







论文题目:Introducing Attention Mechanism for EEG Signals: Emotion Recognition with Vision Transformers
Abstract— The accurate emotional assessment of humans can prove beneficial in health care, security investigations and human interaction. In contrast to emotion recognition from facial expressions which can prove to be inaccurate, analysis of electroencephalogram (EEG) activity is a more accurate representation of one’s state of mind. With advancements in deep learning, various methods are being employed for this task.In this research, importance of attention mechanism in EEG signals is introduced through two vision transformer based methods for the classification of EEG signals on the basis of emotions. The first method utilizes 2-D images generated through continuous wavelet transform (CWT) of the raw EEG signals and the second method directly operates on the raw signal. The publicly available and widely accepted DEAP dataset has been utilized in this research for validating the proposed approaches. The proposed approaches report very high accuracies of 97% and 95.75% using CWT and 99.4% and 99.1% using raw signal for valence and arousal classifications respectively, which clearly highlights the significance of attention mechanism for EEG signals. The proposed methodology also ensures faster training and testing time which suits the clinical purposes.
摘要:准确的人类情绪评估在医疗保健、安全调查和人际交往中是有益的。与通过面部表情来识别情绪可能被证明是不准确的相比,脑电图(EEG)活动的分析更准确地反映了一个人的精神状态。随着深度学习的进步,各种方法被用于这项任务。本研究通过两种基于视觉变换的基于情绪的脑电信号分类方法,介绍了注意机制在脑电信号中的重要性。第一种方法是利用原始脑电信号经过连续小波变换(CWT)生成的二维图像,第二种方法是直接对原始信号进行处理。本研究使用了公开可用且被广泛接受的DEAP数据集来验证所提出的方法。结果表明,CWT和原始信号的效价和觉醒分类准确率分别为97%和95.75%和99.4%和99.1%,表明注意机制对脑电信号的重要性。所提出的方法还确保了更快的培训和测试时间,符合临床目的。代码可在https://github.com/AniketRajpoot/Emotion-Recognition-Transformers上获得
临床意义-这项工作建立了一种高度精确的算法,用于使用脑电图信号进行情绪识别,这在基于音乐的治疗中具有潜在的应用前景。
1.介绍
Emotions, the very essence of human beings, can be associated with thoughts, decision-making abilities and cognitive processes. Therefore, studies on emotional states can enhance current brain computer interface (BCI) systems which can be further employed in various applications such as implementing therapies for disorders like autism spectrum disorder (ASD), attention deficit hyperactivity disorder (ADHD) and anxiety disorder [1]. Due to such important applications, recognition and analysis of emotional states have become an important research area in the fields of medical science, neuroscience, cognitive science and brain driven artificial intelligence. Several methods have been developed for emotion recognition which includes the use of both physiological and non-physiological signals. Nonphysiological signals include facial expressions, voice signals, body gestures while physiological signals include EEG, ECG signals and many more. Using non-physiological signals is relatively easy and does not require any special equipment, but an individual can forge such signals and are therefore not considered as a true reflection of one’s emotional state. In contrast, physiological signals are beyond one’s control and therefore more suitable for the given task [7].
情感是人类的本质,可以与思想、决策能力和认知过程联系在一起。因此,对情绪状态的研究可以增强当前的脑机接口(BCI)系统,该系统可以进一步应用于各种应用,如实施自闭症谱系障碍(ASD)、注意缺陷多动障碍(ADHD)和焦虑症等疾病的治疗[1]。由于这些重要的应用,情绪状态的识别和分析已成为医学、神经科学、认知科学和脑驱动人工智能等领域的重要研究领域。已经开发了几种用于情绪识别的方法,其中包括使用生理和非生理信号。非生理信号包括面部表情、语音信号、肢体动作,而生理信号包括脑电图、心电信号等等。使用非生理信号相对容易,不需要任何特殊设备,但个人可以伪造这些信号,因此不被认为是一个人情绪状态的真实反映。相比之下,生理信号是无法控制的,因此更适合于给定的任务[7]。
Various studies have been done in the past that have specifically handled emotion recognition through physiological signals as in [2-9]. Algorithms using power spectral density (PSD) features with Naive Bayes classifiers [2, 3], PSD and Statistical features with Ontological models [4], Deep belief network (DBN) based features with support vector machine classifier [5], power spectral and statistical features with neural networks (NN) [6], features extracted using LP-1D-CNN model with SoftMax as a classifier [7], Pearson Correlation Coefficient features with Deep Neural Network and Sparse Autoencoder architecture as a classifier [8], and raw EEG 1D time signals directly used with MMResLSTM as a classifier [9] are a few of them. In most of the approaches [2-9], emotional states, which are ideally discretized into numerous states such as joy, fear, anger, happiness, surprise etc., are broadly classified into two basic meaningful dimensions: valence and arousal[18]. The valence dimension determines the positive or negative effects of the emotion and the arousal dimension determines the intensity of it as shown in Fig 1.
过去已经进行了各种研究,专门通过生理信号处理情绪识别,如[2-9]。使用功率谱密度(PSD)特征与朴素贝叶斯分类器相结合的算法[2,3],使用PSD和统计特征与本体模型相结合的算法[4],基于深度信念网络(DBN)的特征与支持向量机分类器相结合的算法[5],使用神经网络(NN)的功率谱和统计特征[6],使用LP-1D-CNN模型与SoftMax作为分类器相结合的特征提取算法[7],Pearson Correlation Coefficient feature以Deep Neural Network和Sparse Autoencoder架构作为分类器[8],以及直接使用MMResLSTM作为分类器的原始EEG 1D时间信号[9]就是其中的一部分。在大多数方法[2-9]中,情绪状态被理想地离散为许多状态,如喜悦、恐惧、愤怒、幸福、惊讶等,它们被大致分为两个基本的有意义的维度:效价和唤醒[18]。效价维度决定情绪的积极或消极影响,唤醒维度决定情绪的强度,如图1所示。
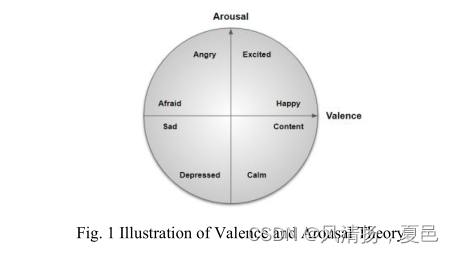
However, it has to be remembered that, tasks like emotion recognition occur over a period of seconds and are not an instantaneous response which happens over a period of milliseconds. As a few seconds of time is a significant amount of data for EEG, there might be connections between an impulse occurred between a brief period of time. In such cases it will be good if the model employed for emotion classification considers events that happened far in the past also. Architectures such as Convolutional Neural Networks (CNN) and Long-short-term-memory (LSTM) may not be able to consider this long-term dependence. CNN’s are localized networks as determined by the kernel size and respective strides, whereas LSTMs do not have good memory retaining capability due to the forgetting factor [10, 11]. On the other hand, the ability to model dependencies without having the constraint of far distances in the sequence is basically the very core of attention mechanism in transformer networks [12, 13]. Transformers [10] which are based on the self-attention mechanism, have been very widely accepted in natural language processing (NLP) because of this. At a high level, the model goes through every vector where self-attention enables it to look at other parts of the input sequence which can help in the better encoding of the vector. A transformer network is a stack of these attention layers with some residuals connections. Transformers have the capability to retain as much information as the memory limits, and establish a relationship between what has occurred in the past and what is happening now. LSTM’s and CNN’s model their positions in relative terms whereas transformers rely on absolute position representations of the input (The positional embedding and it is permutation invariant) [10, 11].
然而,必须记住的是,像情绪识别这样的任务是在几秒钟内发生的,而不是在几毫秒内发生的瞬间反应。由于几秒的时间对于脑电图来说是相当大的数据量,因此在短时间内发生的一个脉冲之间可能存在联系。在这种情况下,如果用于情绪分类的模型也考虑到发生在很久以前的事件,那将是很好的。卷积神经网络(CNN)和长短期记忆(LSTM)等架构可能无法考虑这种长期依赖性。CNN是由内核大小和各自的步长决定的局部网络,而lstm没有很好的遗忘因素导致的记忆能力[10,11]。另一方面,在不受序列中远距离约束的情况下对依赖关系进行建模的能力基本上是Transformers 网络中注意力机制的核心[12,13]。基于自注意机制的Transformers [10],在自然语言处理(NLP)中得到了非常广泛的接受。在较高的层次上,模型遍历每个向量,其中自我关注使其能够查看输入序列的其他部分,这有助于更好地编码向量。Transformers 网络是这些注意层和一些剩余连接的叠加。Transformers 能够在内存限制的情况下保留尽可能多的信息,并在过去发生的事情和现在正在发生的事情之间建立一种关系。LSTM和CNN以相对形式对其位置进行建模,而Transformers 依赖于输入的绝对位置表示(位置嵌入并且它是排列不变量)[10,11]。
In this research, the variant of the transformer called Vision Transformer (ViT) [11] which was made specifically for images, has been adapted to emotion detection in EEGs. The reason for choosing ViT is to employ time-frequency images as generated by wavelet transforms, which takes into account, the localized variations in frequency. However direct application of ViT on the raw EEG signal gave a significant improvement in accuracy as evident from the results when compared to time-frequency images. This clearly shows two aspects 1) the significance of attention mechanism for EEG signals and 2) the need of a proper encoding scheme. To the best of our knowledge, this is the first attempt of employing ViT for EEG signal analysis and also the first effort towards identifying the significance of attention in EEG signals. One of the biggest advantages of the simple setup of ViT is that they are scalable and efficient.
在本研究中,专为图像设计的Transformers 的变体Vision transformer (ViT)[11]已被应用于脑电图的情感检测。选择ViT的原因是使用小波变换生成的时频图像,考虑到频率的局部变化。然而,与时频图像相比,直接在原始EEG信号上应用ViT可以显著提高准确性。这清楚地说明了两个方面:1)注意机制对脑电信号的重要性;2)合适的编码方案的必要性。据我们所知,这是第一次尝试将ViT用于EEG信号分析,也是第一次尝试识别EEG信号中注意的重要性。简单设置ViT的最大优点之一是它们是可扩展的和高效的。
2.提出的方法
this section, the proposed approach of ViT for CWT images and the raw EEG signal is explained in detail.
在本节中,详细解释了针对CWT图像和原始EEG信号的ViT方法。
A.模型体系结构
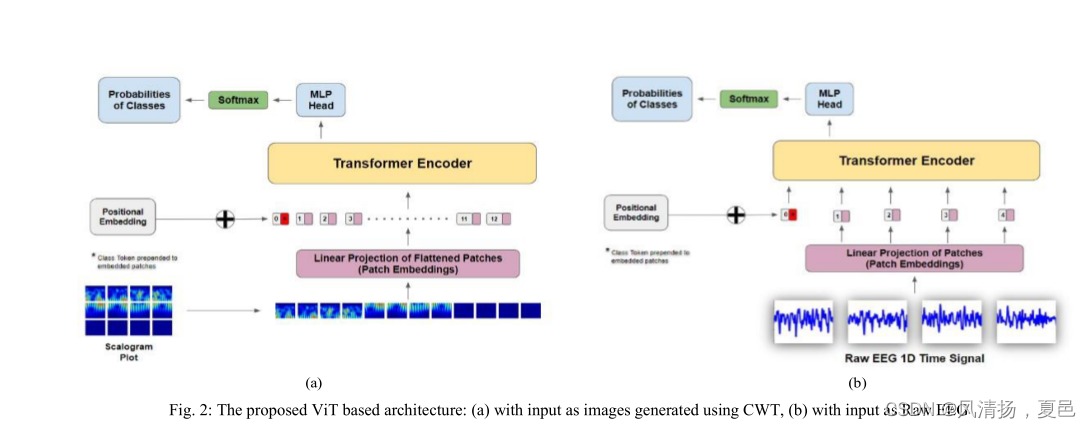
The architecture for ViT [11] closely resembles that of the vanilla transformer [10]. NLP transformers have token embeddings, meaning that it receives 1D input with a known dictionary size as input. However, for 2D input as in the case of ViT, the image is divided into a sequence of flattened 2D fixed size image patches which act as tokens. Therefore, an image of size x ∈ RH×W×C is divided into sequences of patches of size x ∈ RN×(P2×C) where N = HW/P2 and P is the selected patch size. Finally, before passing the obtained patches to the transformer it is passed through a trainable linear projection layer as in (1) [11] for getting the final patch embeddings(z0). ViT uses these patch embeddings so that there is no constraint of a certain vocab like in NLP transformers.
ViT[11]的体系结构与普通transformer[10]非常相似。NLP transformers具有令牌嵌入,这意味着它接收具有已知的作为输入的字典大小的一维输入。然而,对于像ViT一样的二维输入,图像被分成一系列扁平的二维固定大小的图像补丁,作为标记。因此,一幅大小为x∈RH × W × C的图像被划分为大小为x∈RN × ( P2 × C )的图像块序列,其中N = HW / P2,P为选择的补丁大小。最后,在将得到的补丁传递给变压器之前,像( 1 ) [ 11 ]一样通过一个可训练的线性投影层得到最终的补丁嵌入( z0 )。ViT使用这些补丁嵌入使得NLP变压器中不存在某种vocab的约束。
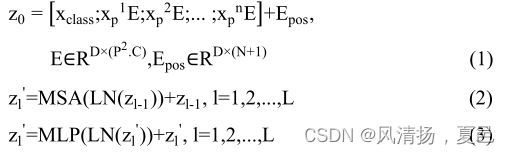
Similar to Bidirectional Encoder Representations from Transformers (BERT) [14] architecture, a learnable class token embedding is prepended to the patch embeddings.Positional embeddings(Epos) are also added to these patch embeddings for introducing positional information of the tokens in the sequence. The transformer model contains alternating layers of Multiheaded Self-Attention (MSA) and MLP (2 layers with Gaussian Error Linear Unit (GELU) nonlinearity) blocks (as in (2), (3)) with a layer normalization(LN) before every block and residual connections after every block [15, 16].
类似于来自Transformers 的双向编码器表示(BERT)[14]架构,一个可学习的类令牌嵌入在补丁嵌入之前。位置嵌入(Epos)也被添加到这些补丁嵌入中,用于引入序列中标记的位置信息。变压器模型包含多头自注意(MSA)和MLP(2层高斯误差线性单元(GELU)非线性)块(如(2),(3))的交替层,每个块之前有层归一化(LN),每个块之后有剩余连接[15,16]。
B.特征提取
In the proposed ViT based EEG classifier network, the input data to the ViT is considered in 2 ways i.e., raw EEG signal and the image generated through CWT. The architecture of the proposed approach is as shown in Figures 2a and 2b.The application of Wavelet transforms in EEG has been very popular due to their compression and time-frequency localization capabilities [17]. The choice of mother wavelet used is an important aspect based on its compatibility with the time signal. As studied in [17] EEG signals are most compatible with near symmetric and orthogonal mother wavelets like sym24, db4, coif5. In this research work db4 and coif5 mother wavelets have been employed for generating the images to be employed as the input to the ViT. As part of the ablation, experiments other compressed representations such as auto encoder [8] have been tried instead of the CWT based images, however the results were not encouraging.
在本文提出的基于ViT的脑电信号分类器网络中,将输入到ViT的数据分为两种方式,即原始脑电信号和CWT生成的图像。所提出方法的体系结构如图2a和2b所示。小波变换由于其压缩能力和时频定位能力在脑电中的应用已经非常普遍[17]。母小波的选择是基于母小波与时间信号的兼容性的一个重要方面。如文献[17]所述,脑电图信号与sym24、db4、coif5等近对称正交母小波最兼容。在本研究中,db4和coif5母小波用于生成图像,作为ViT的输入。作为消融的一部分,已经尝试了其他压缩表示(如自动编码器[8])来代替基于CWT的图像,但是结果并不令人满意。
3.结果与分析
In this section, the details of the dataset employed for the analysis of the proposed approaches and also the analysis results are presented.
在本节中,介绍了用于分析所提出方法的数据集的详细信息以及分析结果。
A.数据集描述
The proposed method was validated with the widely used DEAP [2] dataset. In this dataset EEG and peripheral physiological signals of 32 participants were recorded. Each participant in this dataset watched 40 one-minute music videos and simultaneously their EEG recordings were taken at a sampling rate of 512 Hz with 32 channels which was later down sampled to 128 Hz and band pass filtered to 4 – 45 Hz.Each video was rated by the participants on the basis of mainly valence, arousal, liking and dominance in a range of 1-9. With the DEAP dataset, many classes can be extracted from labels by dividing them equally. In the proposed work, two class labels for valence and arousal are adopted.
使用广泛使用的DEAP[2]数据集对该方法进行了验证。在该数据集中记录了32名参与者的脑电图和外周生理信号。该数据集的每个参与者观看了40个一分钟的音乐视频,同时他们的脑电图记录以512 Hz的采样率和32个通道进行采集,随后采样降到128 Hz,带通滤波到4 - 45 Hz。参与者主要根据效价、唤醒度、喜欢度和支配度对每个视频进行评分,评分范围在1-9之间。使用DEAP数据集,可以通过等分标签来提取许多类。本研究采用了效价和唤醒两类标签。
B.训练
The 60 second recording of each video was broken down into non-overlapping smaller n-sized samples (n = 6, 15, 20, 30 in seconds) respectively as responses like emotion develop over a few seconds of time period and thus breaking down the video into these sizes would help us to focus on each emotion development properly. The dataset with the above sized samples with all the 32 channels was fed to the ViT model and trained through the following two ways, which can be seen in the Fig 2.
每个视频的60秒记录被分解为不重叠的较小的n个样本(n = 6,15,20,30秒),分别作为几秒钟内情绪发展的反应,因此将视频分解为这些大小将有助于我们正确地关注每种情绪发展。将上述32个通道样本大小的数据集输入到ViT模型中,通过以下两种方式进行训练,如图2所示。
Image generated through CWT: The n-sized 32 channel sample was transformed using CWT with 48 scales and employing db4 and coif5 mother wavelets. The scalogram images generated as part of the 48 scale CWT are then fed to the ViT, in which patch embedding, with a shape of [patchsize, patchsize] is applied to it. The flattened patches are mapped to D dimensions with a trainable linear projection layer (as in (1)). Now, a class token is prepended to the output received from the trainable linear projection layer. Finally, positional embeddings are added to the patch embeddings and it is transferred to the transformer encoder.
• 通过CWT生成图像:使用48个尺度的CWT,采用db4和coif5母小波对n个大小的32通道样本进行变换。然后将作为48尺度CWT的一部分生成的尺度图图像馈送到ViT,其中对其应用形状为[patchsize, patchsize]的补丁嵌入。通过可训练的线性投影层,将平整的斑块映射到D维(如(1)所示)。现在,在从可训练线性投影层接收到的输出中添加一个类标记。最后,将位置嵌入添加到贴片嵌入中,并将其传输到变压器编码器中。
Raw EEG Signal: In this case, instead of any transformation or encoding, the raw 32 channel EEG signal (preprocessed with the 4 – 45 Hz bandpass filters as part of the DEAP dataset) is directly sent to the ViT, as shown in Fig. 2b. Since the raw EEG signal is a 1D time signal, the patch embedding is applied with a shape of [1, patchsize]. Also, as the patches are already flattened in this case, they are directly mapped to D dimensions with a trainable linear projection. Similarly, a class token is prepended to it followed by the addition of positional embeddings and finally transferring to the transformer encoder.
• 原始EEG信号:在这种情况下,代替任何转换或编码,原始32通道EEG信号(预处理与4 - 45赫兹带通滤波器作为DEAP数据集的一部分)被直接发送到ViT,如图2b所示。由于原始EEG信号是一维时间信号,因此采用形状为[1,patchsize]的patch嵌入。此外,由于在这种情况下补丁已经被展平,它们直接被映射到D维度,具有可训练的线性投影。类似地,在它前面加上一个类标记,然后添加位置嵌入,最后转移到转换器编码器。
The output from the transformer encoder, in both the CWT images and raw EEG signal-based models, is passed through a MLP head layer where it is mapped to the number of classes.Then a SoftMax layer followed by an ArgMax layer is applied for the getting the class with maximum probability. A 6layered transformer with an embedding dimension of 512 and 8 heads for MSA was used for training. As compared to its counterparts in NLP, the size and memory usage of this transformer is 2-3x times smaller which results in faster training and testing time [11]. In this work, the implementation was done on Python 3.7.10 and TensorFlow 2.5.0. The learning rate is set as 0.00001.
在CWT图像和基于原始EEG信号的模型中,变压器编码器的输出通过MLP头层传递,并映射到类的数量。然后一个SoftMax层接着一个ArgMax层被应用于获得类的最大概率。训练使用6层变压器,嵌入尺寸512,8个磁头用于MSA。与NLP中的同类方法相比,该转换器的大小和内存使用比NLP小2-3倍,从而使训练和测试时间更快[11]。在这项工作中,实现是在Python 3.7.10和TensorFlow 2.5.0上完成的。学习率设置为0.00001。
C.结果
As discussed in section III.A, to verify the effectiveness of the proposed approaches, experiments were carried out on the publicly available DEAP dataset [2]. The dataset was divided,such that 80% of the data went to the training set and the remaining 20% to testing set.
如第三节所述。A,为了验证所提出方法的有效性,在公开可用的DEAP数据集上进行了实验[2]。数据集被分割成这样,80%的数据进入训练集,剩下的20%进入测试集。
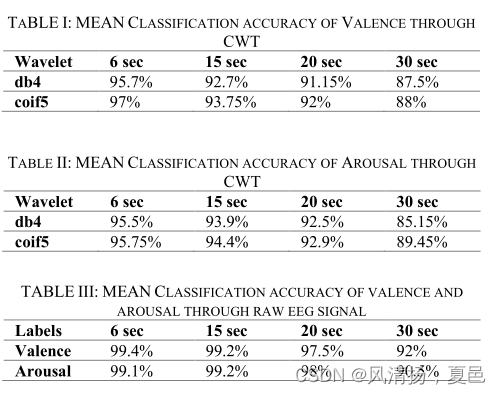
Image generated through CWT: The results of the Images generated through CWT can be seen in Table I and II. As shown, the scalograms formed by the 6 second sized samples performed significantly better than the 15, 20 and 30 second sized samples. This clearly shows the significant localized behavior of the EEG signals and the importance of a model which can take localized regions of EEG for further processing.
• CWT生成的图像:CWT生成的图像结果如表1和表2所示。如图所示,6秒大小的样本所形成的尺度图表现明显优于15、20和30秒大小的样本。这清楚地表明了脑电信号明显的局部化行为,以及利用脑电信号的局部化区域进行进一步处理的模型的重要性。
Raw EEG Signal: The results of the raw EEG signal experiment can be seen in Table III. In this case, as can be seen, 6 and 15 second sized samples performed significantly better than the 20 and 30 sized samples.More importantly, on comparing Tables I, II and III, it is evident that the raw EEG signal-based approach surprisingly performs much better than the CWT based approach. This could be attributed to the fact that, the EEG signals being random and the emotion content being local, a transformation of EEG signal is not needed (or need to be applied carefully) in the case when attention approaches like transformers [11] are employed. A detailed analysis of the same will be done as part of the future study.
• 原始EEG信号:原始EEG信号实验结果见表III。在这种情况下,可以看到,6和15秒大小的样本的表现明显好于20和30秒大小的样本。更重要的是,通过比较表1、表2和表3,很明显,基于原始脑电图信号的方法比基于CWT的方法表现得好得多。这可能是由于脑电图信号是随机的,情绪内容是局部的,在使用变压器等注意方法[11]时,不需要(或需要谨慎地)对脑电图信号进行变换。详细的分析将作为未来研究的一部分。
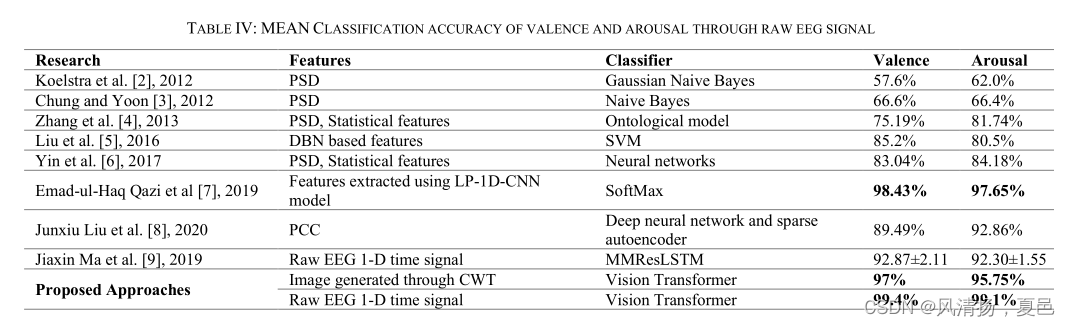
The proposed approaches are also compared in a comprehensive fashion with most of the well-established approaches in literature and the results are reported in Table IV. From Table IV, it can be seen that the proposed ViT based method outperformed all the recent-related state-of-the-art studies documented in literature. The main reason for getting good results through ViT could be attributed to the attentionbased mechanism. Through the multi-headed attention-based mechanism, the model is able to capture and remember the development of emotion through time in a much better and faster way than what CNN’s and LSTM’s or hand-crafted machine learning algorithms can do. It can also be noted that, the results presented in this work agree to the observation reported by most of the established research works related to classification of emotion through EEG signals, that the smaller sized samples perform better than the longer sized samples.
所提出的方法也与文献中大多数成熟的方法进行了全面的比较,结果见表4。从表4中可以看出,所提出的基于ViT的方法优于文献中记录的所有最新相关的最先进的研究。通过ViT获得良好效果的主要原因可归因于基于注意的机制。通过基于多头注意力的机制,该模型能够以比CNN和LSTM或手工机器学习算法更好、更快的方式捕捉和记忆情绪随时间的发展。值得注意的是,本研究的结果与大多数已建立的通过EEG信号进行情绪分类的研究工作的观察结果一致,即较小的样本比较大的样本表现得更好。
4.结论
In this paper, we investigated two experimental setups i.e., image generated through CWT and Raw Signal for EEG based emotion recognition with Vision Transformers (ViT).The ViT yielded good results with the publicly available DEAP dataset with an accuracy of 97% and 95.75% for valence and arousal in the Image Formed through CWT experiment with Coif5 mother wavelet. On the other hand, an accuracy of 99.4% and 99.1% for valence and arousal in the Raw EEG signal experiment, thereby outperforming the existing state-of-the-art methods. One of the main reasons for the exceptional performance of ViT is the attention-based mechanism, due to which it is able to capture and retain more relevant information than the conventional CNNs’ and LSTMs’. Both the experiments conducted also confirmed that smaller sized samples are more optimal for capturing the emotions, as they yield a higher classification accuracy than others. Furthermore, ViTs are more computationally faster than other neural networks for similar tasks, which makes them more suitable for real time analysis tasks. Future work involves a thorough comparison of various compression/ encoding schemes as input to ViT as well as an approach to identify the most influential EEG channels and also quantify the influence of the time-segment which resulted in the highest attention score particularly in raw EEG signal experiments.
在本文中,我们研究了两种实验设置,即通过CWT和原始信号生成图像,用于基于脑电的视觉变形(ViT)情感识别。利用Coif5母小波CWT实验生成的图像,ViT在公开的DEAP数据集上取得了较好的结果,其效价和唤醒的准确率分别为97%和95.75%。另一方面,在原始EEG信号实验中,效价和唤醒的准确率分别达到99.4%和99.1%,优于现有的最先进的方法。ViT性能优异的主要原因之一是基于注意的机制,因此它比传统的cnn和lstm能够捕获和保留更多的相关信息。进行的两个实验也证实,较小的样本更适合捕捉情绪,因为它们的分类准确率高于其他的方法。此外,vit在处理类似任务时比其他神经网络的计算速度更快,这使得它更适合于实时分析任务。未来的工作包括全面比较作为ViT输入的各种压缩/编码方案,以及确定最具影响力的EEG通道的方法,并量化导致最高注意力得分的时间段的影响,特别是在原始EEG信号实验中。















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









