







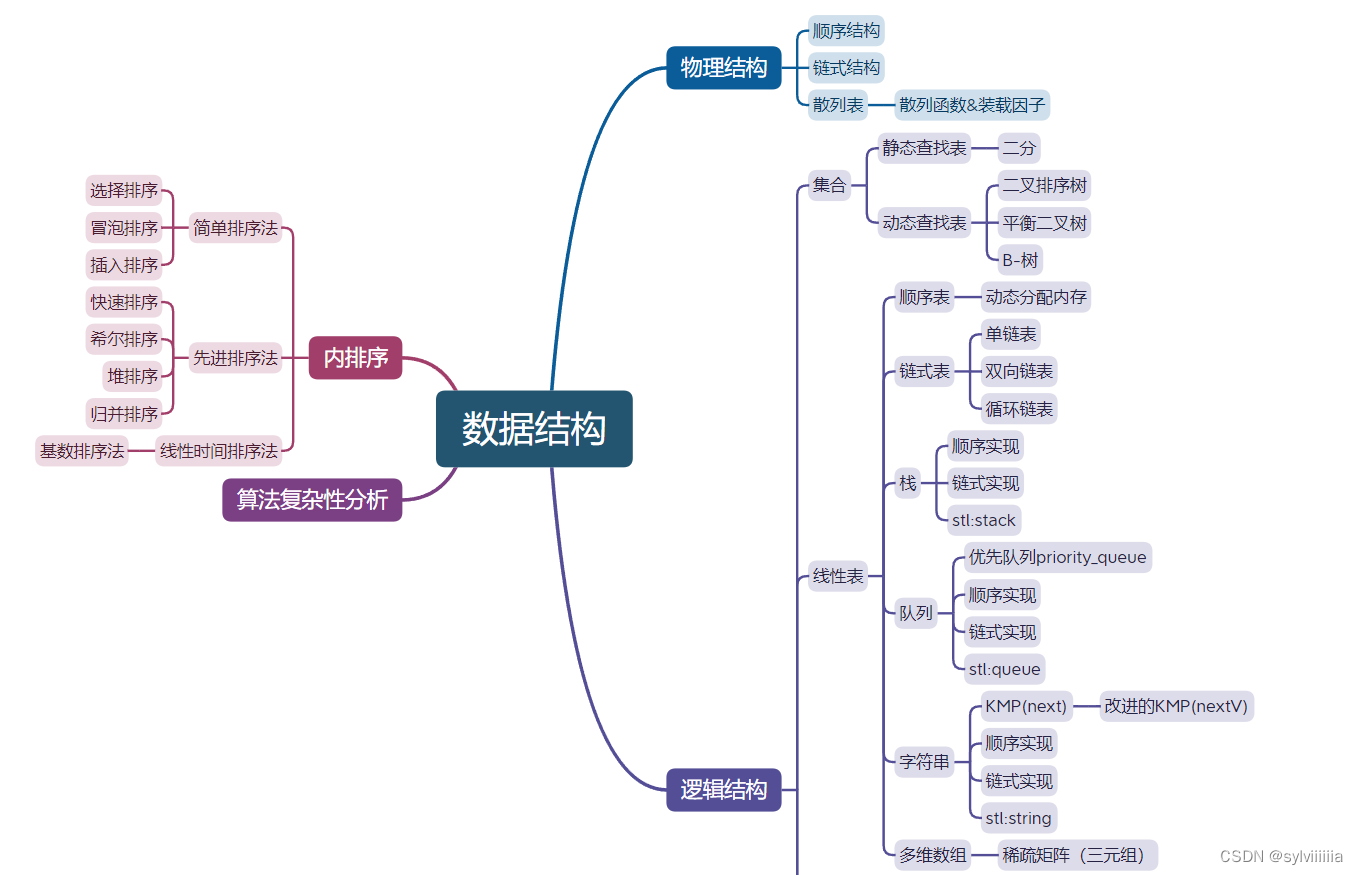
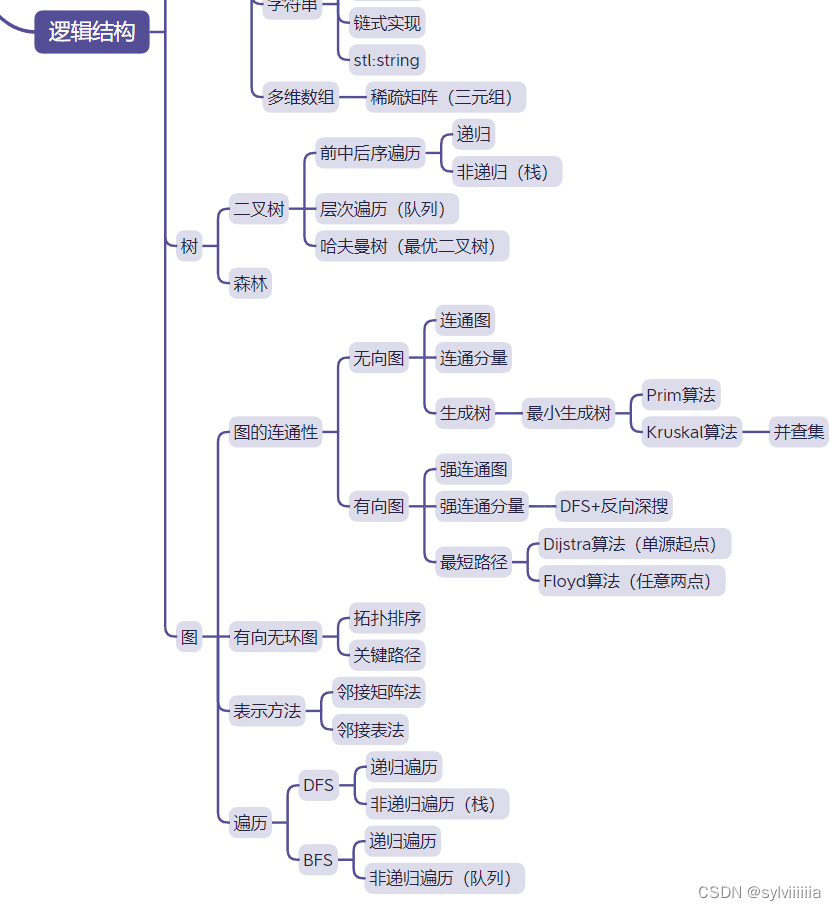
思维导图
线性表
顺序结构
结构体:Books: {struct *data; int bufferlen; int tablelen; }
初始化:动态分配数据内存data=new struct[n]
销毁:delete[]data
改/查:data[i]
增:检查参数是否合理->是否有空余空间->将插入位置之后的所有元素后移一格,将待插入元素插入
删:检查参数是否合理->将待删除元素之后的所有元素前移一格
stl: vector

链式结构
结构体:BookNode: {Book data; BookNode* next;}
初始化:创建头结点(new BookNode)->头结点指针置空。有两种头结点:数据域空/不空
销毁:沿指针方向遍历删除所有结点
增:检查参数是否合理->创建新结点->将新结点的指针指向上一结点指向的结点->将上一结点指针指向新结点
删:检查参数是否合理->创建新结点指向待删除结点->将待删除结点的上一结点指向待删除结点指向的结点->删除新结点
改/查:沿指针遍历
stl: list

循环链表:尾指针指向头结点

双向链表:LinkNode *pre, *next

静态链表:

栈
先进后出
顺序结构实现的栈

结构体:{int *datas; int bufferlen; int top;}
初始化:动态分配内存
销毁:delete
判断栈空:top==0
取栈顶元素(但不出栈):datas[top-1]
出栈:判断栈空->top–
入栈:判断栈满->datas[top++]=data
链式结构实现的栈
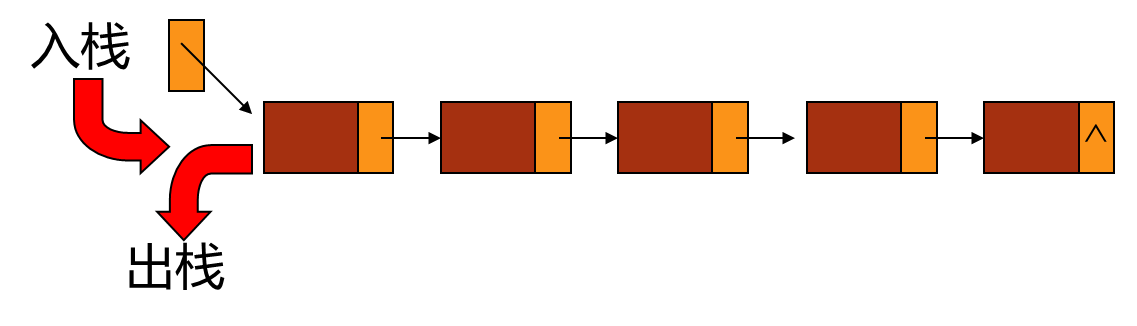
结构体:{int data; StackNode *next;}
初始化:头结点置空(栈的头结点非空)
销毁:不断取栈顶元素
判断栈空:S==NULL
取栈顶元素(但不出栈):S->data
出栈:判断栈空->暂存栈顶元素->将将栈的头结点定义为栈的头结点指向的结点->删除原栈顶元素
入栈:新建结点存放数据,将该节点指向栈的头结点,将栈的头结点定义为该新结点
stl: stack
考题
括号匹配问题、进制转换问题
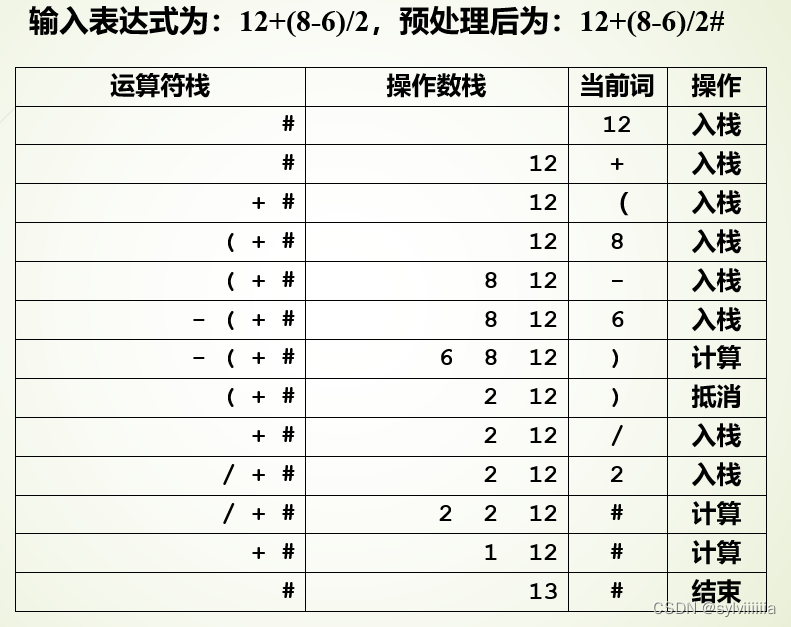
四则运算表达式
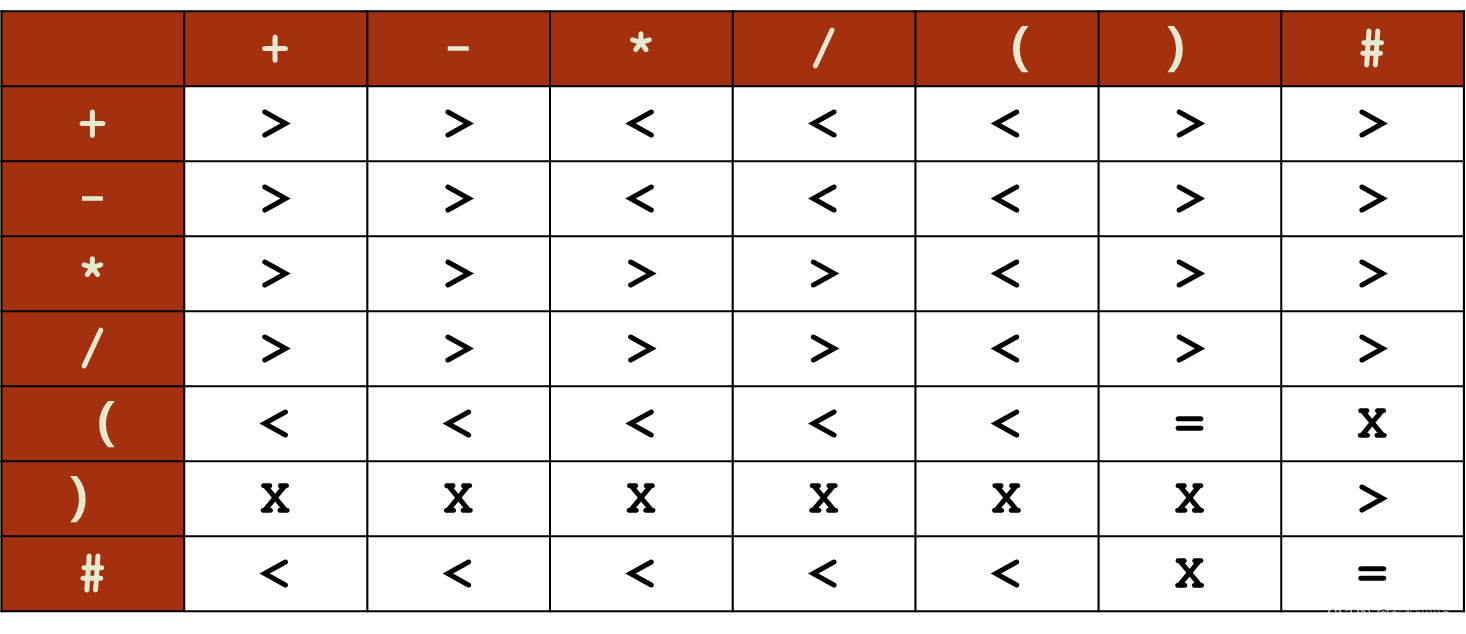
左侧一列为栈顶运算符,顶部一列为当前读入运算符,符号表示栈顶运算符>或=或<或x(不能比较)当前运算符

汉诺塔问题
队列
先进先出
顺序结构实现的队列
循环队列
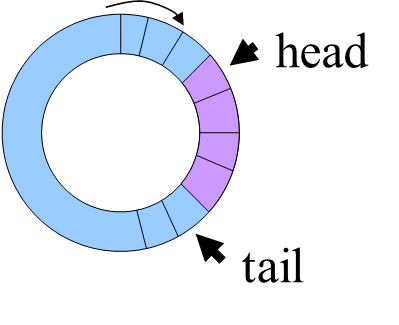
结构体: {int *datas; int bufferlen; int head,tail;}
初始化:动态分配内存
销毁:delete
判断队列空:head==tail
判断队列满:(tail+1)%bufferlen ==head
取队首元素:datas[head]
入队:判断队满->datas[tail]=data->tail=(tail+1)%bufferlen
出队:判断队空->head=(head+1)%bufferlen
链式结构实现的队列

结构体:QueueNode : {int data; QueueNode *next;} Queue{QueueNode *head,*tail;}
初始化:head=tail=NULL
销毁:不断出队
判断队空:head==NULL
取队首元素:head->data
入队:创建新结点->如果队尾为空,head=tail=p;如果队尾不空,尾结点指向p,p是新的尾结点
出队:判断队空->暂存队首结点->队首指向第二结点->删除队首结点
stl: queue
优先队列
stl:priority_queue
字符串
暴力算法
j回到0,i回到原来的i+1
字符串模式匹配算法(KMP)



多维数组
结构体:{int *buffer, * dimlength, partlength; int dims;}
初始化:可变长度参数传递
设置数据:datapartlength
稀疏矩阵:三元组
结构体:TriNode:{int r,c; int data;} Tritable:{TriNode *data;int *rpos; int mu,nu,tu;}
创建
销毁
打印
行向量指导矩阵转置
计算rsum,rpos(对转置前的矩阵应计算每列非零元个数作为转置后矩阵的行向量)
树
二叉树

二叉链结构
结构体:BiNode:{string data;BiNode *lchild, *rchild;}
初始化:置空
销毁:递归销毁
计算深度:递归
计算结点数:递归
创建二叉树:输入带有虚结点的字符串
前中后序遍历(递归)
前中后序遍历(非递归:栈)


层次遍历(队列)

前序+中序唯一确定二叉树
二叉树的同构判定
哈夫曼树(最优二叉树)
使用数组记录
图
邻接矩阵
结构体:Graph{int vexNumber; int info[n]; int adjMatrix[n][n];}
邻接表
结构体:ArcNode{int weight,adj; ArcNode *next;}
VexNode{int info;ArcNode *firstarc;}
LinkGraph{VexNode *vexes;int vexNumber;}
初始化:动态分配内存 vexes键入数据,指针全部置零
销毁:vexes顺着指针销毁
DFS
递归算法


非递归算法(思路同二叉树的前序遍历:栈)

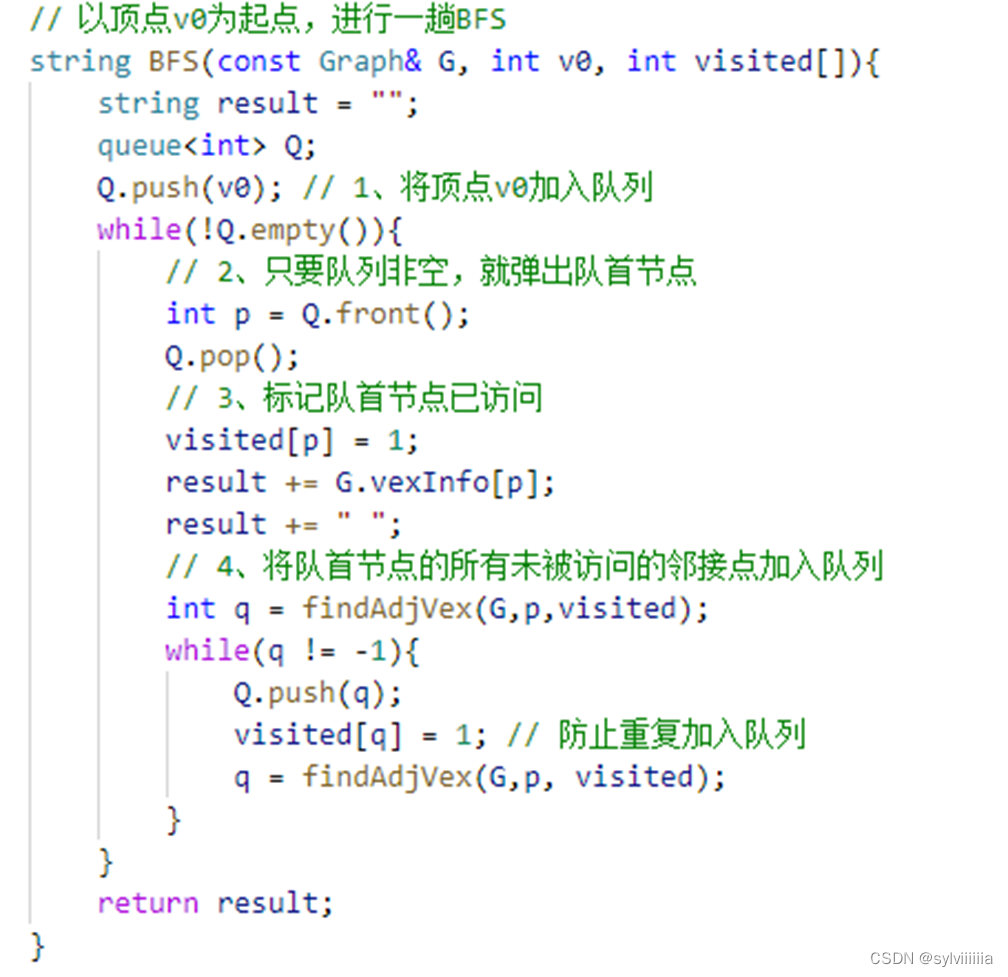
BFS(队列)

图的连通性
无向图的连通分量
一趟BFS或DFS
最小生成树
原图的极小连通子图,包含原图中所有n个结点,并且有保持图连通的最少的边,边的权重之和最小
Prim算法:选择权重最小的边加入结果树,将结点并入U集中

Kruskal算法:将边按权值排序,不在同一点集中的顶点可以合并并保留该边
(如何判断两顶点是否在同一点集中:并查集)
有向图的强连通分量
DFS,记算遍历结束序,记入finished数组中->逆向深度优先遍历,每趟是一个强连通分量
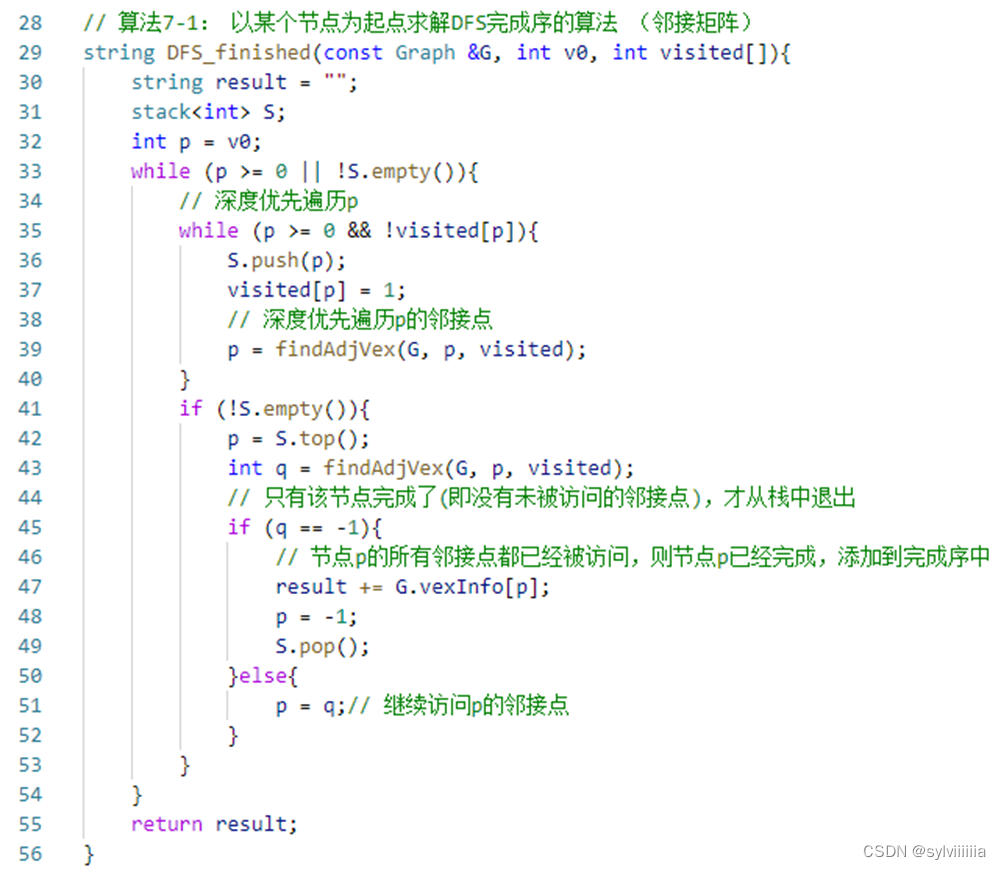
最短路径
Dijstra算法(单源起点)


Floyd算法(任意两点之间)

有向无环图
拓扑排序
关键路径
集合
静态查找表
二分
动态查找表
二叉排序树
查找:小于查左子,大于查右子
插:小于往左插,大于往右插
删:从左子树找最小的替换/从右子树找最大的替换
平衡二叉树
平衡因子<=1

B-树
多路平衡查找树
结构体:BTreeNode{int n;bool isLeaf; int keys[n]; BTreeNode *children[n];}
BTree{BTreeNode *root;int degree;}
查找
增:插入->分裂调整
删:删除->合并调整
哈希表

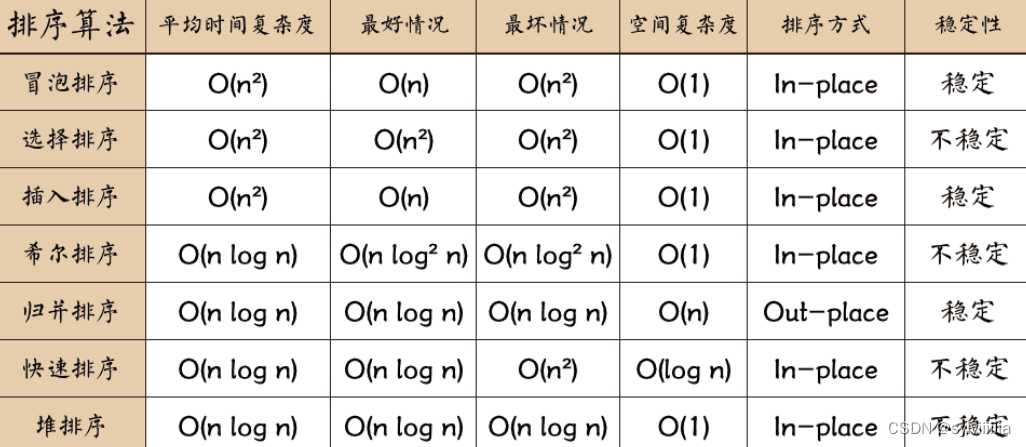
内排序
选择排序法
冒泡排序法
插入排序法
希尔排序法
快速排序法
堆排序法:升序用大顶堆,降序用小顶堆
建堆(从最后一个非叶结点开始调整)->大顶堆和最后一个叶子交换->堆调整
归并排序法稳定
多关键字排序法















 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









