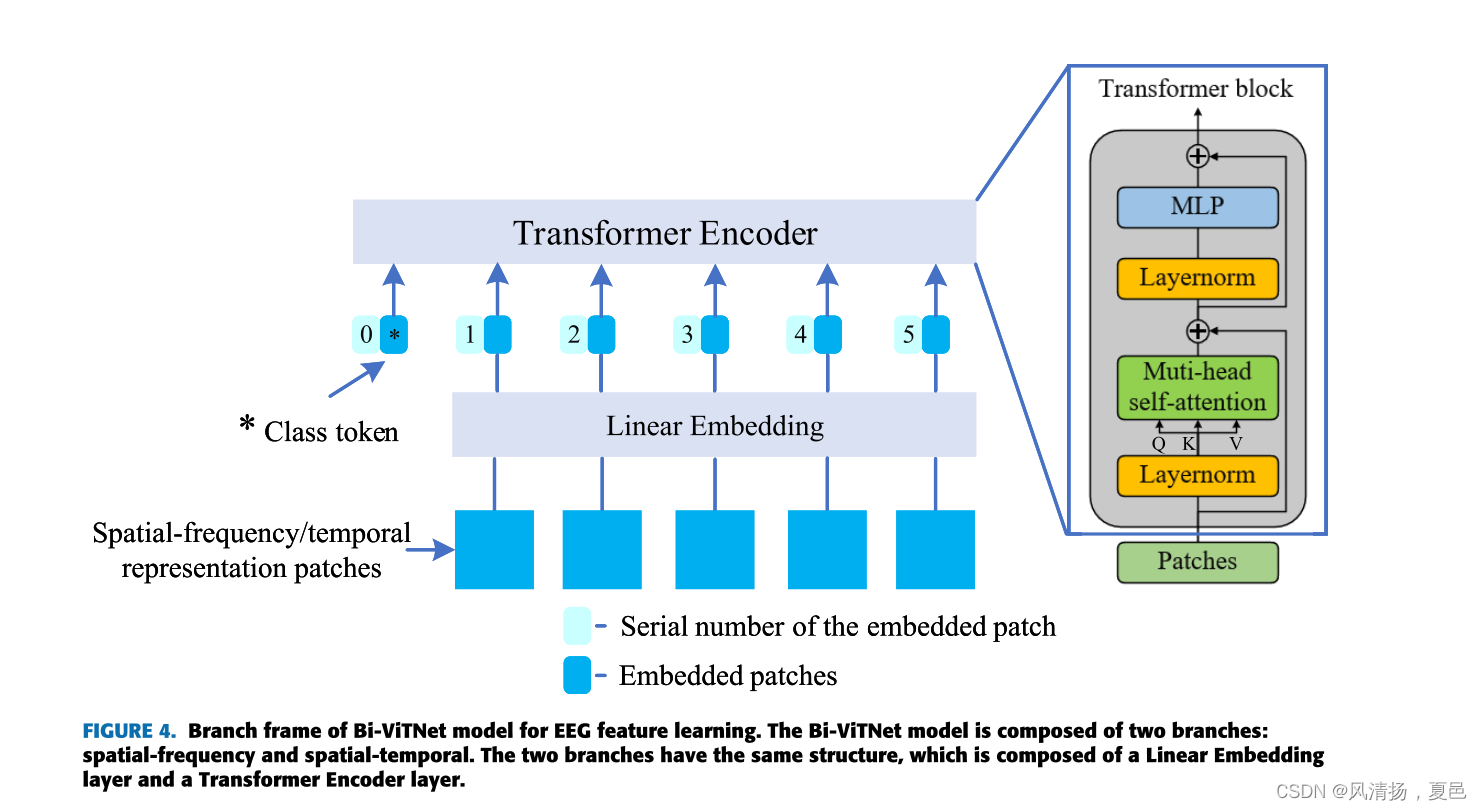
图4。脑电特征学习的Bi-ViTNet模型分支框架。Bi-ViTNet模型由空间-频率和时空两个分支组成。两个支路结构相同,由线性嵌入层和变压器编码器层组成。
B.设置
We trained the Bi-ViTNet model using a Tesla V100-SXM232GB GPU. A total of 12 transformer blocks were used.Each block consists of 12 attention heads. Adam optimizer was used for the training. In each experiment, we divided the original EEG signals into non-overlapping periods lasting for τ = 1 seconds. Each original EEG signal can be divided into approximately 256 segments. We randomly shuffled the samples. The data was divided for training and test. The ratio between training set and test set is 7:3. The hyperparameters were as follows:
我们使用Tesla V100-SXM232GB GPU训练Bi-ViTNet模型。总共使用了12个变压器块。每个块由12个注意头组成。使用Adam优化器进行训练。在每个实验中,我们将原始EEG信号划分为持续τ = 1秒的不重叠周期。每个原始脑电信号可以被分成大约256个片段。我们随机地洗牌样本。数据分为训练和测试两部分。训练集与测试集的比值为7:3。超参数如下:
•patch_size - 32 -每个补丁的大小。
•num_classes - 3或4 -分类类的数量。
SEED数据集有3个。SEED-IV数据集有4个。
•dim - 768 -线性变换后输出张量的最后一个维数。
•mlp_dim - 3072 - MLP(前馈)层的尺寸。
•depths- 12 -变压器块的数量。
•heads- 12 -在多头注意层的头的数量。
•dropout- 0.2 。
C.基线模型
We compared the proposed Bi-ViTNet with other competitive models.
我们将提出的Bi-ViTNet与其他竞争模型进行了比较。
• SVM [36]: A classifiers based on a least-squares support vector machine.
• DBN [53]: Deep belief networks that were trained with differential entropy features taken from multichannel EEG data to study crucial frequency bands and channels.
• DGCNN [67]: Multi-channel EEG emotion recognition using convolutional dynamical graph networks.
• RGNN [68]: Regularized graph neural network that takes the biological architecture of different brain areas into account in order to capture both global and local relationships between different EEG channels.
• R2G-STNN [30]: This method includes spatial and temporal neural network models with a regional to global hierarchical feature learning process to learn the discriminative spatial-temporal EEG features.
• BiHDM [69]: Bi-hemispheric discrepancy model that considers asymmetry discrepancies between the two hemispheres for EEG emotion identification and use four directed RNNs to obtain a deep representation of all the electrodes of EEG signals.
• SST-EmotionNet [39]: SST-EmotionNet extracts spatial, spectral, and temporal features using a two-stream network. In addition, SST-EmotionNet uses attention mechanisms to increase its EEG emotion recognition ability.
• 4D-aNN [59]: This method uses four-dimensional attention-based neural network with 4D spatial-spectraltemporal representations for EEG emotion recognition.
•SVM[36]:基于最小二乘支持向量机的分类器。
•DBN[53]:深度信念网络,使用从多通道EEG数据中获取的微分熵特征进行训练,以研究关键频段和通道。
•DGCNN[67]:基于卷积动态图网络的多通道EEG情绪识别。
•RGNN[68]:考虑不同脑区生物结构的正则化图神经网络,以捕获不同EEG通道之间的全局和局部关系。
•R2G-STNN[30]:该方法包括空间和时间神经网络模型,具有区域到全局的分层特征学习过程,以学习判别的时空脑电特征。
•BiHDM[69]:双半球差异模型,该模型考虑了两个半球之间的不对称差异,用于EEG情绪识别,并使用四个定向rnn来获得EEG信号的所有电极的深度表示。
•SST-EmotionNet [39]: SST-EmotionNet使用双流网络提取空间、光谱和时间特征。此外,SST-EmotionNet利用注意机制增强其EEG情绪识别能力。
•4D- ann[59]:该方法使用基于四维注意力的神经网络和四维空间-频谱-时间表征进行EEG情绪识别。
D.评价指标
For the proposed Bi-ViTNet method, its performance will be evaluated based on the following metrics: average accuracy (ACC) and standard deviation (STD). The accuracy rate is defined as the ratio of correctly identified positive and negative samples to the total number of samples, as shown in Equation (6):
对于所提出的Bi-ViTNet方法,其性能将基于以下指标进行评估:平均精度(ACC)和标准偏差(STD)。准确率定义为正确识别的阳性和阴性样本与样本总数之比,如式(6)所示:
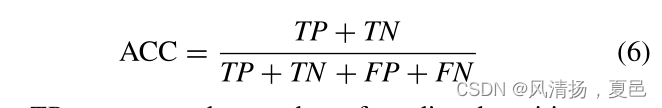
where TP represents the number of predicted positive samples in the positive samples, TN represents the number of predicted negative samples in the negative samples, FP represents the number of predicted positive samples in the negative samples, and FN represents the number of predicted negative samples in the positive samples. The standard deviation is shown in the Equation (7):
式中,TP为阳性样本中预测阳性样本的个数,TN为阴性样本中预测阴性样本的个数,FP为阴性样本中预测阳性样本的个数,FN为阳性样本中预测阴性样本的个数。标准差如式(7)所示:
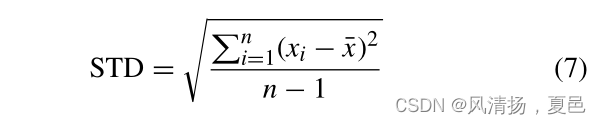
E.结果分析比较
We compare Bi-ViTNet model with the baseline models using SEED and SEED-IV datasets.We evaluate the performance of the models using the accuracy and the standard deviation. Table 2 shows the average accuracy and the standard deviation of these EEG based emotion recognition models on the SEED datasets. The proposed Bi-ViTNet achieved better performance compared to the baseline models on the SEED datasets. The result shows that the performance of deep learning models were better than that of SVM classifier. DGCNN only models evaluates the spatial information of EEG data obtained from several channels and extracts the spatial information using graph convolution. BiHDM uses bidirectionalRNN to model spatial information of EEG signals, and the classification accuracy was 93.12%. R2G-STNN not only extracts the EEG electrode associations in brain regions and brain regions in order to acquire spatial information, but it also extracts the dynamic information of EEG signals in order to obtain temporal information with good accuracy. SSTEmotionNet comprehensively considers the complementarity of spatial, spectral, and temporal information, and achieved good performance, with an accuracy rate of 96.02%. 4D-aNN takes 4D spatial spectral temporal representation containing spatial, spectral, and temporal information of EEG signal as input, and integrates attention mechanism into CNN module and bidirectional LSTM module, with an accuracy rate of 96.25%. Bi-ViTNet not only considers spatial, frequency, and temporal information but also better captures the global information of EEG signals, which enables Bi-ViTNet to fully extract valuable features from EEG signals for emotion recognition. Compared with the baseline models, the accuracy of Bi-ViTNet was significantly higher. In addition, Figure 5 shows the confusion matrix of Bi-ViTNet on the SEED datasets. The results show that for Bi-ViTNet, neutral emotions are easier to identify than negative emotions and positive emotions [22].
我们使用SEED和SEED- iv数据集将Bi-ViTNet模型与基线模型进行比较。我们用精度和标准差来评价模型的性能。表2给出了在SEED数据集上基于EEG的情绪识别模型的平均准确率和标准差SEED数据集。与SEED数据集上的基线模型相比,所提出的Bi-ViTNet获得了更好的性能。结果表明,深度学习模型的性能优于支持向量机分类器。DGCNN仅对多个通道获得的脑电数据的空间信息进行建模,并利用图卷积提取空间信息。BiHDM采用双向rnn对脑电信号空间信息进行建模,分类准确率为93.12%。R2G-STNN不仅提取脑区和脑区的脑电电极关联以获取空间信息,而且提取脑电信号的动态信息以获得时间信息,精度较高。SSTEmotionNet综合考虑了空间、光谱和时间信息的互补性,取得了较好的性能,准确率达到96.02%。4D- ann以包含脑电信号空间、频谱和时间信息的4D空间频谱时间表示为输入,将注意机制集成到CNN模块和双向LSTM模块中,准确率达到96.25%。Bi-ViTNet不仅考虑了脑电信号的空间、频率和时间信息,而且更好地捕捉了脑电信号的全局信息,使Bi-ViTNet能够从脑电信号中充分提取有价值的特征进行情绪识别。与基线模型相比,Bi-ViTNet的准确性显著提高。此外,图5显示了SEED数据集上Bi-ViTNet的混淆矩阵。结果表明,在Bi-ViTNet中,中性情绪比消极情绪和积极情绪更容易被识别[22]。

Table 3 shows the performance of all models on the SEED-IV dataset. The proposed Bi-ViTNet achieves the state-of-the-art performance on the SEED-IV dataset. For four categories of classification tasks, the accuracy rate of DBN is 66.77%, and the accuracy rate of DGCNN and RGNN based on graph is further improved by 69.88% and 79.37% respectively. BiHDM makes full use of the difference between the two hemispheres recorded by EEG, reaching 74.35%. SST-EmotionNet and 4D-aNN add attention mechanism to learn emotional features in different fields, reaching 84.92% and 86.77% respectively. Compare with the baseline model, Bi-ViTNet has further improved the accuracy of the model to 88.08%. In addition, the confusion matrix in Figure 6 shows that Bi-ViTNet has a good recognition effect on sad and neutral emotions, and the recognition accuracy of fear and happy is similar.
表3显示了所有模型在SEED-IV数据集上的性能。提议的Bi-ViTNet在SEED-IV数据集上实现了最先进的性能。对于四类分类任务,DBN的准确率为66.77%,而基于图的DGCNN和RGNN的准确率分别提高了69.88%和79.37%。BiHDM充分利用了脑电图记录的两脑半球差异,达到74.35%。SST-EmotionNet和4D-aNN加入注意机制学习不同领域的情绪特征,分别达到84.92%和86.77%。与基线模型相比,Bi-ViTNet将模型的准确率进一步提高到88.08%。此外,从图6的混淆矩阵可以看出,Bi-ViTNet对悲伤和中性情绪的识别准确率具有很好的识别效果,与对恐惧和快乐的识别准确率相近。

F.消融实验
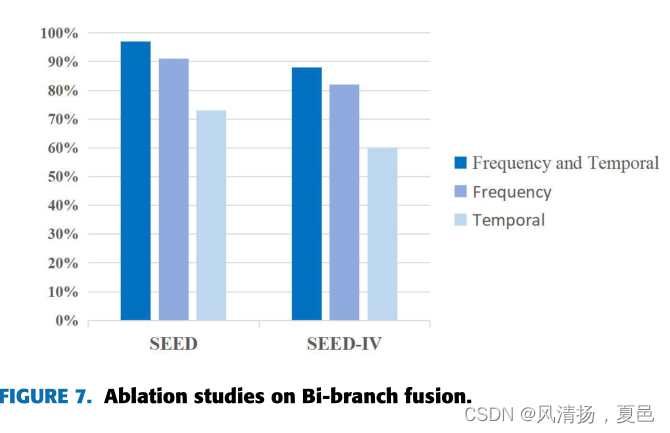
In order to evaluate the contribution of each component of Bi-ViTNet, we conducted an ablation study. We constructed two models: a spatial-temporal encoder with a classification layer, a spatial-frequency encoder with a classification layer.Figure 7 compares the accuracies of the three models on SEED and SEED-IV datasets, the performance of Bi-ViTNet is better than that of the single encoder models. By combinging the two encoders, the accuracy improved by 6.85% and 24.71% on the SEED datasets and 6.24% and 28.38% on the SEED-IV datasets, respectively, compared with that of the spatial-frequency branch model and the spatial-temporal branch model. The results show that the two branch structures effectively use the spatial-frequency-temporal features, and the different features are complementary, which improves the classification accuracy. In addition, the branching model considering only spatial-frequency features has better performance than the branching model considering only spatialtemporal features. This shows that the importance of different features is different.
为了评估Bi-ViTNet各组成部分的贡献,我们进行了消融研究。我们构建了两个模型:一个是带分类层的时空编码器,一个是带分类层的空间频率编码器。图7比较了三种模型在SEED和SEED- iv数据集上的精度,Bi-ViTNet的性能优于单编码器模型。将两个编码器组合后,精度提高了6.85%,与空间-频率分支模型和时空分支模型相比,SEED和SEED- iv数据集分别提高了24.71%和6.24%和28.38%。结果表明,两种分支结构有效地利用了空间-频率-时间特征,并且不同特征之间具有互补性,提高了分类精度。此外,仅考虑空间频率特征的分支模型比仅考虑时空特征的分支模型具有更好的性能。这说明不同功能的重要性是不同的。
6.结论
In this paper, we propose the Bi-ViTNet, a Bi-banch Vision Transformer-based model for emotion recognition of EEG signals. The frequency features and temporal features are mapped into the electrode position matrix to construct the spatial-temporal feature representations and the spatial-frequency feature representations. Bi-ViTNet then effectively utilizes the complementarity between different features by using spatial-frequency feature representations and spatial-temporal feature representations as input. In addition, Transformer Encoder in each branch of Bi-ViTNet can better capture the global information of EEG signals. Experiments on the SEED and SEED-IV datasets show that the Bi-ViTNet model outperform all baselines.In addition, the ablation studies show the effectiveness of dual branching and the fusion of spatial-frequencytemporal features in the model. The Bi-ViTNet could also be applied to other areas, such as driving fatigue analysis and motion imagery classification. While the transformerbased model has shown excellent recognition performance, the model has a large number of parameters. In the future, we will study the lightweight transformer models for emotion recognition.
本文提出了一种基于双分支视觉变换的脑电信号情感识别模型Bi-ViTNet。将频率特征和时间特征映射到电极位置矩阵中,构建时空特征表示和空间频率特征表示。然后,Bi-ViTNet通过使用空间频率特征表示和时空特征表示作为输入,有效地利用了不同特征之间的互补性。此外,Bi-ViTNet各分支中的变压器编码器可以更好地捕获脑电信号的全局信息。在SEED和SEED- iv数据集上的实验表明,Bi-ViTNet模型优于所有基线。此外,消融研究表明了模型中双分支和时空特征融合的有效性。Bi-ViTNet还可以应用于其他领域,如驾驶疲劳分析和运动图像分类。虽然基于变压器的模型具有良好的识别性能,但该模型的参数过多。未来,我们将研究用于情感识别的轻量级变压器模型。















 4869
4869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









